 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Latent Semantic Analysis and Correspondence Analysis for Text Mining
Paper and Code
Jul 25, 2021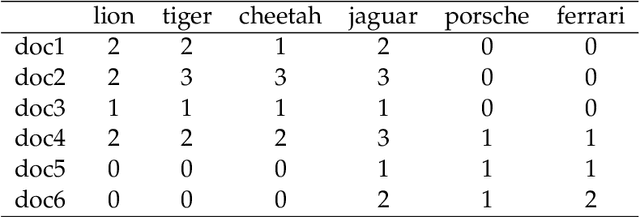
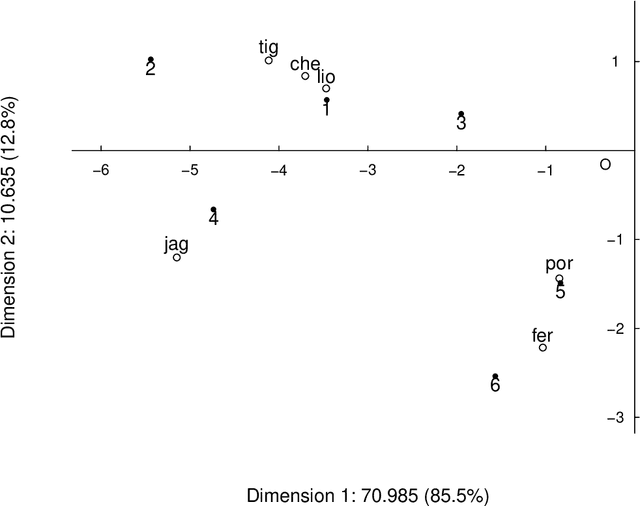
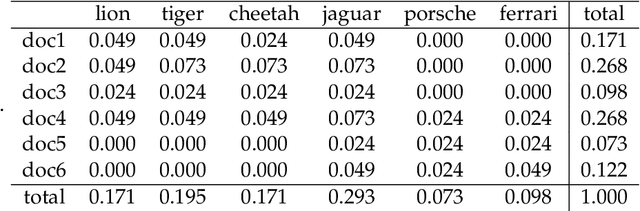
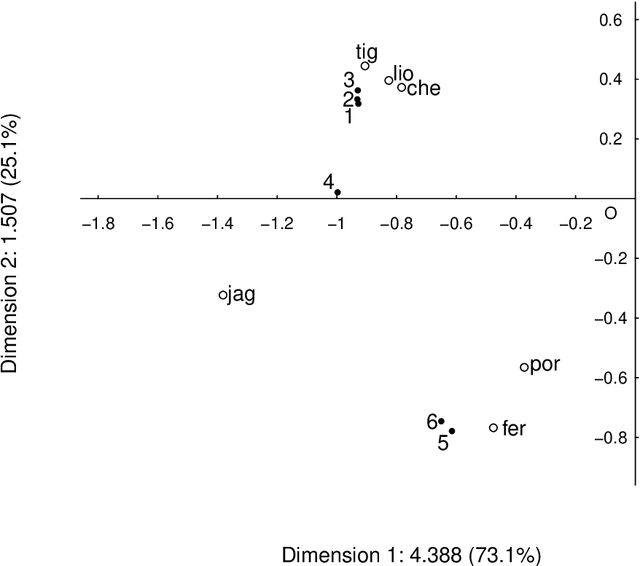
Both latent semantic analysis (LSA) and correspondence analysis (CA) use a singular value decomposition (SVD) for dimensionality reduction. In this article, LSA and CA are compared from a theoretical point of view and applied in both a toy example and an authorship attribution example. In text mining interest goes out to the relationships among documents and terms: for example, what terms are more often used in what documents. However, the LSA solution displays a mix of marginal effects and these relationships. It appears that CA has more attractive properties than LSA. One such property is that, in CA, the effect of the margins is effectively eliminated, so that the CA solution is optimally suited to focus on the relationships among documents and terms. Three mechanisms are distinguished to weight documents and terms, and a unifying framework is proposed that includes these three mechanisms and includes both CA and LSA as special cases. In the authorship attribution example, the national anthem of the Netherlands, the application of the discussed methods is illustrated.