 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprising Ineffectiveness of Pre-Trained Visual Representations for Model-Based Reinforcement Learning
Nov 15, 2024
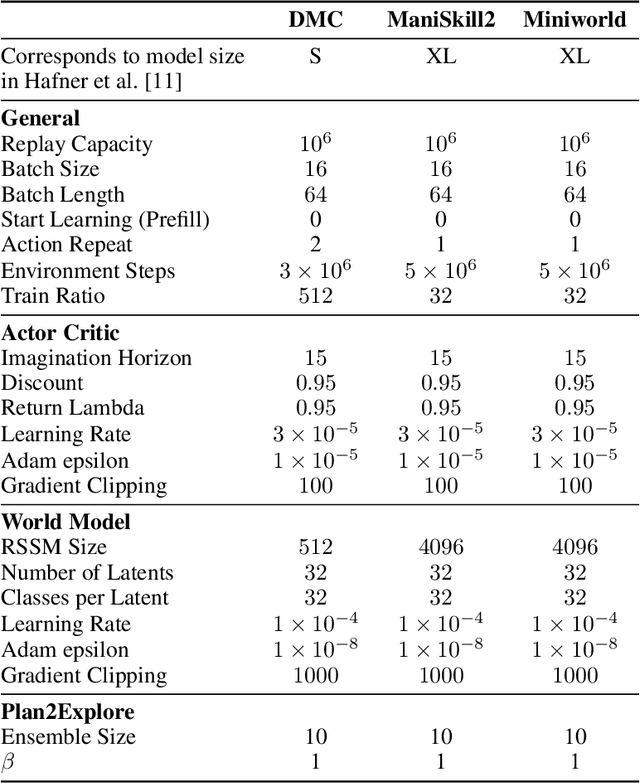

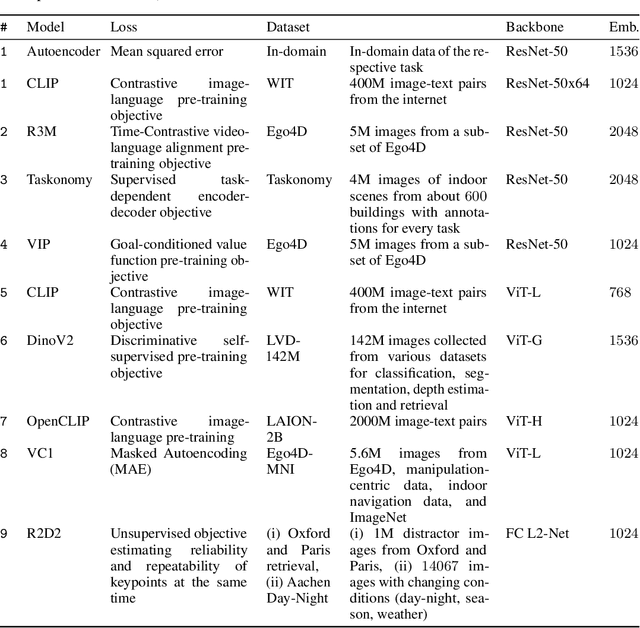
Visual Reinforcement Learning (RL) methods often require extensive amounts of data. As opposed to model-free RL, model-based RL (MBRL) offers a potential solution with efficient data utilization through planning. Additionally, RL lacks generalization capabilities for real-world tasks. Prior work has shown that incorporating pre-trained visual representations (PVRs) enhances sample efficiency and generalization. While PVRs have been extensively studied in the context of model-free RL, their potential in MBRL remains largely unexplored. In this paper, we benchmark a set of PVRs on challenging control tasks in a model-based RL setting. We investigate the data efficiency, generalization capabilities, and the impact of different properties of PVRs on the performance of model-based agents. Our results, perhaps surprisingly, reveal that for MBRL current PVRs are not more sample efficient than learning representations from scratch, and that they do not generalize better to out-of-distribution (OOD) settings. To explain this, we analyze the quality of the trained dynamics model. Furthermore, we show that data diversity and network architecture are the most important contributors to OOD generalization performance.
The e-Bike Motor Assembly: Towards Advanced Robotic Manipulation for Flexible Manufacturing
Apr 20, 2023



Robotic manipulation is currently undergoing a profound paradigm shift due to the increasing needs for flexible manufacturing systems, and at the same time, because of the advances in enabling technologies such as sensing, learning, optimization, and hardware. This demands for robots that can observe and reason about their workspace, and that are skillfull enough to complete various assembly processes in weakly-structured settings. Moreover, it remains a great challenge to enable operators for teaching robots on-site, while managing the inherent complexity of perception, control, motion planning and reaction to unexpected situations. Motivated by real-world industrial applications, this paper demonstrates the potential of such a paradigm shift in robotics on the industrial case of an e-Bike motor assembly. The paper presents a concept for teaching and programming adaptive robots on-site and demonstrates their potential for the named applications. The framework includes: (i) a method to teach perception systems onsite in a self-supervised manner, (ii) a general representation of object-centric motion skills and force-sensitive assembly skills, both learned from demonstration, (iii) a sequencing approach that exploits a human-designed plan to perform complex tasks, and (iv) a system solution for adapting and optimizing skills online. The aforementioned components are interfaced through a four-layer software architecture that makes our framework a tangible industrial technology. To demonstrate the generality of the proposed framework, we provide, in addition to the motivating e-Bike motor assembly, a further case study on dense box packing for logistics automation.
End-to-End Learning of Hybrid Inverse Dynamics Models for Precise and Compliant Impedance Control
May 27, 2022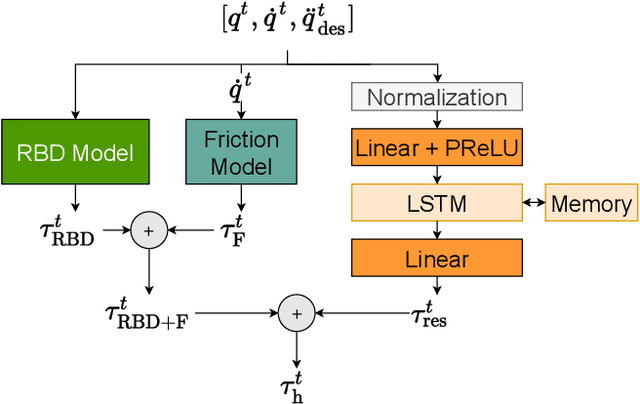
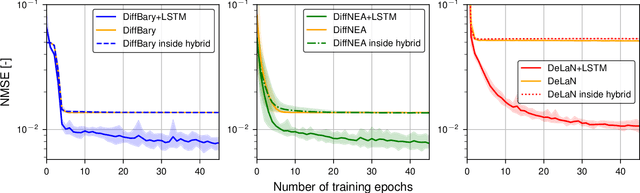
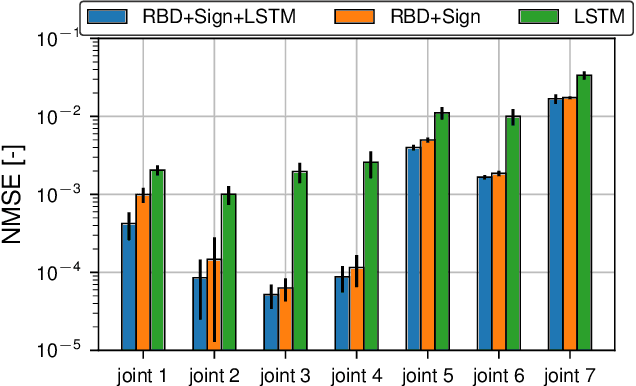
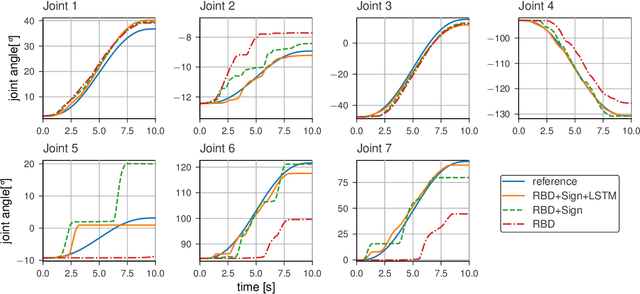
It is well-known that inverse dynamics models can improve tracking performance in robot control. These models need to precisely capture the robot dynamics, which consist of well-understood components, e.g., rigid body dynamics, and effects that remain challenging to capture, e.g., stick-slip friction and mechanical flexibilities. Such effects exhibit hysteresis and partial observability, rendering them, particularly challenging to model. Hence, hybrid models, which combine a physical prior with data-driven approaches are especially well-suited in this setting. We present a novel hybrid model formulation that enables us to identify fully physically consistent inertial parameters of a rigid body dynamics model which is paired with a recurrent neural network architecture, allowing us to capture unmodeled partially observable effects using the network memory. We compare our approach against state-of-the-art inverse dynamics models on a 7 degree of freedom manipulator. Using data sets obtained through an optimal experiment design approach, we study the accuracy of offline torque prediction and generalization capabilities of joint learning methods. In control experiments on the real system, we evaluate the model as a feed-forward term for impedance control and show the feedback gains can be drastically reduced to achieve a given tracking accuracy.
Learning Forceful Manipulation Skills from Multi-modal Human Demonstrations
Sep 09, 2021
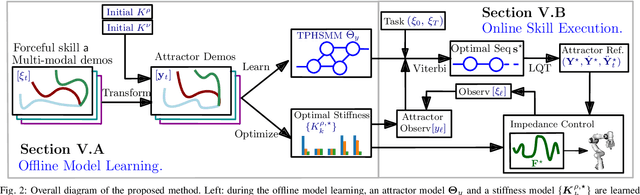
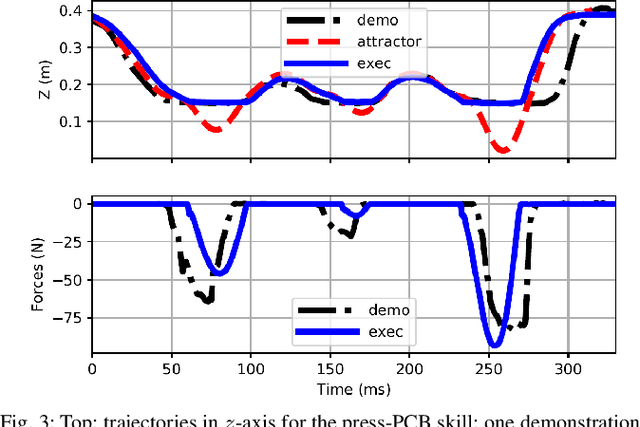
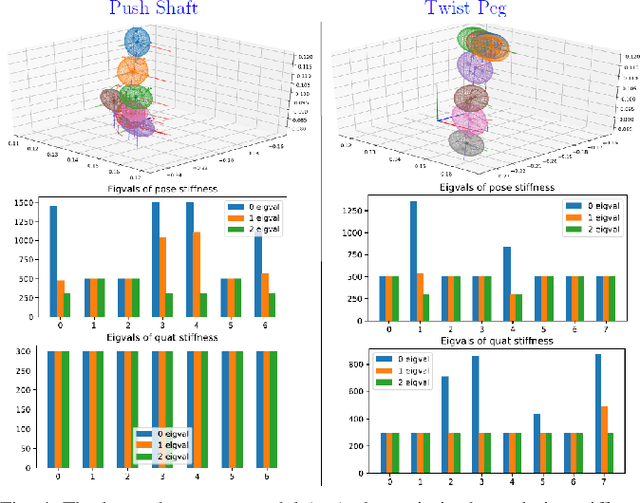
Learning from Demonstration (LfD) provides an intuitive and fast approach to program robotic manipulators. Task parameterized representations allow easy adaptation to new scenes and online observations. However, this approach has been limited to pose-only demonstrations and thus only skills with spatial and temporal features. In this work, we extend the LfD framework to address forceful manipulation skills, which are of great importance for industrial processes such as assembly. For such skills, multi-modal demonstrations including robot end-effector poses, force and torque readings, and operation scene are essential. Our objective is to reproduce such skills reliably according to the demonstrated pose and force profiles within different scenes. The proposed method combines our previous work on task-parameterized optimization and attractor-based impedance control. The learned skill model consists of (i) the attractor model that unifies the pose and force features, and (ii) the stiffness model that optimizes the stiffness for different stages of the skill. Furthermore, an online execution algorithm is proposed to adapt the skill execution to real-time observations of robot poses, measured forces, and changed scenes. We validate this method rigorously on a 7-DoF robot arm over several steps of an E-bike motor assembly process, which require different types of forceful interaction such as insertion, sliding and twisting.
Safe-To-Explore State Spaces: Ensuring Safe Exploration in Policy Search with Hierarchical Task Optimization
Oct 08, 2018



Policy search reinforcement learning allows robots to acquire skills by themselves. However, the learning procedure is inherently unsafe as the robot has no a-priori way to predict the consequences of the exploratory actions it takes. Therefore, exploration can lead to collisions with the potential to harm the robot and/or the environment. In this work we address the safety aspect by constraining the exploration to happen in safe-to-explore state spaces. These are formed by decomposing target skills (e.g., grasping) into higher ranked sub-tasks (e.g., collision avoidance, joint limit avoidance) and lower ranked movement tasks (e.g., reaching). Sub-tasks are defined as concurrent controllers (policies) in different operational spaces together with associated Jacobians representing their joint-space mapping. Safety is ensured by only learning policies corresponding to lower ranked sub-tasks in the redundant null space of higher ranked ones. As a side benefit, learning in sub-manifolds of the state-space also facilitates sample efficiency. Reaching skills performed in simulation and grasping skills performed on a real robot validate the usefulness of the proposed approach.