 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Online Sports Fan Communities Becoming More Offensive? A Quantitative Review of Topics, Trends, and Toxicity of r/PremierLeague
Oct 30, 2025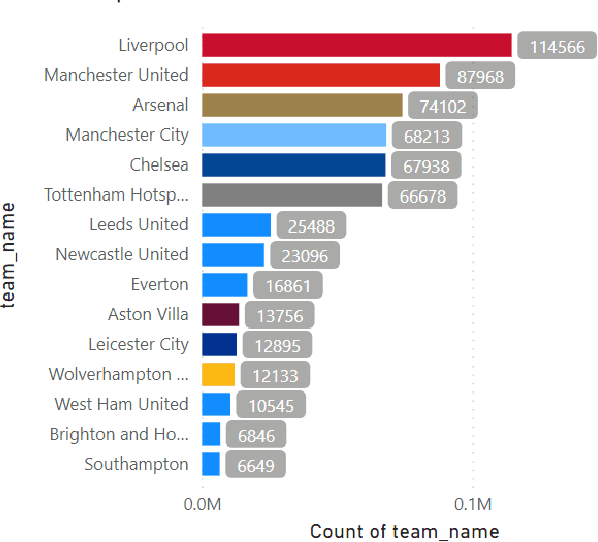



Online communities for sports fans have surged in popularity, with Reddit's r/PremierLeague emerging as a focal point for fans of one of the globe's most celebrated sports leagues. This boom has helped the Premier League make significant inroads into the US market, increasing viewership and sparking greater interest in its matches. Despite the league's broad appeal, there's still a notable gap in understanding its online fan community. Therefore, we analyzed a substantial dataset of over 1.1 million comments posted from 2013-2022 on r/PremierLeague. Our study delves into the sentiment, topics, and toxicity of these discussions, tracking trends over time, aiming to map out the conversation landscape. The rapid expansion has brought more diverse discussions, but also a worrying rise in negative sentiment and toxicity. Additionally, the subreddit has become a venue for users to voice frustrations about broader societal issues like racism, the COVID-19 pandemic, and political tensions.
Investigating Wit, Creativity, and Detectability of Large Language Models in Domain-Specific Writing Style Adaptation of Reddit's Showerthoughts
May 02, 2024Recent Large Language Models (LLMs) have shown the ability to generate content that is difficult or impossible to distinguish from human writing. We investigate the ability of differently-sized LLMs to replicate human writing style in short, creative texts in the domain of Showerthoughts, thoughts that may occur during mundane activities. We compare GPT-2 and GPT-Neo fine-tuned on Reddit data as well as GPT-3.5 invoked in a zero-shot manner, against human-authored texts. We measure human preference on the texts across the specific dimensions that account for the quality of creative, witty texts. Additionally, we compare the ability of humans versus fine-tuned RoBERTa classifiers to detect AI-generated texts. We conclude that human evaluators rate the generated texts slightly worse on average regarding their creative quality, but they are unable to reliably distinguish between human-written and AI-generated texts. We further provide a dataset for creative, witty text generation based on Reddit Showerthoughts posts.
FARSEC: A Reproducible Framework for Automatic Real-Time Vehicle Speed Estimation Using Traffic Cameras
Sep 25, 2023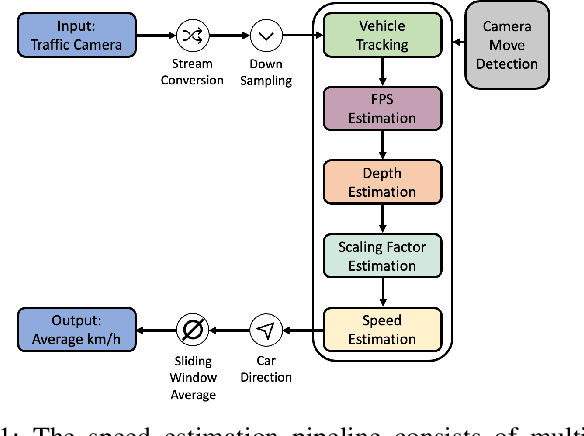
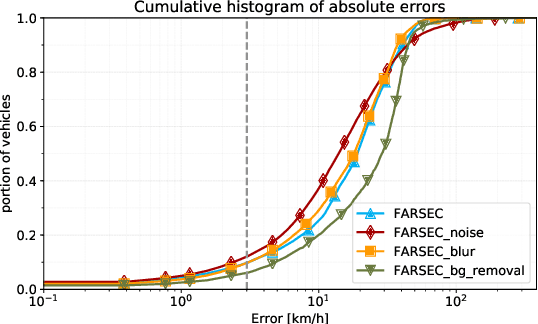


Estimating the speed of vehicles using traffic cameras is a crucial task for traffic surveillance and management, enabling more optimal traffic flow, improved road safety, and lower environmental impact. Transportation-dependent systems, such as for navigation and logistics, have great potential to benefit from reliable speed estimation. While there is prior research in this area reporting competitive accuracy levels, their solutions lack reproducibility and robustness across different datasets. To address this, we provide a novel framework for automatic real-time vehicle speed calculation, which copes with more diverse data from publicly available traffic cameras to achieve greater robustness. Our model employs novel techniques to estimate the length of road segments via depth map prediction. Additionally, our framework is capable of handling realistic conditions such as camera movements and different video stream inputs automatically. We compare our model to three well-known models in the field using their benchmark datasets. While our model does not set a new state of the art regarding prediction performance, the results are competitive on realistic CCTV videos. At the same time, our end-to-end pipeline offers more consistent results, an easier implementation, and better compatibility. Its modular structure facilitates reproducibility and future improvements.