 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePresumed Cultural Identity: How Names Shape LLM Responses
Feb 17, 2025Names are deeply tied to human identity. They can serve as markers of individuality, cultural heritage, and personal history. However, using names as a core indicator of identity can lead to over-simplification of complex identities. When interacting with LLMs, user names are an important point of information for personalisation. Names can enter chatbot conversations through direct user input (requested by chatbots), as part of task contexts such as CV reviews, or as built-in memory features that store user information for personalisation. We study biases associated with names by measuring cultural presumptions in the responses generated by LLMs when presented with common suggestion-seeking queries, which might involve making assumptions about the user. Our analyses demonstrate strong assumptions about cultural identity associated with names present in LLM generations across multiple cultures. Our work has implications for designing more nuanced personalisation systems that avoid reinforcing stereotypes while maintaining meaningful customisation.
Investigating Wit, Creativity, and Detectability of Large Language Models in Domain-Specific Writing Style Adaptation of Reddit's Showerthoughts
May 02, 2024Recent Large Language Models (LLMs) have shown the ability to generate content that is difficult or impossible to distinguish from human writing. We investigate the ability of differently-sized LLMs to replicate human writing style in short, creative texts in the domain of Showerthoughts, thoughts that may occur during mundane activities. We compare GPT-2 and GPT-Neo fine-tuned on Reddit data as well as GPT-3.5 invoked in a zero-shot manner, against human-authored texts. We measure human preference on the texts across the specific dimensions that account for the quality of creative, witty texts. Additionally, we compare the ability of humans versus fine-tuned RoBERTa classifiers to detect AI-generated texts. We conclude that human evaluators rate the generated texts slightly worse on average regarding their creative quality, but they are unable to reliably distinguish between human-written and AI-generated texts. We further provide a dataset for creative, witty text generation based on Reddit Showerthoughts posts.
Why Should This Article Be Deleted? Transparent Stance Detection in Multilingual Wikipedia Editor Discussions
Oct 23, 2023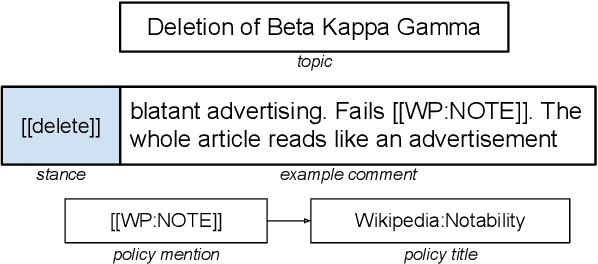

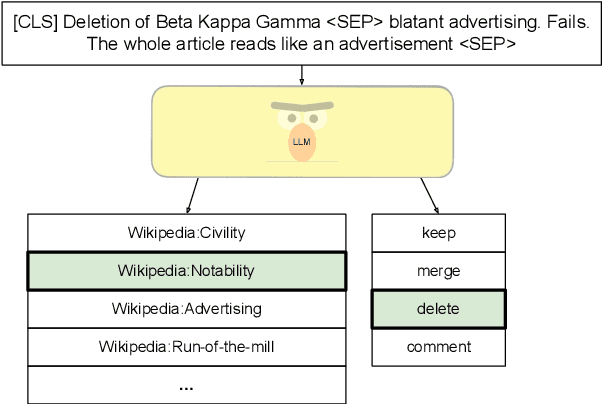

The moderation of content on online platforms is usually non-transparent. On Wikipedia, however, this discussion is carried out publicly and the editors are encouraged to use the content moderation policies as explanations for making moderation decisions. Currently, only a few comments explicitly mention those policies -- 20% of the English ones, but as few as 2% of the German and Turkish comments. To aid in this process of understanding how content is moderated, we construct a novel multilingual dataset of Wikipedia editor discussions along with their reasoning in three languages. The dataset contains the stances of the editors (keep, delete, merge, comment), along with the stated reason, and a content moderation policy, for each edit decision. We demonstrate that stance and corresponding reason (policy) can be predicted jointly with a high degree of accuracy, adding transparency to the decision-making process. We release both our joint prediction models and the multilingual content moderation dataset for further research on automated transparent content moderation.
Thorny Roses: Investigating the Dual Use Dilemma in Natural Language Processing
Apr 17, 2023
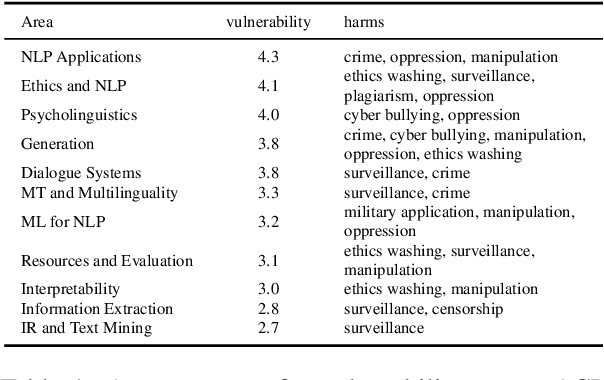
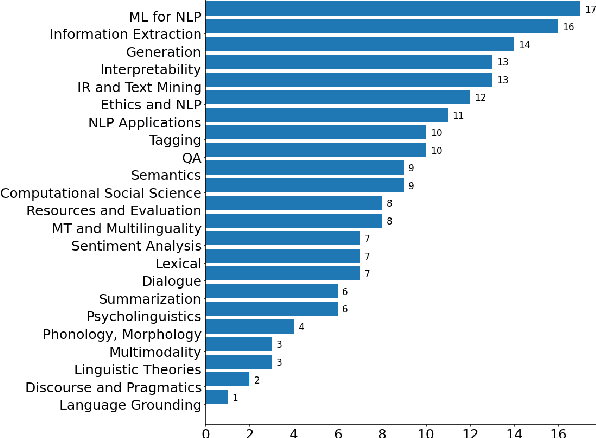
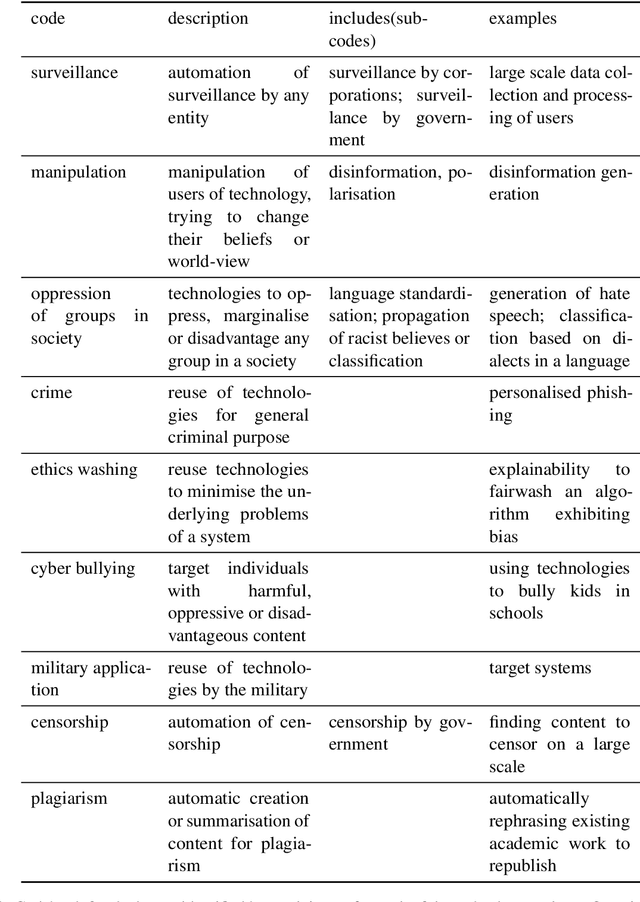
Dual use, the intentional, harmful reuse of technology and scientific artefacts, is a problem yet to be well-defined within the context of Natural Language Processing (NLP). However, as NLP technologies continue to advance and become increasingly widespread in society, their inner workings have become increasingly opaque. Therefore, understanding dual use concerns and potential ways of limiting them is critical to minimising the potential harms of research and development. In this paper, we conduct a survey of NLP researchers and practitioners to understand the depth and their perspective of the problem as well as to assess existing available support. Based on the results of our survey, we offer a definition of dual use that is tailored to the needs of the NLP community. The survey revealed that a majority of researchers are concerned about the potential dual use of their research but only take limited action toward it. In light of the survey results, we discuss the current state and potential means for mitigating dual use in NLP and propose a checklist that can be integrated into existing conference ethics-frameworks, e.g., the ACL ethics checklist.
Probing Pre-Trained Language Models for Cross-Cultural Differences in Values
Mar 25, 2022


Language embeds information about social, cultural, and political values people hold. Prior work has explored social and potentially harmful biases encoded in Pre-Trained Language models (PTLMs). However, there has been no systematic study investigating how values embedded in these models vary across cultures. In this paper, we introduce probes to study which values across cultures are embedded in these models, and whether they align with existing theories and cross-cultural value surveys. We find that PTLMs capture differences in values across cultures, but those only weakly align with established value surveys. We discuss implications of using mis-aligned models in cross-cultural settings, as well as ways of aligning PTLMs with value surveys.
Assessing the quality of sources in Wikidata across languages: a hybrid approach
Sep 20, 2021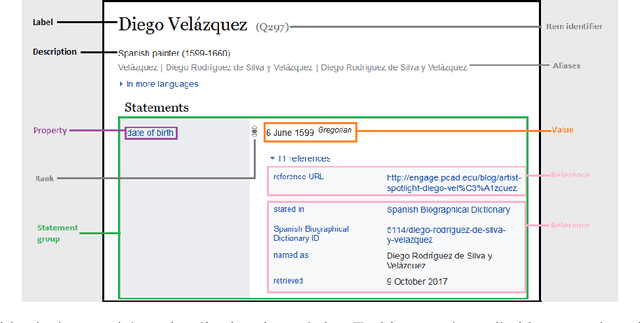
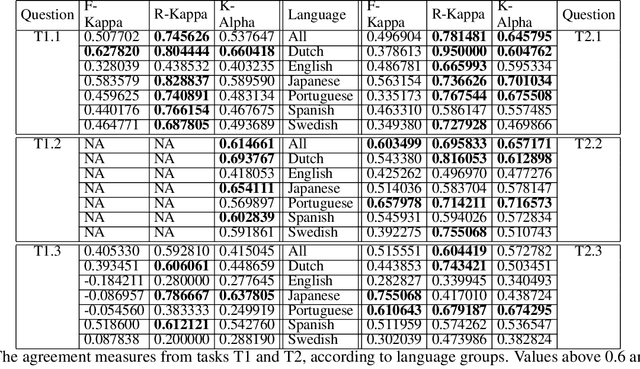
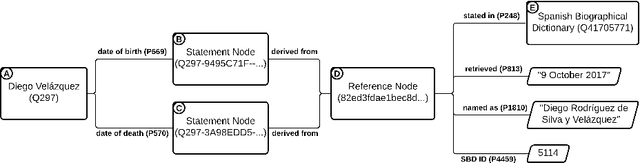
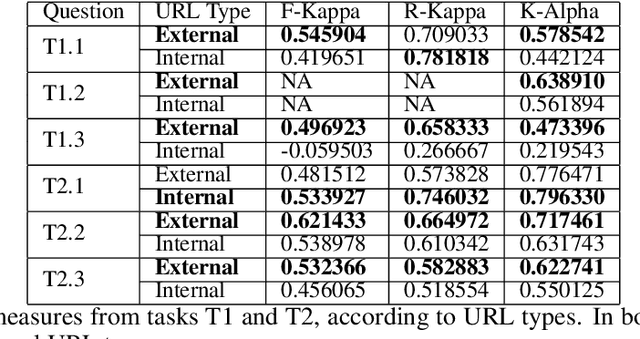
Wikidata is one of the most important sources of structured data on the web, built by a worldwide community of volunteers. As a secondary source, its contents must be backed by credible references; this is particularly important as Wikidata explicitly encourages editors to add claims for which there is no broad consensus, as long as they are corroborated by references. Nevertheless, despite this essential link between content and references, Wikidata's ability to systematically assess and assure the quality of its references remains limited. To this end, we carry out a mixed-methods study to determine the relevance, ease of access, and authoritativeness of Wikidata references, at scale and in different languages, using online crowdsourcing, descriptive statistics, and machine learning. Building on previous work of ours, we run a series of microtasks experiments to evaluate a large corpus of references, sampled from Wikidata triples with labels in several languages. We use a consolidated, curated version of the crowdsourced assessments to train several machine learning models to scale up the analysis to the whole of Wikidata. The findings help us ascertain the quality of references in Wikidata, and identify common challenges in defining and capturing the quality of user-generated multilingual structured data on the web. We also discuss ongoing editorial practices, which could encourage the use of higher-quality references in a more immediate way. All data and code used in the study are available on GitHub for feedback and further improvement and deployment by the research community.
References in Wikipedia: The Editors' Perspective
Mar 04, 2021

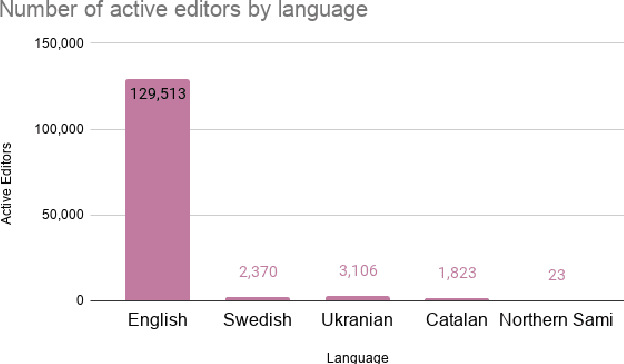
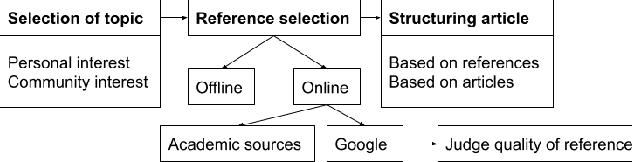
References are an essential part of Wikipedia. Each statement in Wikipedia should be referenced. In this paper, we explore the creation and collection of references for new Wikipedia articles from an editors' perspective. We map out the workflow of editors when creating a new article, emphasising how they select references.
Learning to Generate Wikipedia Summaries for Underserved Languages from Wikidata
Apr 29, 2018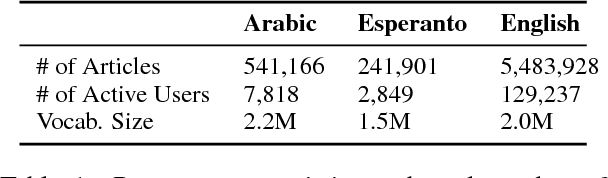
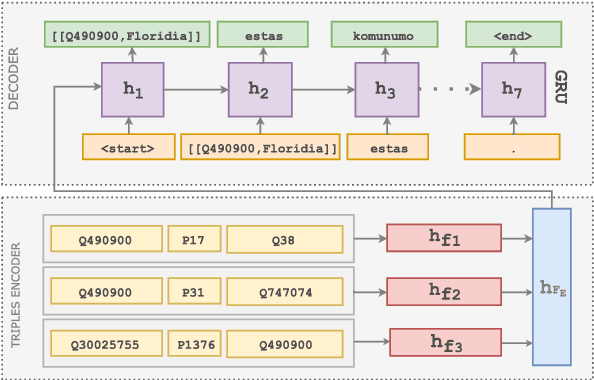


While Wikipedia exists in 287 languages, its content is unevenly distributed among them. In this work, we investigate the generation of open domain Wikipedia summaries in underserved languages using structured data from Wikidata. To this end, we propose a neural network architecture equipped with copy actions that learns to generate single-sentence and comprehensible textual summaries from Wikidata triples. We demonstrate the effectiveness of the proposed approach by evaluating it against a set of baselines on two languages of different natures: Arabic, a morphological rich language with a larger vocabulary than English, and Esperanto, a constructed language known for its easy acquisition.
Neural Wikipedian: Generating Textual Summaries from Knowledge Base Triples
Nov 01, 2017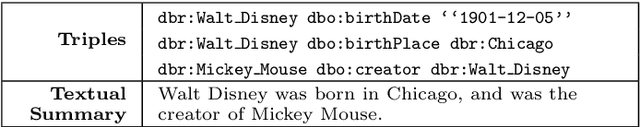
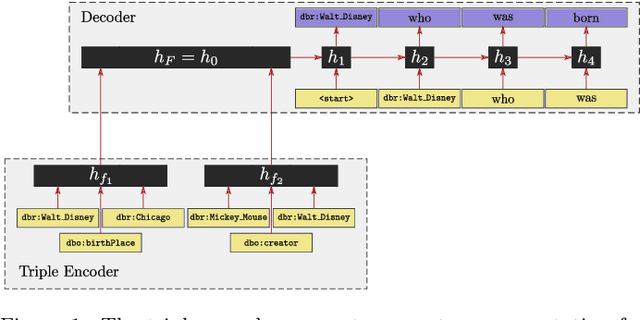
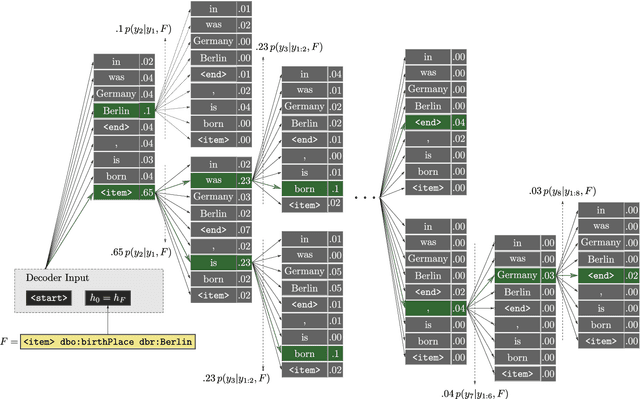

Most people do not interact with Semantic Web data directly. Unless they have the expertise to understand the underlying technology, they need textual or visual interfaces to help them make sense of it. We explore the problem of generating natural language summaries for Semantic Web data. This is non-trivial, especially in an open-domain context. To address this problem, we explore the use of neural networks. Our system encodes the information from a set of triples into a vector of fixed dimensionality and generates a textual summary by conditioning the output on the encoded vector. We train and evaluate our models on two corpora of loosely aligned Wikipedia snippets and DBpedia and Wikidata triples with promising results.