 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCohort Discovery: A Survey on LLM-Assisted Clinical Trial Recruitment
Jun 18, 2025Recent advances in LLMs have greatly improved general-domain NLP tasks. Yet, their adoption in critical domains, such as clinical trial recruitment, remains limited. As trials are designed in natural language and patient data is represented as both structured and unstructured text, the task of matching trials and patients benefits from knowledge aggregation and reasoning abilities of LLMs. Classical approaches are trial-specific and LLMs with their ability to consolidate distributed knowledge hold the potential to build a more general solution. Yet recent applications of LLM-assisted methods rely on proprietary models and weak evaluation benchmarks. In this survey, we are the first to analyze the task of trial-patient matching and contextualize emerging LLM-based approaches in clinical trial recruitment. We critically examine existing benchmarks, approaches and evaluation frameworks, the challenges to adopting LLM technologies in clinical research and exciting future directions.
Decision Trees That Remember: Gradient-Based Learning of Recurrent Decision Trees with Memory
Feb 06, 2025Neural architectures such as Recurrent Neural Networks (RNNs), Transformers, and State-Space Models have shown great success in handling sequential data by learning temporal dependencies. Decision Trees (DTs), on the other hand, remain a widely used class of models for structured tabular data but are typically not designed to capture sequential patterns directly. Instead, DT-based approaches for time-series data often rely on feature engineering, such as manually incorporating lag features, which can be suboptimal for capturing complex temporal dependencies. To address this limitation, we introduce ReMeDe Trees, a novel recurrent DT architecture that integrates an internal memory mechanism, similar to RNNs, to learn long-term dependencies in sequential data. Our model learns hard, axis-aligned decision rules for both output generation and state updates, optimizing them efficiently via gradient descent. We provide a proof-of-concept study on synthetic benchmarks to demonstrate the effectiveness of our approach.
The Surprising Ineffectiveness of Pre-Trained Visual Representations for Model-Based Reinforcement Learning
Nov 15, 2024
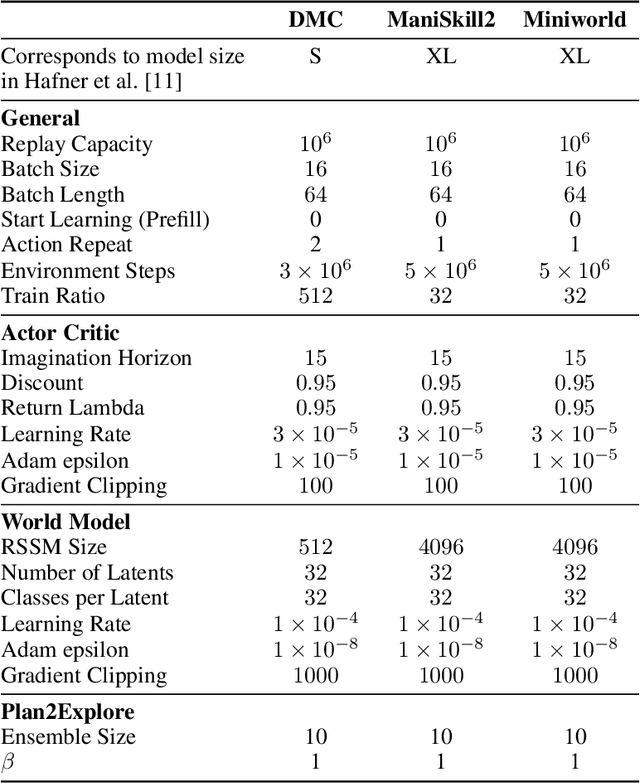

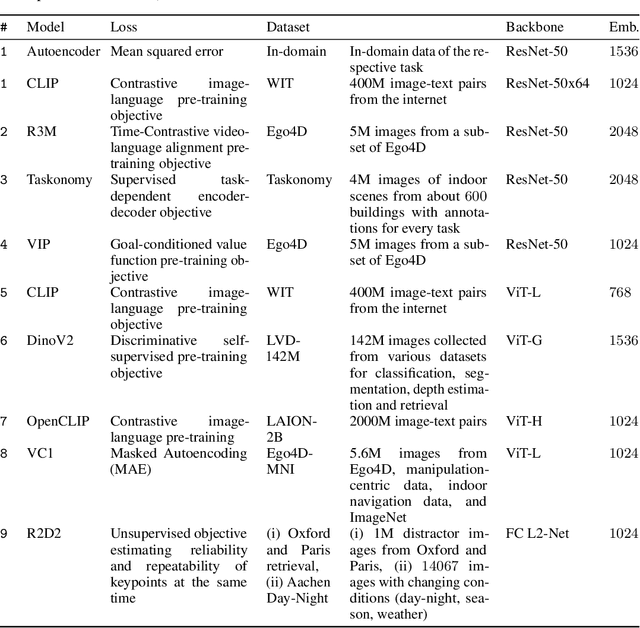
Visual Reinforcement Learning (RL) methods often require extensive amounts of data. As opposed to model-free RL, model-based RL (MBRL) offers a potential solution with efficient data utilization through planning. Additionally, RL lacks generalization capabilities for real-world tasks. Prior work has shown that incorporating pre-trained visual representations (PVRs) enhances sample efficiency and generalization. While PVRs have been extensively studied in the context of model-free RL, their potential in MBRL remains largely unexplored. In this paper, we benchmark a set of PVRs on challenging control tasks in a model-based RL setting. We investigate the data efficiency, generalization capabilities, and the impact of different properties of PVRs on the performance of model-based agents. Our results, perhaps surprisingly, reveal that for MBRL current PVRs are not more sample efficient than learning representations from scratch, and that they do not generalize better to out-of-distribution (OOD) settings. To explain this, we analyze the quality of the trained dynamics model. Furthermore, we show that data diversity and network architecture are the most important contributors to OOD generalization performance.
Subgroup-Specific Risk-Controlled Dose Estimation in Radiotherapy
Jul 11, 2024



Cancer remains a leading cause of death, highlighting the importance of effective radiotherapy (RT). Magnetic resonance-guided linear accelerators (MR-Linacs) enable imaging during RT, allowing for inter-fraction, and perhaps even intra-fraction, adjustments of treatment plans. However, achieving this requires fast and accurate dose calculations. While Monte Carlo simulations offer accuracy, they are computationally intensive. Deep learning frameworks show promise, yet lack uncertainty quantification crucial for high-risk applications like RT. Risk-controlling prediction sets (RCPS) offer model-agnostic uncertainty quantification with mathematical guarantees. However, we show that naive application of RCPS may lead to only certain subgroups such as the image background being risk-controlled. In this work, we extend RCPS to provide prediction intervals with coverage guarantees for multiple subgroups with unknown subgroup membership at test time. We evaluate our algorithm on real clinical planing volumes from five different anatomical regions and show that our novel subgroup RCPS (SG-RCPS) algorithm leads to prediction intervals that jointly control the risk for multiple subgroups. In particular, our method controls the risk of the crucial voxels along the radiation beam significantly better than conventional RCPS.
Investigating Wit, Creativity, and Detectability of Large Language Models in Domain-Specific Writing Style Adaptation of Reddit's Showerthoughts
May 02, 2024Recent Large Language Models (LLMs) have shown the ability to generate content that is difficult or impossible to distinguish from human writing. We investigate the ability of differently-sized LLMs to replicate human writing style in short, creative texts in the domain of Showerthoughts, thoughts that may occur during mundane activities. We compare GPT-2 and GPT-Neo fine-tuned on Reddit data as well as GPT-3.5 invoked in a zero-shot manner, against human-authored texts. We measure human preference on the texts across the specific dimensions that account for the quality of creative, witty texts. Additionally, we compare the ability of humans versus fine-tuned RoBERTa classifiers to detect AI-generated texts. We conclude that human evaluators rate the generated texts slightly worse on average regarding their creative quality, but they are unable to reliably distinguish between human-written and AI-generated texts. We further provide a dataset for creative, witty text generation based on Reddit Showerthoughts posts.
Emergency Response Inference Mapping (ERIMap): A Bayesian Network-based Method for Dynamic Observation Processing in Spatially Distributed Emergencies
Mar 11, 2024



In emergencies, high stake decisions often have to be made under time pressure and strain. In order to support such decisions, information from various sources needs to be collected and processed rapidly. The information available tends to be temporally and spatially variable, uncertain, and sometimes conflicting, leading to potential biases in decisions. Currently, there is a lack of systematic approaches for information processing and situation assessment which meet the particular demands of emergency situations. To address this gap, we present a Bayesian network-based method called ERIMap that is tailored to the complex information-scape during emergencies. The method enables the systematic and rapid processing of heterogeneous and potentially uncertain observations and draws inferences about key variables of an emergency. It thereby reduces complexity and cognitive load for decision makers. The output of the ERIMap method is a dynamically evolving and spatially resolved map of beliefs about key variables of an emergency that is updated each time a new observation becomes available. The method is illustrated in a case study in which an emergency response is triggered by an accident causing a gas leakage on a chemical plant site.
How Do You Act? An Empirical Study to Understand Behavior of Deep Reinforcement Learning Agents
Apr 07, 2020
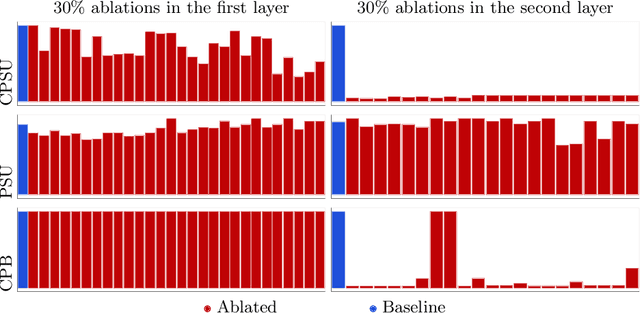
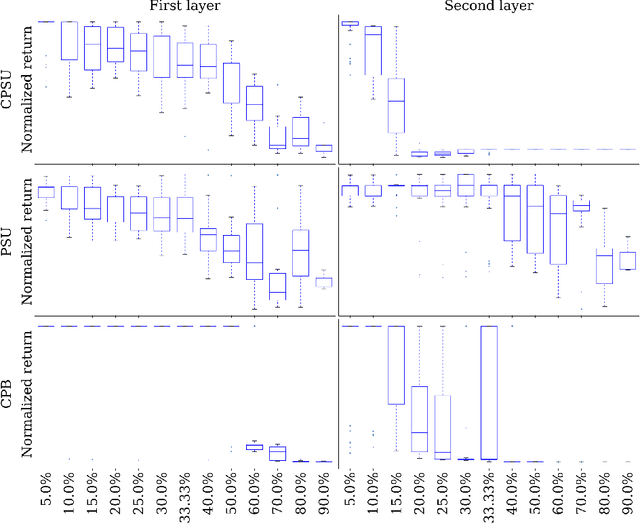
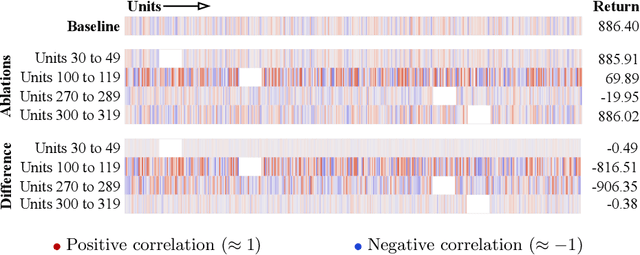
The demand for more transparency of decision-making processes of deep reinforcement learning agents is greater than ever, due to their increased use in safety critical and ethically challenging domains such as autonomous driving. In this empirical study, we address this lack of transparency following an idea that is inspired by research in the field of neuroscience. We characterize the learned representations of an agent's policy network through its activation space and perform partial network ablations to compare the representations of the healthy and the intentionally damaged networks. We show that the healthy agent's behavior is characterized by a distinct correlation pattern between the network's layer activation and the performed actions during an episode and that network ablations, which cause a strong change of this pattern, lead to the agent failing its trained control task. Furthermore, the learned representation of the healthy agent is characterized by a distinct pattern in its activation space reflecting its different behavioral stages during an episode, which again, when distorted by network ablations, leads to the agent failing its trained control task. Concludingly, we argue in favor of a new perspective on artificial neural networks as objects of empirical investigations, just as biological neural systems in neuroscientific studies, paving the way towards a new standard of scientific falsifiability with respect to research on transparency and interpretability of artificial neural networks.