 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-Correspondence Loss: Learning Dense View-Invariant Visual Features from Unlabeled and Unordered RGB Images
Jun 18, 2024



Robot manipulation relying on learned object-centric descriptors became popular in recent years. Visual descriptors can easily describe manipulation task objectives, they can be learned efficiently using self-supervision, and they can encode actuated and even non-rigid objects. However, learning robust, view-invariant keypoints in a self-supervised approach requires a meticulous data collection approach involving precise calibration and expert supervision. In this paper we introduce Cycle-Correspondence Loss (CCL) for view-invariant dense descriptor learning, which adopts the concept of cycle-consistency, enabling a simple data collection pipeline and training on unpaired RGB camera views. The key idea is to autonomously detect valid pixel correspondences by attempting to use a prediction over a new image to predict the original pixel in the original image, while scaling error terms based on the estimated confidence. Our evaluation shows that we outperform other self-supervised RGB-only methods, and approach performance of supervised methods, both with respect to keypoint tracking as well as for a robot grasping downstream task.
Efficient End-to-End Detection of 6-DoF Grasps for Robotic Bin Picking
May 10, 2024



Bin picking is an important building block for many robotic systems, in logistics, production or in household use-cases. In recent years, machine learning methods for the prediction of 6-DoF grasps on diverse and unknown objects have shown promising progress. However, existing approaches only consider a single ground truth grasp orientation at a grasp location during training and therefore can only predict limited grasp orientations which leads to a reduced number of feasible grasps in bin picking with restricted reachability. In this paper, we propose a novel approach for learning dense and diverse 6-DoF grasps for parallel-jaw grippers in robotic bin picking. We introduce a parameterized grasp distribution model based on Power-Spherical distributions that enables a training based on all possible ground truth samples. Thereby, we also consider the grasp uncertainty enhancing the model's robustness to noisy inputs. As a result, given a single top-down view depth image, our model can generate diverse grasps with multiple collision-free grasp orientations. Experimental evaluations in simulation and on a real robotic bin picking setup demonstrate the model's ability to generalize across various object categories achieving an object clearing rate of around $90 \%$ in simulation and real-world experiments. We also outperform state of the art approaches. Moreover, the proposed approach exhibits its usability in real robot experiments without any refinement steps, even when only trained on a synthetic dataset, due to the probabilistic grasp distribution modeling.
The e-Bike Motor Assembly: Towards Advanced Robotic Manipulation for Flexible Manufacturing
Apr 20, 2023



Robotic manipulation is currently undergoing a profound paradigm shift due to the increasing needs for flexible manufacturing systems, and at the same time, because of the advances in enabling technologies such as sensing, learning, optimization, and hardware. This demands for robots that can observe and reason about their workspace, and that are skillfull enough to complete various assembly processes in weakly-structured settings. Moreover, it remains a great challenge to enable operators for teaching robots on-site, while managing the inherent complexity of perception, control, motion planning and reaction to unexpected situations. Motivated by real-world industrial applications, this paper demonstrates the potential of such a paradigm shift in robotics on the industrial case of an e-Bike motor assembly. The paper presents a concept for teaching and programming adaptive robots on-site and demonstrates their potential for the named applications. The framework includes: (i) a method to teach perception systems onsite in a self-supervised manner, (ii) a general representation of object-centric motion skills and force-sensitive assembly skills, both learned from demonstration, (iii) a sequencing approach that exploits a human-designed plan to perform complex tasks, and (iv) a system solution for adapting and optimizing skills online. The aforementioned components are interfaced through a four-layer software architecture that makes our framework a tangible industrial technology. To demonstrate the generality of the proposed framework, we provide, in addition to the motivating e-Bike motor assembly, a further case study on dense box packing for logistics automation.
Learning Dense Visual Descriptors using Image Augmentations for Robot Manipulation Tasks
Sep 12, 2022

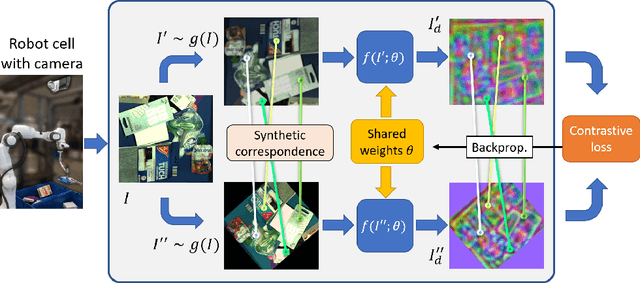

We propose a self-supervised training approach for learning view-invariant dense visual descriptors using image augmentations. Unlike existing works, which often require complex datasets, such as registered RGBD sequences, we train on an unordered set of RGB images. This allows for learning from a single camera view, e.g., in an existing robotic cell with a fix-mounted camera. We create synthetic views and dense pixel correspondences using data augmentations. We find our descriptors are competitive to the existing methods, despite the simpler data recording and setup requirements. We show that training on synthetic correspondences provides descriptor consistency across a broad range of camera views. We compare against training with geometric correspondence from multiple views and provide ablation studies. We also show a robotic bin-picking experiment using descriptors learned from a fix-mounted camera for defining grasp preferences.
Efficient and Robust Training of Dense Object Nets for Multi-Object Robot Manipulation
Jun 24, 2022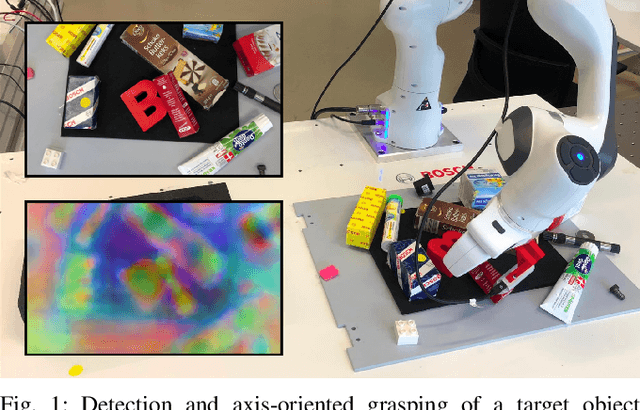

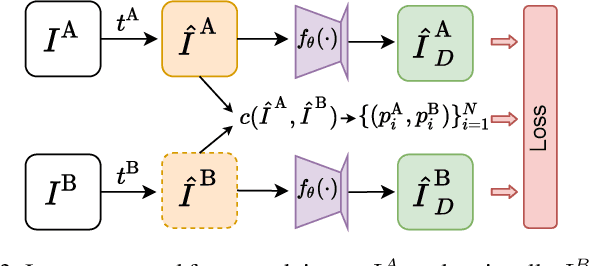
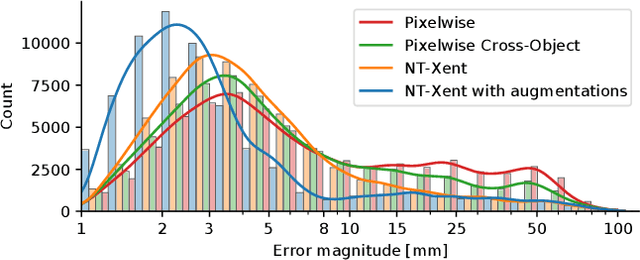
We propose a framework for robust and efficient training of Dense Object Nets (DON) with a focus on multi-object robot manipulation scenarios. DON is a popular approach to obtain dense, view-invariant object descriptors, which can be used for a multitude of downstream tasks in robot manipulation, such as, pose estimation, state representation for control, etc.. However, the original work focused training on singulated objects, with limited results on instance-specific, multi-object applications. Additionally, a complex data collection pipeline, including 3D reconstruction and mask annotation of each object, is required for training. In this paper, we further improve the efficacy of DON with a simplified data collection and training regime, that consistently yields higher precision and enables robust tracking of keypoints with less data requirements. In particular, we focus on training with multi-object data instead of singulated objects, combined with a well-chosen augmentation scheme. We additionally propose an alternative loss formulation to the original pixelwise formulation that offers better results and is less sensitive to hyperparameters. Finally, we demonstrate the robustness and accuracy of our proposed framework on a real-world robotic grasping task.
Supervised Training of Dense Object Nets using Optimal Descriptors for Industrial Robotic Applications
Feb 16, 2021


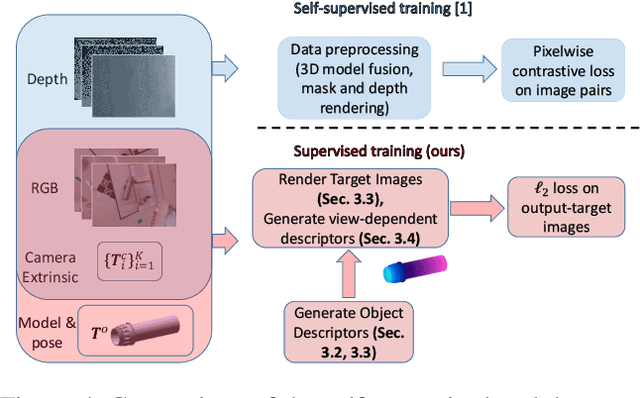
Dense Object Nets (DONs) by Florence, Manuelli and Tedrake (2018) introduced dense object descriptors as a novel visual object representation for the robotics community. It is suitable for many applications including object grasping, policy learning, etc. DONs map an RGB image depicting an object into a descriptor space image, which implicitly encodes key features of an object invariant to the relative camera pose. Impressively, the self-supervised training of DONs can be applied to arbitrary objects and can be evaluated and deployed within hours. However, the training approach relies on accurate depth images and faces challenges with small, reflective objects, typical for industrial settings, when using consumer grade depth cameras. In this paper we show that given a 3D model of an object, we can generate its descriptor space image, which allows for supervised training of DONs. We rely on Laplacian Eigenmaps (LE) to embed the 3D model of an object into an optimally generated space. While our approach uses more domain knowledge, it can be efficiently applied even for smaller and reflective objects, as it does not rely on depth information. We compare the training methods on generating 6D grasps for industrial objects and show that our novel supervised training approach improves the pick-and-place performance in industry-relevant tasks.
Learning and Sequencing of Object-Centric Manipulation Skills for Industrial Tasks
Aug 24, 2020
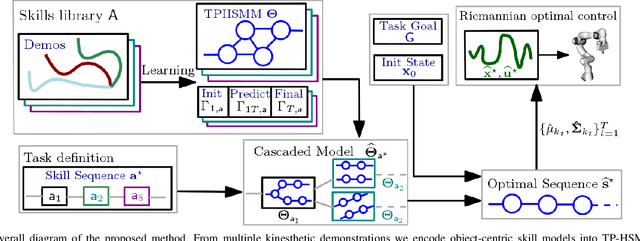
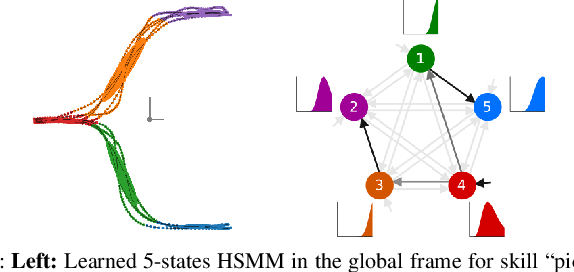

Enabling robots to quickly learn manipulation skills is an important, yet challenging problem. Such manipulation skills should be flexible, e.g., be able adapt to the current workspace configuration. Furthermore, to accomplish complex manipulation tasks, robots should be able to sequence several skills and adapt them to changing situations. In this work, we propose a rapid robot skill-sequencing algorithm, where the skills are encoded by object-centric hidden semi-Markov models. The learned skill models can encode multimodal (temporal and spatial) trajectory distributions. This approach significantly reduces manual modeling efforts, while ensuring a high degree of flexibility and re-usability of learned skills. Given a task goal and a set of generic skills, our framework computes smooth transitions between skill instances. To compute the corresponding optimal end-effector trajectory in task space we rely on Riemannian optimal controller. We demonstrate this approach on a 7 DoF robot arm for industrial assembly tasks.