 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Automated Verification of Textual Claims (AVeriTeC) Shared Task
Oct 31, 2024



The Automated Verification of Textual Claims (AVeriTeC) shared task asks participants to retrieve evidence and predict veracity for real-world claims checked by fact-checkers. Evidence can be found either via a search engine, or via a knowledge store provided by the organisers. Submissions are evaluated using AVeriTeC score, which considers a claim to be accurately verified if and only if both the verdict is correct and retrieved evidence is considered to meet a certain quality threshold. The shared task received 21 submissions, 18 of which surpassed our baseline. The winning team was TUDA_MAI with an AVeriTeC score of 63%. In this paper we describe the shared task, present the full results, and highlight key takeaways from the shared task.
Argumentation and Machine Learning
Oct 31, 2024This chapter provides an overview of research works that present approaches with some degree of cross-fertilisation between Computational Argumentation and Machine Learning. Our review of the literature identified two broad themes representing the purpose of the interaction between these two areas: argumentation for machine learning and machine learning for argumentation. Across these two themes, we systematically evaluate the spectrum of works across various dimensions, including the type of learning and the form of argumentation framework used. Further, we identify three types of interaction between these two areas: synergistic approaches, where the Argumentation and Machine Learning components are tightly integrated; segmented approaches, where the two are interleaved such that the outputs of one are the inputs of the other; and approximated approaches, where one component shadows the other at a chosen level of detail. We draw conclusions about the suitability of certain forms of Argumentation for supporting certain types of Machine Learning, and vice versa, with clear patterns emerging from the review. Whilst the reviewed works provide inspiration for successfully combining the two fields of research, we also identify and discuss limitations and challenges that ought to be addressed in order to ensure that they remain a fruitful pairing as AI advances.
Towards Dialogues for Joint Human-AI Reasoning and Value Alignment
May 28, 2024We argue that enabling human-AI dialogue, purposed to support joint reasoning (i.e., 'inquiry'), is important for ensuring that AI decision making is aligned with human values and preferences. In particular, we point to logic-based models of argumentation and dialogue, and suggest that the traditional focus on persuasion dialogues be replaced by a focus on inquiry dialogues, and the distinct challenges that joint inquiry raises. Given recent dramatic advances in the performance of large language models (LLMs), and the anticipated increase in their use for decision making, we provide a roadmap for research into inquiry dialogues for supporting joint human-LLM reasoning tasks that are ethically salient, and that thereby require that decisions are value aligned.
ChartCheck: An Evidence-Based Fact-Checking Dataset over Real-World Chart Images
Nov 13, 2023Data visualizations are common in the real-world. We often use them in data sources such as scientific documents, news articles, textbooks, and social media to summarize key information in a visual form. Charts can also mislead its audience by communicating false information or biasing them towards a specific agenda. Verifying claims against charts is not a straightforward process. It requires analyzing both the text and visual components of the chart, considering characteristics such as colors, positions, and orientations. Moreover, to determine if a claim is supported by the chart content often requires different types of reasoning. To address this challenge, we introduce ChartCheck, a novel dataset for fact-checking against chart images. ChartCheck is the first large-scale dataset with 1.7k real-world charts and 10.5k human-written claims and explanations. We evaluated the dataset on state-of-the-art models and achieved an accuracy of 73.9 in the finetuned setting. Additionally, we identified chart characteristics and reasoning types that challenge the models.
Exploring the Numerical Reasoning Capabilities of Language Models: A Comprehensive Analysis on Tabular Data
Nov 03, 2023Numbers are crucial for various real-world domains such as finance, economics, and science. Thus, understanding and reasoning with numbers are essential skills for language models to solve different tasks. While different numerical benchmarks have been introduced in recent years, they are limited to specific numerical aspects mostly. In this paper, we propose a hierarchical taxonomy for numerical reasoning skills with more than ten reasoning types across four levels: representation, number sense, manipulation, and complex reasoning. We conduct a comprehensive evaluation of state-of-the-art models to identify reasoning challenges specific to them. Henceforth, we develop a diverse set of numerical probes employing a semi-automated approach. We focus on the tabular Natural Language Inference (TNLI) task as a case study and measure models' performance shifts. Our results show that no model consistently excels across all numerical reasoning types. Among the probed models, FlanT5 (few-/zero-shot) and GPT-3.5 (few-shot) demonstrate strong overall numerical reasoning skills compared to other models. Label-flipping probes indicate that models often exploit dataset artifacts to predict the correct labels.
Identifying Reasons for Bias: An Argumentation-Based Approach
Oct 26, 2023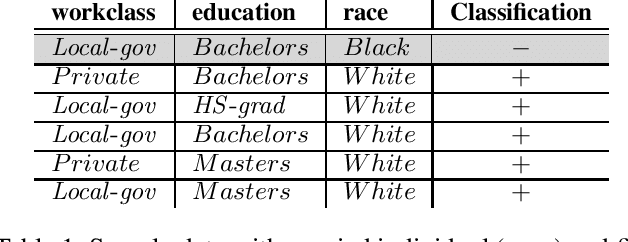

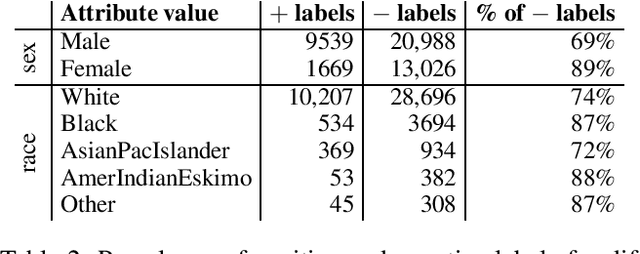
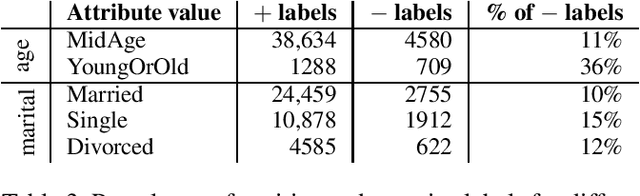
As algorithmic decision-making systems become more prevalent in society, ensuring the fairness of these systems is becoming increasingly important. Whilst there has been substantial research in building fair algorithmic decision-making systems, the majority of these methods require access to the training data, including personal characteristics, and are not transparent regarding which individuals are classified unfairly. In this paper, we propose a novel model-agnostic argumentation-based method to determine why an individual is classified differently in comparison to similar individuals. Our method uses a quantitative argumentation framework to represent attribute-value pairs of an individual and of those similar to them, and uses a well-known semantics to identify the attribute-value pairs in the individual contributing most to their different classification. We evaluate our method on two datasets commonly used in the fairness literature and illustrate its effectiveness in the identification of bias.
Bias Mitigation Methods for Binary Classification Decision-Making Systems: Survey and Recommendations
May 31, 2023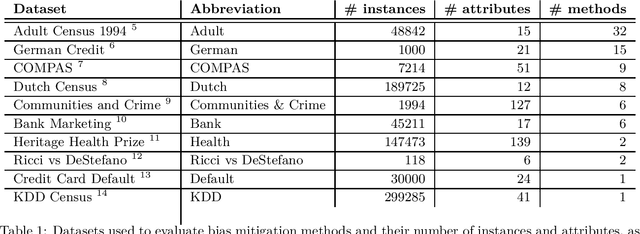
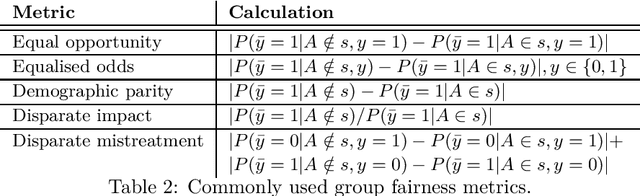
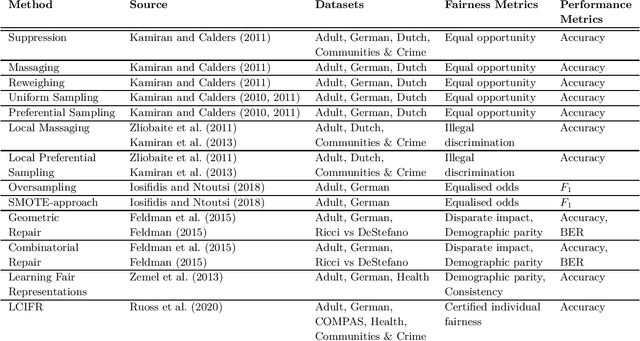
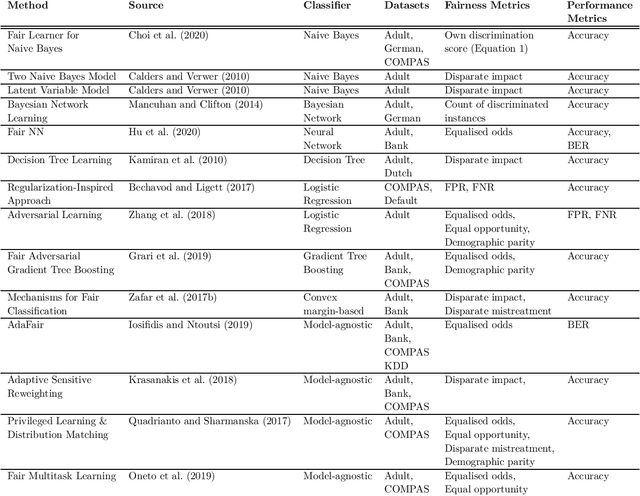
Bias mitigation methods for binary classification decision-making systems have been widely researched due to the ever-growing importance of designing fair machine learning processes that are impartial and do not discriminate against individuals or groups based on protected personal characteristics. In this paper, we present a structured overview of the research landscape for bias mitigation methods, report on their benefits and limitations, and provide recommendations for the development of future bias mitigation methods for binary classification.
Reading and Reasoning over Chart Images for Evidence-based Automated Fact-Checking
Jan 27, 2023Evidence data for automated fact-checking (AFC) can be in multiple modalities such as text, tables, images, audio, or video. While there is increasing interest in using images for AFC, previous works mostly focus on detecting manipulated or fake images. We propose a novel task, chart-based fact-checking, and introduce ChartBERT as the first model for AFC against chart evidence. ChartBERT leverages textual, structural and visual information of charts to determine the veracity of textual claims. For evaluation, we create ChartFC, a new dataset of 15, 886 charts. We systematically evaluate 75 different vision-language (VL) baselines and show that ChartBERT outperforms VL models, achieving 63.8% accuracy. Our results suggest that the task is complex yet feasible, with many challenges ahead.
FEVEROUS: Fact Extraction and VERification Over Unstructured and Structured information
Jun 10, 2021
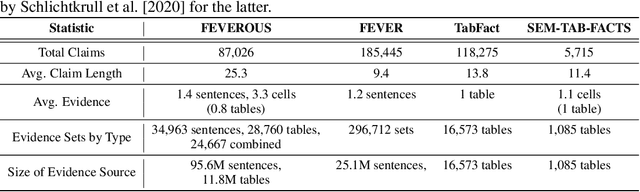
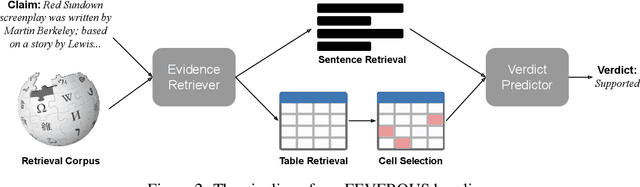
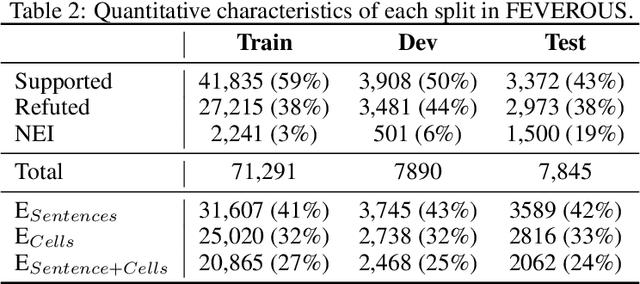
Fact verification has attracted a lot of attention in the machine learning and natural language processing communities, as it is one of the key methods for detecting misinformation. Existing large-scale benchmarks for this task have focused mostly on textual sources, i.e. unstructured information, and thus ignored the wealth of information available in structured formats, such as tables. In this paper we introduce a novel dataset and benchmark, Fact Extraction and VERification Over Unstructured and Structured information (FEVEROUS), which consists of 87,026 verified claims. Each claim is annotated with evidence in the form of sentences and/or cells from tables in Wikipedia, as well as a label indicating whether this evidence supports, refutes, or does not provide enough information to reach a verdict. Furthermore, we detail our efforts to track and minimize the biases present in the dataset and could be exploited by models, e.g. being able to predict the label without using evidence. Finally, we develop a baseline for verifying claims against text and tables which predicts both the correct evidence and verdict for 18% of the claims.
An Explanatory Query-Based Framework for Exploring Academic Expertise
May 31, 2021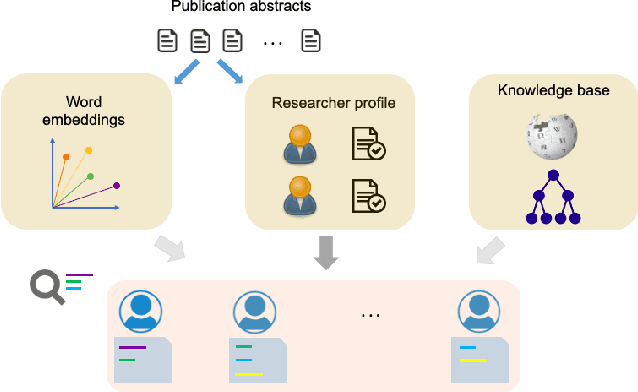



The success of research institutions heavily relies upon identifying the right researchers "for the job": researchers may need to identify appropriate collaborators, often from across disciplines; students may need to identify suitable supervisors for projects of their interest; administrators may need to match funding opportunities with relevant researchers, and so on. Usually, finding potential collaborators in institutions is a time-consuming manual search task prone to bias. In this paper, we propose a novel query-based framework for searching, scoring, and exploring research expertise automatically, based upon processing abstracts of academic publications. Given user queries in natural language, our framework finds researchers with relevant expertise, making use of domain-specific knowledge bases and word embeddings. It also generates explanations for its recommendations. We evaluate our framework with an institutional repository of papers from a leading university, using, as baselines, artificial neural networks and transformer-based models for a multilabel classification task to identify authors of publication abstracts. We also assess the cross-domain effectiveness of our framework with a (separate) research funding repository for the same institution. We show that our simple method is effective in identifying matches, while satisfying desirable properties and being efficient.