 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Multi-LLMs Collaboration for Enhanced Score-based Causal Discovery
Nov 27, 2024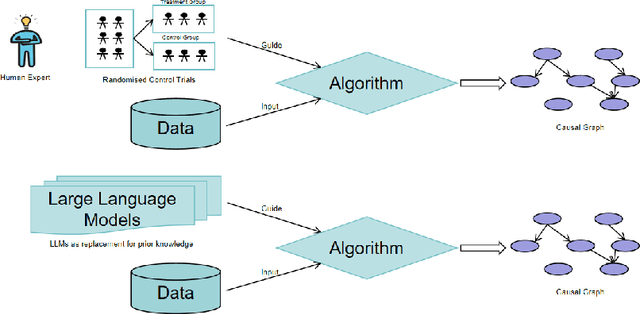

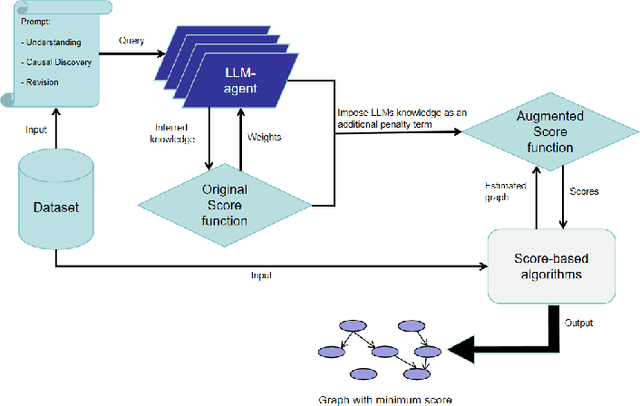
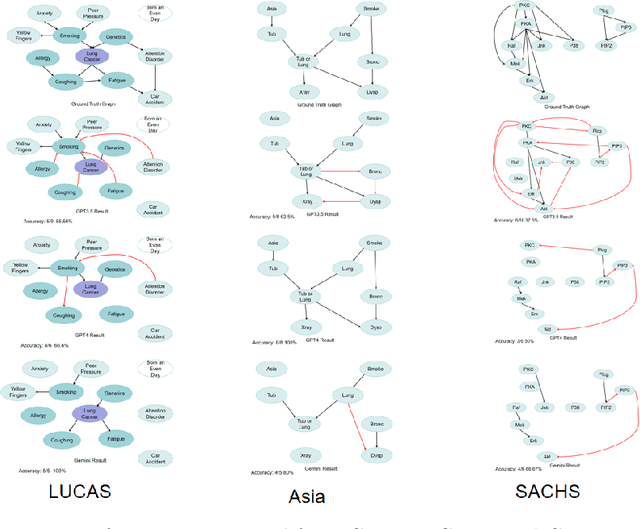
As the significance of understanding the cause-and-effect relationships among variables increases in the development of modern systems and algorithms, learning causality from observational data has become a preferred and efficient approach over conducting randomized control trials. However, purely observational data could be insufficient to reconstruct the true causal graph. Consequently, many researchers tried to utilise some form of prior knowledge to improve causal discovery process. In this context, the impressive capabilities of large language models (LLMs) have emerged as a promising alternative to the costly acquisition of prior expert knowledge. In this work, we further explore the potential of using LLMs to enhance causal discovery approaches, particularly focusing on score-based methods, and we propose a general framework to utilise the capacity of not only one but multiple LLMs to augment the discovery process.
Deconfounded Causality-aware Parameter-Efficient Fine-Tuning for Problem-Solving Improvement of LLMs
Sep 04, 2024Large Language Models (LLMs) have demonstrated remarkable efficiency in tackling various tasks based on human instructions, but recent studies reveal that these models often fail to achieve satisfactory results on questions involving reasoning, such as mathematics or physics questions. This phenomenon is usually attributed to the uncertainty regarding whether these models could genuinely comprehend the knowledge embedded in the text or merely learn to replicate the token distribution without a true understanding of the content. In this paper, we delve into this problem and aim to enhance the reasoning capabilities of LLMs. First, we investigate if the model has genuine reasoning capabilities by visualizing the text generation process at the attention and representation level. Then, we formulate the reasoning process of LLMs into a causal framework, which provides a formal explanation of the problems we observe in the visualization. Finally, building upon this causal framework, we propose Deconfounded Causal Adaptation (DCA), a novel parameter-efficient fine-tuning (PEFT) method to enhance the model's reasoning capabilities by encouraging the model to extract the general problem-solving skills and apply these skills to different questions. Experiments show that our method outperforms the baseline consistently across multiple benchmarks, and with only 1.2M tunable parameters, we achieve better or comparable results to other fine-tuning methods. This demonstrates the effectiveness and efficiency of our method in improving the overall accuracy and reliability of LLMs.
Enhancing Student Performance Prediction on Learnersourced Questions with SGNN-LLM Synergy
Sep 23, 2023As an emerging education strategy, learnersourcing offers the potential for personalized learning content creation, but also grapples with the challenge of predicting student performance due to inherent noise in student-generated data. While graph-based methods excel in capturing dense learner-question interactions, they falter in cold start scenarios, characterized by limited interactions, as seen when questions lack substantial learner responses. In response, we introduce an innovative strategy that synergizes the potential of integrating Signed Graph Neural Networks (SGNNs) and Large Language Model (LLM) embeddings. Our methodology employs a signed bipartite graph to comprehensively model student answers, complemented by a contrastive learning framework that enhances noise resilience. Furthermore, LLM's contribution lies in generating foundational question embeddings, proving especially advantageous in addressing cold start scenarios characterized by limited graph data interactions. Validation across five real-world datasets sourced from the PeerWise platform underscores our approach's effectiveness. Our method outperforms baselines, showcasing enhanced predictive accuracy and robustness.
DeepQR: Neural-based Quality Ratings for Learnersourced Multiple-Choice Questions
Nov 19, 2021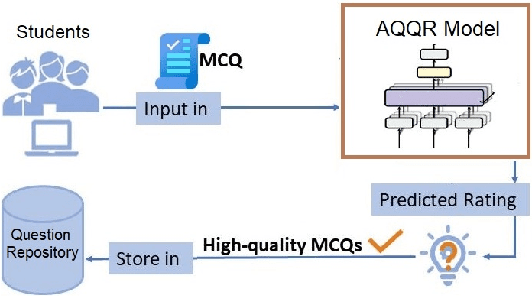
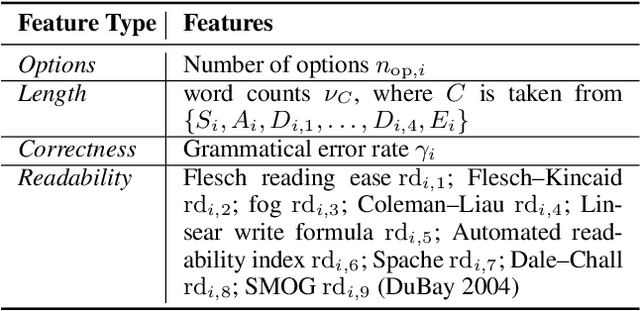
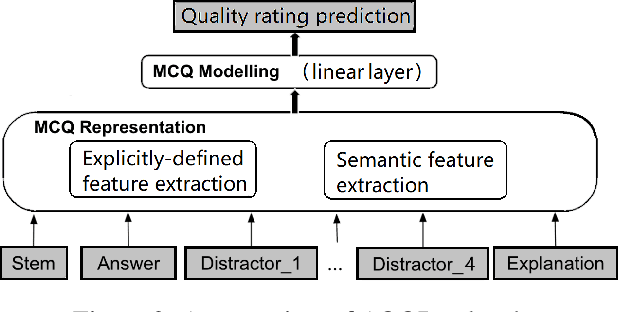
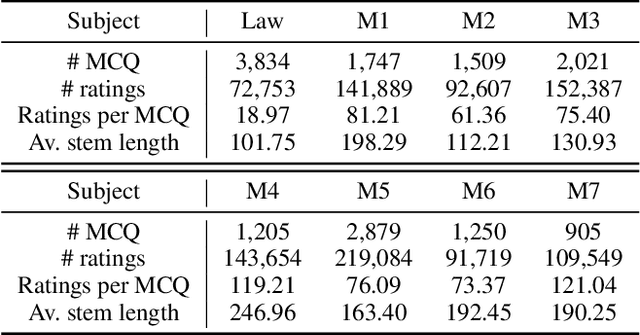
Automated question quality rating (AQQR) aims to evaluate question quality through computational means, thereby addressing emerging challenges in online learnersourced question repositories. Existing methods for AQQR rely solely on explicitly-defined criteria such as readability and word count, while not fully utilising the power of state-of-the-art deep-learning techniques. We propose DeepQR, a novel neural-network model for AQQR that is trained using multiple-choice-question (MCQ) datasets collected from PeerWise, a widely-used learnersourcing platform. Along with designing DeepQR, we investigate models based on explicitly-defined features, or semantic features, or both. We also introduce a self-attention mechanism to capture semantic correlations between MCQ components, and a contrastive-learning approach to acquire question representations using quality ratings. Extensive experiments on datasets collected from eight university-level courses illustrate that DeepQR has superior performance over six comparative models.