 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Mimicry: Toward Lifelong Adaptability in Imitation Learning
Feb 23, 2026Imitation learning stands at a crossroads: despite decades of progress, current imitation learning agents remain sophisticated memorisation machines, excelling at replay but failing when contexts shift or goals evolve. This paper argues that this failure is not technical but foundational: imitation learning has been optimised for the wrong objective. We propose a research agenda that redefines success from perfect replay to compositional adaptability. Such adaptability hinges on learning behavioural primitives once and recombining them through novel contexts without retraining. We establish metrics for compositional generalisation, propose hybrid architectures, and outline interdisciplinary research directions drawing on cognitive science and cultural evolution. Agents that embed adaptability at the core of imitation learning thus have an essential capability for operating in an open-ended world.
Towards Generalisable Imitation Learning Through Conditioned Transition Estimation and Online Behaviour Alignment
Jan 24, 2026State-of-the-art imitation learning from observation methods (ILfO) have recently made significant progress, but they still have some limitations: they need action-based supervised optimisation, assume that states have a single optimal action, and tend to apply teacher actions without full consideration of the actual environment state. While the truth may be out there in observed trajectories, existing methods struggle to extract it without supervision. In this work, we propose Unsupervised Imitation Learning from Observation (UfO) that addresses all of these limitations. UfO learns a policy through a two-stage process, in which the agent first obtains an approximation of the teacher's true actions in the observed state transitions, and then refines the learned policy further by adjusting agent trajectories to closely align them with the teacher's. Experiments we conducted in five widely used environments show that UfO not only outperforms the teacher and all other ILfO methods but also displays the smallest standard deviation. This reduction in standard deviation indicates better generalisation in unseen scenarios.
Explorative Imitation Learning: A Path Signature Approach for Continuous Environments
Jul 05, 2024



Some imitation learning methods combine behavioural cloning with self-supervision to infer actions from state pairs. However, most rely on a large number of expert trajectories to increase generalisation and human intervention to capture key aspects of the problem, such as domain constraints. In this paper, we propose Continuous Imitation Learning from Observation (CILO), a new method augmenting imitation learning with two important features: (i) exploration, allowing for more diverse state transitions, requiring less expert trajectories and resulting in fewer training iterations; and (ii) path signatures, allowing for automatic encoding of constraints, through the creation of non-parametric representations of agents and expert trajectories. We compared CILO with a baseline and two leading imitation learning methods in five environments. It had the best overall performance of all methods in all environments, outperforming the expert in two of them.
Imitation Learning: A Survey of Learning Methods, Environments and Metrics
Apr 30, 2024
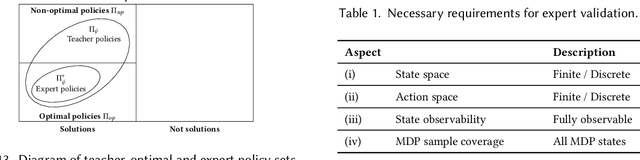

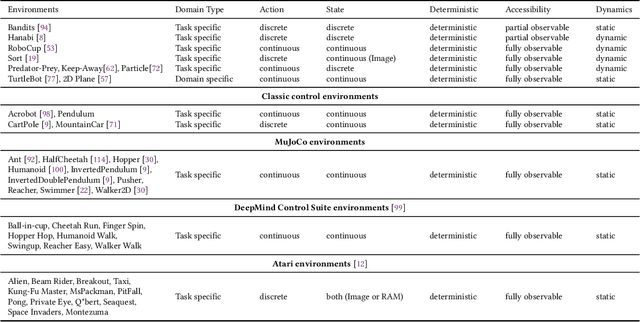
Imitation learning is an approach in which an agent learns how to execute a task by trying to mimic how one or more teachers perform it. This learning approach offers a compromise between the time it takes to learn a new task and the effort needed to collect teacher samples for the agent. It achieves this by balancing learning from the teacher, who has some information on how to perform the task, and deviating from their examples when necessary, such as states not present in the teacher samples. Consequently, the field of imitation learning has received much attention from researchers in recent years, resulting in many new methods and applications. However, with this increase in published work and past surveys focusing mainly on methodology, a lack of standardisation became more prominent in the field. This non-standardisation is evident in the use of environments, which appear in no more than two works, and evaluation processes, such as qualitative analysis, that have become rare in current literature. In this survey, we systematically review current imitation learning literature and present our findings by (i) classifying imitation learning techniques, environments and metrics by introducing novel taxonomies; (ii) reflecting on main problems from the literature; and (iii) presenting challenges and future directions for researchers.
Imitation Learning Datasets: A Toolkit For Creating Datasets, Training Agents and Benchmarking
Mar 01, 2024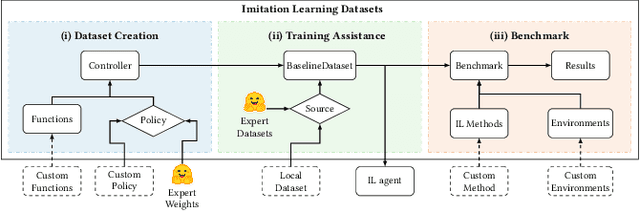
Imitation learning field requires expert data to train agents in a task. Most often, this learning approach suffers from the absence of available data, which results in techniques being tested on its dataset. Creating datasets is a cumbersome process requiring researchers to train expert agents from scratch, record their interactions and test each benchmark method with newly created data. Moreover, creating new datasets for each new technique results in a lack of consistency in the evaluation process since each dataset can drastically vary in state and action distribution. In response, this work aims to address these issues by creating Imitation Learning Datasets, a toolkit that allows for: (i) curated expert policies with multithreaded support for faster dataset creation; (ii) readily available datasets and techniques with precise measurements; and (iii) sharing implementations of common imitation learning techniques. Demonstration link: https://nathangavenski.github.io/#/il-datasets-video
Identifying Reasons for Bias: An Argumentation-Based Approach
Oct 26, 2023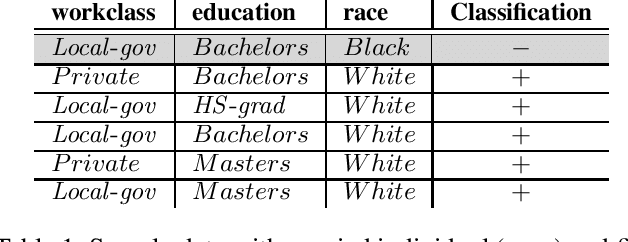

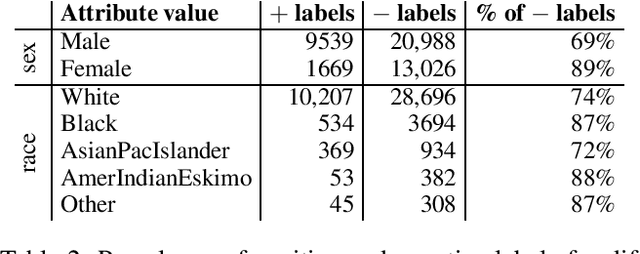
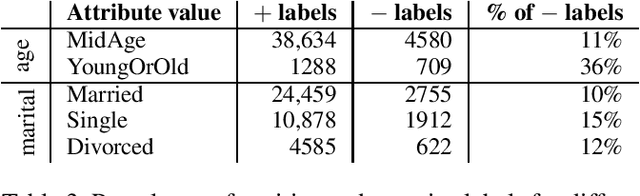
As algorithmic decision-making systems become more prevalent in society, ensuring the fairness of these systems is becoming increasingly important. Whilst there has been substantial research in building fair algorithmic decision-making systems, the majority of these methods require access to the training data, including personal characteristics, and are not transparent regarding which individuals are classified unfairly. In this paper, we propose a novel model-agnostic argumentation-based method to determine why an individual is classified differently in comparison to similar individuals. Our method uses a quantitative argumentation framework to represent attribute-value pairs of an individual and of those similar to them, and uses a well-known semantics to identify the attribute-value pairs in the individual contributing most to their different classification. We evaluate our method on two datasets commonly used in the fairness literature and illustrate its effectiveness in the identification of bias.
Bias Mitigation Methods for Binary Classification Decision-Making Systems: Survey and Recommendations
May 31, 2023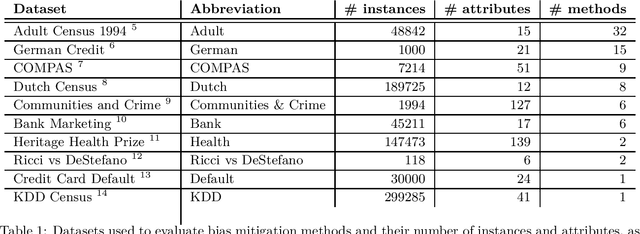
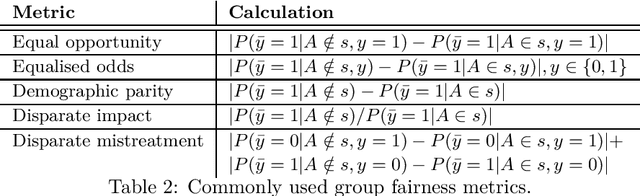
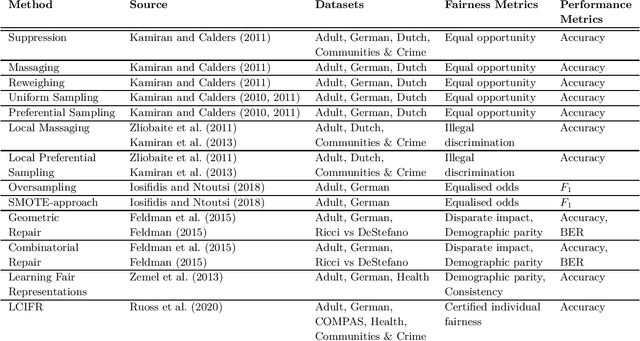
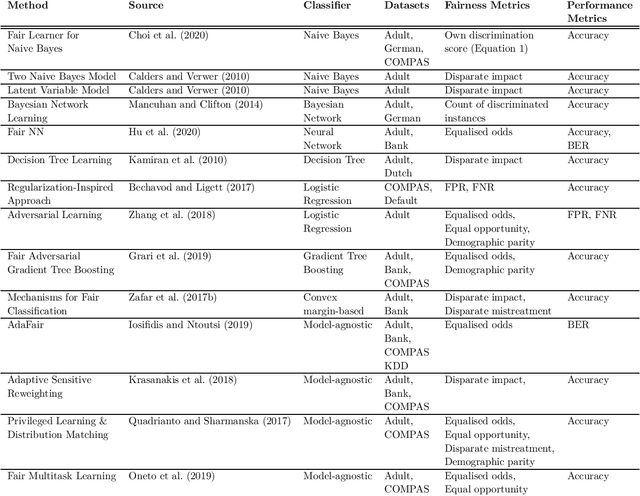
Bias mitigation methods for binary classification decision-making systems have been widely researched due to the ever-growing importance of designing fair machine learning processes that are impartial and do not discriminate against individuals or groups based on protected personal characteristics. In this paper, we present a structured overview of the research landscape for bias mitigation methods, report on their benefits and limitations, and provide recommendations for the development of future bias mitigation methods for binary classification.
ProVe: A Pipeline for Automated Provenance Verification of Knowledge Graphs against Textual Sources
Oct 26, 2022



Knowledge Graphs are repositories of information that gather data from a multitude of domains and sources in the form of semantic triples, serving as a source of structured data for various crucial applications in the modern web landscape, from Wikipedia infoboxes to search engines. Such graphs mainly serve as secondary sources of information and depend on well-documented and verifiable provenance to ensure their trustworthiness and usability. However, their ability to systematically assess and assure the quality of this provenance, most crucially whether it properly supports the graph's information, relies mainly on manual processes that do not scale with size. ProVe aims at remedying this, consisting of a pipelined approach that automatically verifies whether a Knowledge Graph triple is supported by text extracted from its documented provenance. ProVe is intended to assist information curators and consists of four main steps involving rule-based methods and machine learning models: text extraction, triple verbalisation, sentence selection, and claim verification. ProVe is evaluated on a Wikidata dataset, achieving promising results overall and excellent performance on the binary classification task of detecting support from provenance, with 87.5% accuracy and 82.9% F1-macro on text-rich sources. The evaluation data and scripts used in this paper are available on GitHub and Figshare.
Statistical and Neural Methods for Cross-lingual Entity Label Mapping in Knowledge Graphs
Jun 17, 2022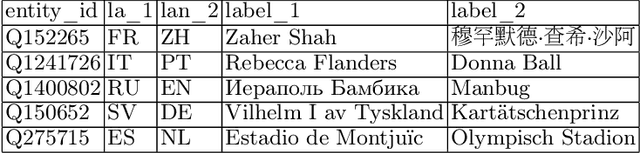
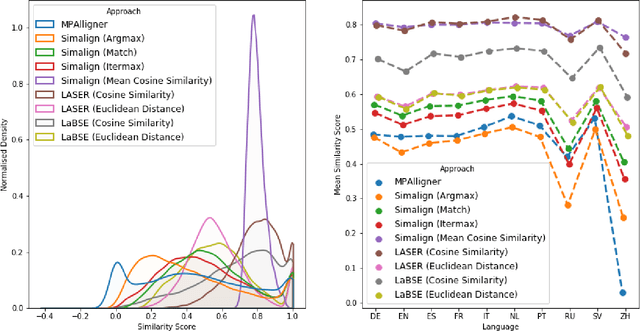
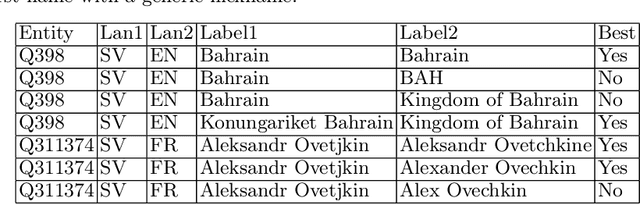
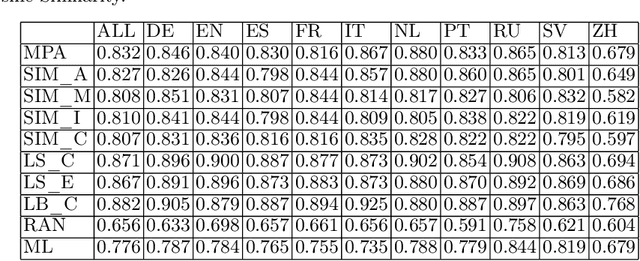
Knowledge bases such as Wikidata amass vast amounts of named entity information, such as multilingual labels, which can be extremely useful for various multilingual and cross-lingual applications. However, such labels are not guaranteed to match across languages from an information consistency standpoint, greatly compromising their usefulness for fields such as machine translation. In this work, we investigate the application of word and sentence alignment techniques coupled with a matching algorithm to align cross-lingual entity labels extracted from Wikidata in 10 languages. Our results indicate that mapping between Wikidata's main labels stands to be considerably improved (up to $20$ points in F1-score) by any of the employed methods. We show how methods relying on sentence embeddings outperform all others, even across different scripts. We believe the application of such techniques to measure the similarity of label pairs, coupled with a knowledge base rich in high-quality entity labels, to be an excellent asset to machine translation.
WDV: A Broad Data Verbalisation Dataset Built from Wikidata
May 05, 2022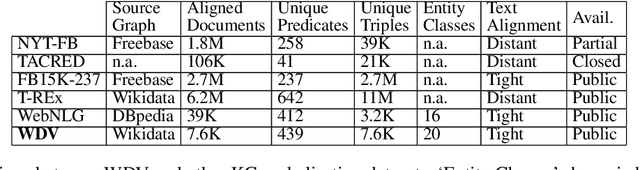
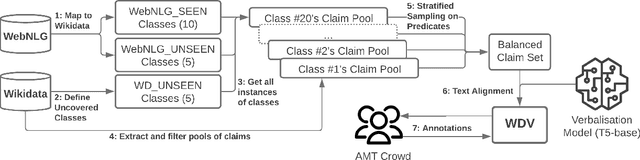
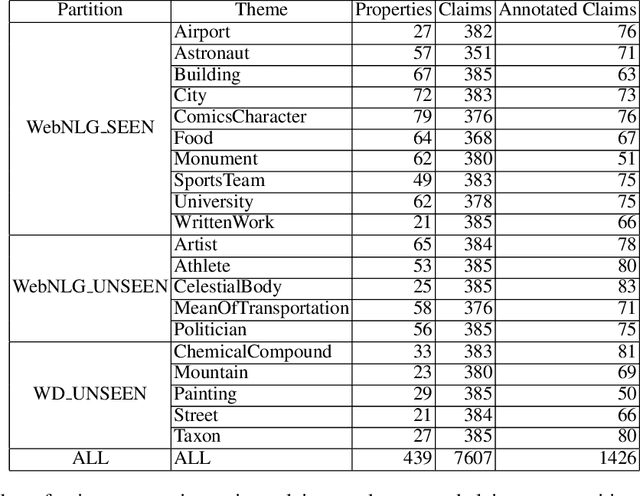
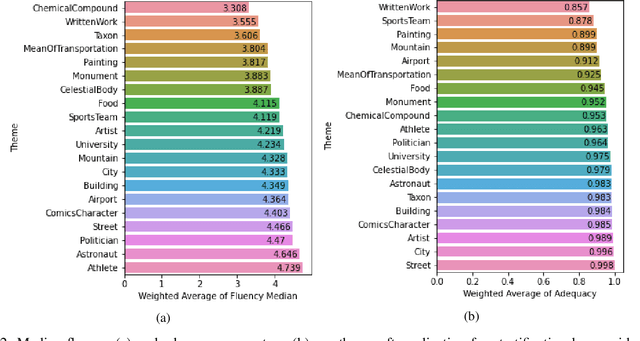
Data verbalisation is a task of great importance in the current field of natural language processing, as there is great benefit in the transformation of our abundant structured and semi-structured data into human-readable formats. Verbalising Knowledge Graph (KG) data focuses on converting interconnected triple-based claims, formed of subject, predicate, and object, into text. Although KG verbalisation datasets exist for some KGs, there are still gaps in their fitness for use in many scenarios. This is especially true for Wikidata, where available datasets either loosely couple claim sets with textual information or heavily focus on predicates around biographies, cities, and countries. To address these gaps, we propose WDV, a large KG claim verbalisation dataset built from Wikidata, with a tight coupling between triples and text, covering a wide variety of entities and predicates. We also evaluate the quality of our verbalisations through a reusable workflow for measuring human-centred fluency and adequacy scores. Our data and code are openly available in the hopes of furthering research towards KG verbalisation.