 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Student Performance Prediction on Learnersourced Questions with SGNN-LLM Synergy
Sep 23, 2023As an emerging education strategy, learnersourcing offers the potential for personalized learning content creation, but also grapples with the challenge of predicting student performance due to inherent noise in student-generated data. While graph-based methods excel in capturing dense learner-question interactions, they falter in cold start scenarios, characterized by limited interactions, as seen when questions lack substantial learner responses. In response, we introduce an innovative strategy that synergizes the potential of integrating Signed Graph Neural Networks (SGNNs) and Large Language Model (LLM) embeddings. Our methodology employs a signed bipartite graph to comprehensively model student answers, complemented by a contrastive learning framework that enhances noise resilience. Furthermore, LLM's contribution lies in generating foundational question embeddings, proving especially advantageous in addressing cold start scenarios characterized by limited graph data interactions. Validation across five real-world datasets sourced from the PeerWise platform underscores our approach's effectiveness. Our method outperforms baselines, showcasing enhanced predictive accuracy and robustness.
DeepQR: Neural-based Quality Ratings for Learnersourced Multiple-Choice Questions
Nov 19, 2021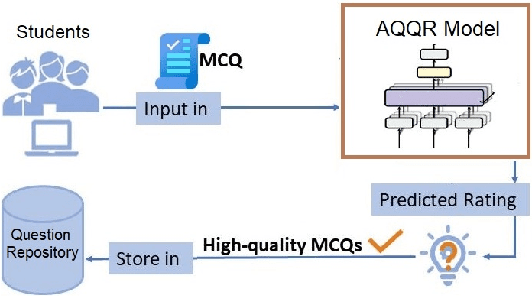
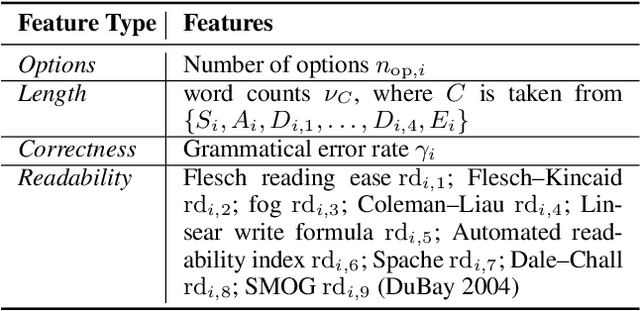
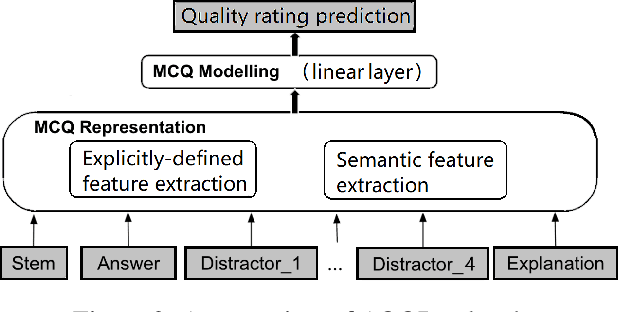
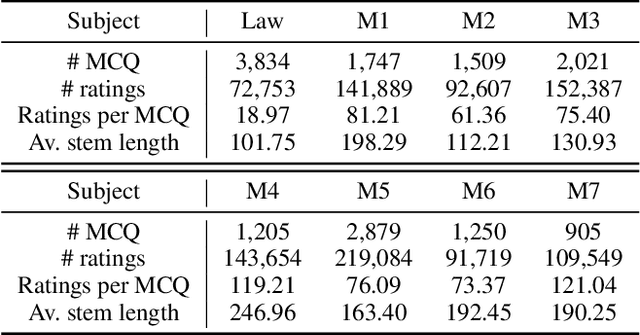
Automated question quality rating (AQQR) aims to evaluate question quality through computational means, thereby addressing emerging challenges in online learnersourced question repositories. Existing methods for AQQR rely solely on explicitly-defined criteria such as readability and word count, while not fully utilising the power of state-of-the-art deep-learning techniques. We propose DeepQR, a novel neural-network model for AQQR that is trained using multiple-choice-question (MCQ) datasets collected from PeerWise, a widely-used learnersourcing platform. Along with designing DeepQR, we investigate models based on explicitly-defined features, or semantic features, or both. We also introduce a self-attention mechanism to capture semantic correlations between MCQ components, and a contrastive-learning approach to acquire question representations using quality ratings. Extensive experiments on datasets collected from eight university-level courses illustrate that DeepQR has superior performance over six comparative models.
HHH: An Online Medical Chatbot System based on Knowledge Graph and Hierarchical Bi-Directional Attention
Feb 08, 2020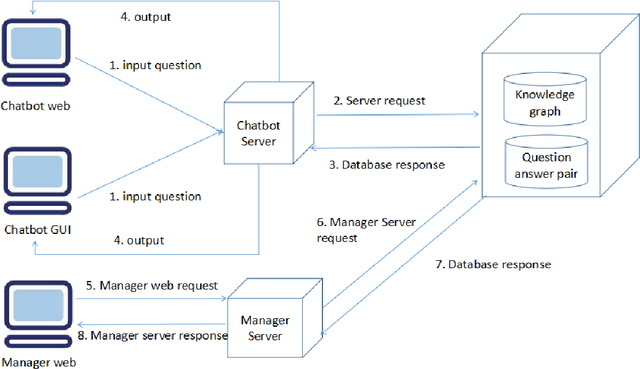

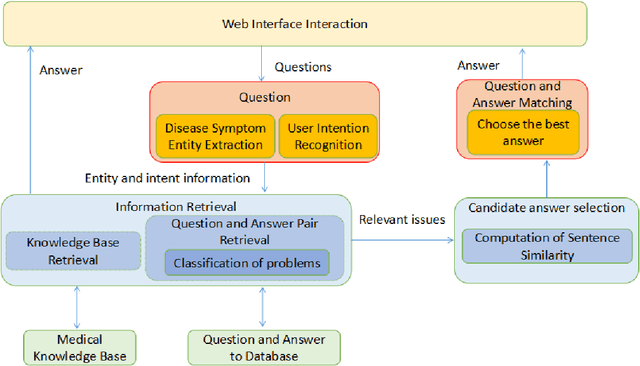
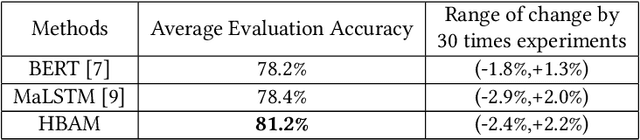
This paper proposes a chatbot framework that adopts a hybrid model which consists of a knowledge graph and a text similarity model. Based on this chatbot framework, we build HHH, an online question-and-answer (QA) Healthcare Helper system for answering complex medical questions. HHH maintains a knowledge graph constructed from medical data collected from the Internet. HHH also implements a novel text representation and similarity deep learning model, Hierarchical BiLSTM Attention Model (HBAM), to find the most similar question from a large QA dataset. We compare HBAM with other state-of-the-art language models such as bidirectional encoder representation from transformers (BERT) and Manhattan LSTM Model (MaLSTM). We train and test the models with a subset of the Quora duplicate questions dataset in the medical area. The experimental results show that our model is able to achieve a superior performance than these existing methods.