 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison of correspondence analysis with PMI-based word embedding methods
May 31, 2024Popular word embedding methods such as GloVe and Word2Vec are related to the factorization of the pointwise mutual information (PMI) matrix. In this paper, we link correspondence analysis (CA) to the factorization of the PMI matrix. CA is a dimensionality reduction method that uses singular value decomposition (SVD), and we show that CA is mathematically close to the weighted factorization of the PMI matrix. In addition, we present variants of CA that turn out to be successful in the factorization of the word-context matrix, i.e. CA applied to a matrix where the entries undergo a square-root transformation (ROOT-CA) and a root-root transformation (ROOTROOT-CA). An empirical comparison among CA- and PMI-based methods shows that overall results of ROOT-CA and ROOTROOT-CA are slightly better than those of the PMI-based methods.
Improving information retrieval through correspondence analysis instead of latent semantic analysis
Mar 14, 2023Both latent semantic analysis (LSA) and correspondence analysis (CA) are dimensionality reduction techniques that use singular value decomposition (SVD) for information retrieval. Theoretically, the results of LSA display both the association between documents and terms, and marginal effects; in comparison, CA only focuses on the associations between documents and terms. Marginal effects are usually not relevant for information retrieval, and therefore, from a theoretical perspective CA is more suitable for information retrieval. In this paper, we empirically compare LSA and CA. The elements of the raw document-term matrix are weighted, and the weighting exponent of singular values is adjusted to improve the performance of LSA. We explore whether these two weightings also improve the performance of CA. In addition, we compare the optimal singular value weighting exponents for LSA and CA to identify what the initial dimensions in LSA correspond to. The results for four empirical datasets show that CA always performs better than LSA. Weighting the elements of the raw data matrix can improve CA; however, it is data dependent and the improvement is small. Adjusting the singular value weighting exponent usually improves the performance of CA; however, the extent of the improved performance depends on the dataset and number of dimensions. In general, CA needs a larger singular value weighting exponent than LSA to obtain the optimal performance. This indicates that CA emphasizes initial dimensions more than LSA, and thus, margins play an important role in the initial dimensions in LSA.
A Comparison of Latent Semantic Analysis and Correspondence Analysis for Text Mining
Jul 25, 2021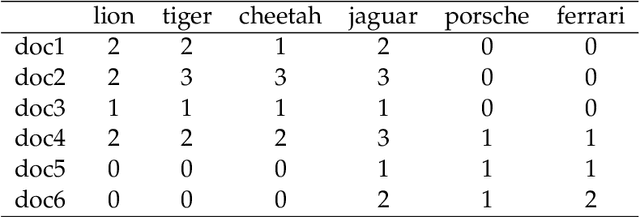
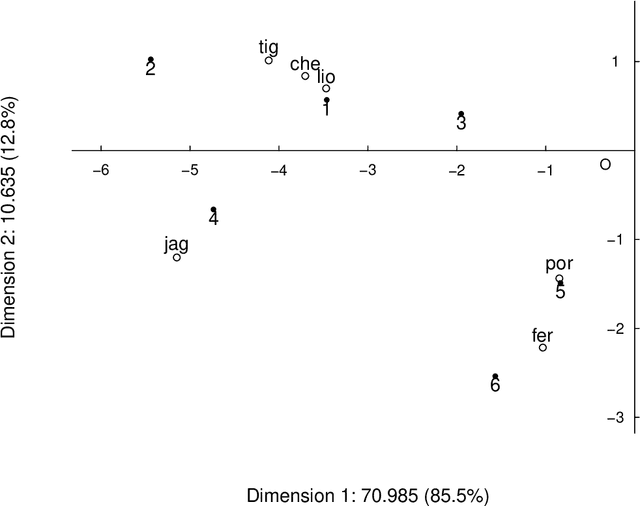
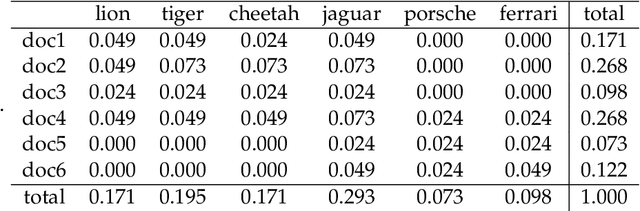
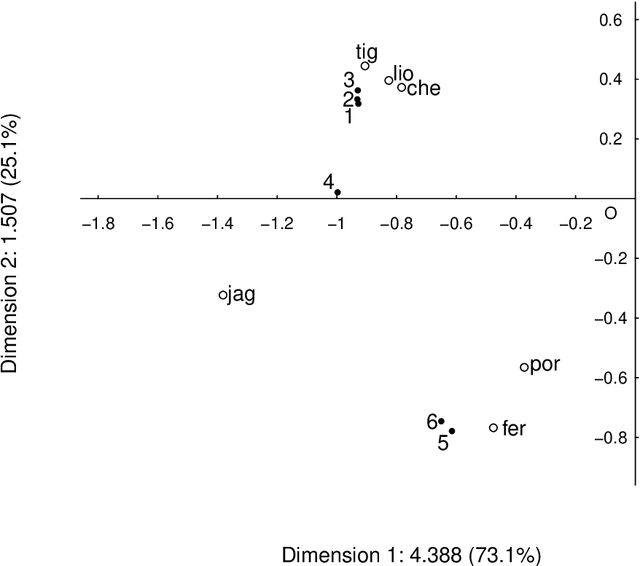
Both latent semantic analysis (LSA) and correspondence analysis (CA) use a singular value decomposition (SVD) for dimensionality reduction. In this article, LSA and CA are compared from a theoretical point of view and applied in both a toy example and an authorship attribution example. In text mining interest goes out to the relationships among documents and terms: for example, what terms are more often used in what documents. However, the LSA solution displays a mix of marginal effects and these relationships. It appears that CA has more attractive properties than LSA. One such property is that, in CA, the effect of the margins is effectively eliminated, so that the CA solution is optimally suited to focus on the relationships among documents and terms. Three mechanisms are distinguished to weight documents and terms, and a unifying framework is proposed that includes these three mechanisms and includes both CA and LSA as special cases. In the authorship attribution example, the national anthem of the Netherlands, the application of the discussed methods is illustrated.