 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRACE: A Unified 2D Multi-Robot Path Planning Simulator & Benchmark for Grid, Roadmap, And Continuous Environments
Mar 11, 2026Advancing Multi-Agent Pathfinding (MAPF) and Multi-Robot Motion Planning (MRMP) requires platforms that enable transparent, reproducible comparisons across modeling choices. Existing tools either scale under simplifying assumptions (grids, homogeneous agents) or offer higher fidelity with less comparable instrumentation. We present GRACE, a unified 2D simulator+benchmark that instantiates the same task at multiple abstraction levels (grid, roadmap, continuous) via explicit, reproducible operators and a common evaluation protocol. Our empirical results on public maps and representative planners enable commensurate comparisons on a shared instance set. Furthermore, we quantify the expected representation-fidelity trade-offs (MRMP solves instances at higher fidelity but lower speed, while grid/roadmap planners scale farther). By consolidating representation, execution, and evaluation, GRACE thereby aims to make cross-representation studies more comparable and provides a means to advance multi-robot planning research and its translation to practice.
Adaptive Domain Modeling with Language Models: A Multi-Agent Approach to Task Planning
Jun 24, 2025We introduce TAPAS (Task-based Adaptation and Planning using AgentS), a multi-agent framework that integrates Large Language Models (LLMs) with symbolic planning to solve complex tasks without the need for manually defined environment models. TAPAS employs specialized LLM-based agents that collaboratively generate and adapt domain models, initial states, and goal specifications as needed using structured tool-calling mechanisms. Through this tool-based interaction, downstream agents can request modifications from upstream agents, enabling adaptation to novel attributes and constraints without manual domain redefinition. A ReAct (Reason+Act)-style execution agent, coupled with natural language plan translation, bridges the gap between dynamically generated plans and real-world robot capabilities. TAPAS demonstrates strong performance in benchmark planning domains and in the VirtualHome simulated real-world environment.
Diffeomorphic Obstacle Avoidance for Contractive Dynamical Systems via Implicit Representations
Apr 26, 2025



Ensuring safety and robustness of robot skills is becoming crucial as robots are required to perform increasingly complex and dynamic tasks. The former is essential when performing tasks in cluttered environments, while the latter is relevant to overcome unseen task situations. This paper addresses the challenge of ensuring both safety and robustness in dynamic robot skills learned from demonstrations. Specifically, we build on neural contractive dynamical systems to provide robust extrapolation of the learned skills, while designing a full-body obstacle avoidance strategy that preserves contraction stability via diffeomorphic transforms. This is particularly crucial in complex environments where implicit scene representations, such as Signed Distance Fields (SDFs), are necessary. To this end, our framework called Signed Distance Field Diffeomorphic Transform, leverages SDFs and flow-based diffeomorphisms to achieve contraction-preserving obstacle avoidance. We thoroughly evaluate our framework on synthetic datasets and several real-world robotic tasks in a kitchen environment. Our results show that our approach locally adapts the learned contractive vector field while staying close to the learned dynamics and without introducing highly-curved motion paths, thus outperforming several state-of-the-art methods.
Efficient End-to-End Detection of 6-DoF Grasps for Robotic Bin Picking
May 10, 2024



Bin picking is an important building block for many robotic systems, in logistics, production or in household use-cases. In recent years, machine learning methods for the prediction of 6-DoF grasps on diverse and unknown objects have shown promising progress. However, existing approaches only consider a single ground truth grasp orientation at a grasp location during training and therefore can only predict limited grasp orientations which leads to a reduced number of feasible grasps in bin picking with restricted reachability. In this paper, we propose a novel approach for learning dense and diverse 6-DoF grasps for parallel-jaw grippers in robotic bin picking. We introduce a parameterized grasp distribution model based on Power-Spherical distributions that enables a training based on all possible ground truth samples. Thereby, we also consider the grasp uncertainty enhancing the model's robustness to noisy inputs. As a result, given a single top-down view depth image, our model can generate diverse grasps with multiple collision-free grasp orientations. Experimental evaluations in simulation and on a real robotic bin picking setup demonstrate the model's ability to generalize across various object categories achieving an object clearing rate of around $90 \%$ in simulation and real-world experiments. We also outperform state of the art approaches. Moreover, the proposed approach exhibits its usability in real robot experiments without any refinement steps, even when only trained on a synthetic dataset, due to the probabilistic grasp distribution modeling.
Pseudo-Labeling and Contextual Curriculum Learning for Online Grasp Learning in Robotic Bin Picking
Mar 04, 2024



The prevailing grasp prediction methods predominantly rely on offline learning, overlooking the dynamic grasp learning that occurs during real-time adaptation to novel picking scenarios. These scenarios may involve previously unseen objects, variations in camera perspectives, and bin configurations, among other factors. In this paper, we introduce a novel approach, SSL-ConvSAC, that combines semi-supervised learning and reinforcement learning for online grasp learning. By treating pixels with reward feedback as labeled data and others as unlabeled, it efficiently exploits unlabeled data to enhance learning. In addition, we address the imbalance between labeled and unlabeled data by proposing a contextual curriculum-based method. We ablate the proposed approach on real-world evaluation data and demonstrate promise for improving online grasp learning on bin picking tasks using a physical 7-DoF Franka Emika robot arm with a suction gripper. Video: https://youtu.be/OAro5pg8I9U
Uncertainty-driven Exploration Strategies for Online Grasp Learning
Sep 21, 2023Existing grasp prediction approaches are mostly based on offline learning, while, ignored the exploratory grasp learning during online adaptation to new picking scenarios, i.e., unseen object portfolio, camera and bin settings etc. In this paper, we present a novel method for online learning of grasp predictions for robotic bin picking in a principled way. Existing grasp prediction approaches are mostly based on offline learning, while, ignored the exploratory grasp learning during online adaptation to new picking scenarios, i.e., unseen object portfolio, camera and bin settings etc. In this paper, we present a novel method for online learning of grasp predictions for robotic bin picking in a principled way. Specifically, the online learning algorithm with an effective exploration strategy can significantly improve its adaptation performance to unseen environment settings. To this end, we first propose to formulate online grasp learning as a RL problem that will allow to adapt both grasp reward prediction and grasp poses. We propose various uncertainty estimation schemes based on Bayesian Uncertainty Quantification and Distributional Ensembles. We carry out evaluations on real-world bin picking scenes of varying difficulty. The objects in the bin have various challenging physical and perceptual characteristics that can be characterized by semi- or total transparency, and irregular or curved surfaces. The results of our experiments demonstrate a notable improvement in the suggested approach compared to conventional online learning methods which incorporate only naive exploration strategies.
Model-free Grasping with Multi-Suction Cup Grippers for Robotic Bin Picking
Jul 31, 2023This paper presents a novel method for model-free prediction of grasp poses for suction grippers with multiple suction cups. Our approach is agnostic to the design of the gripper and does not require gripper-specific training data. In particular, we propose a two-step approach, where first, a neural network predicts pixel-wise grasp quality for an input image to indicate areas that are generally graspable. Second, an optimization step determines the optimal gripper selection and corresponding grasp poses based on configured gripper layouts and activation schemes. In addition, we introduce a method for automated labeling for supervised training of the grasp quality network. Experimental evaluations on a real-world industrial application with bin picking scenes of varying difficulty demonstrate the effectiveness of our method.
The e-Bike Motor Assembly: Towards Advanced Robotic Manipulation for Flexible Manufacturing
Apr 20, 2023



Robotic manipulation is currently undergoing a profound paradigm shift due to the increasing needs for flexible manufacturing systems, and at the same time, because of the advances in enabling technologies such as sensing, learning, optimization, and hardware. This demands for robots that can observe and reason about their workspace, and that are skillfull enough to complete various assembly processes in weakly-structured settings. Moreover, it remains a great challenge to enable operators for teaching robots on-site, while managing the inherent complexity of perception, control, motion planning and reaction to unexpected situations. Motivated by real-world industrial applications, this paper demonstrates the potential of such a paradigm shift in robotics on the industrial case of an e-Bike motor assembly. The paper presents a concept for teaching and programming adaptive robots on-site and demonstrates their potential for the named applications. The framework includes: (i) a method to teach perception systems onsite in a self-supervised manner, (ii) a general representation of object-centric motion skills and force-sensitive assembly skills, both learned from demonstration, (iii) a sequencing approach that exploits a human-designed plan to perform complex tasks, and (iv) a system solution for adapting and optimizing skills online. The aforementioned components are interfaced through a four-layer software architecture that makes our framework a tangible industrial technology. To demonstrate the generality of the proposed framework, we provide, in addition to the motivating e-Bike motor assembly, a further case study on dense box packing for logistics automation.
Learning Dense Visual Descriptors using Image Augmentations for Robot Manipulation Tasks
Sep 12, 2022

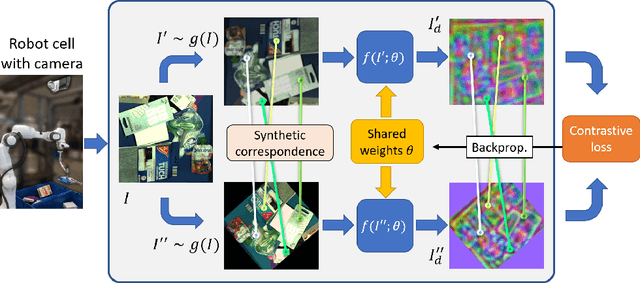

We propose a self-supervised training approach for learning view-invariant dense visual descriptors using image augmentations. Unlike existing works, which often require complex datasets, such as registered RGBD sequences, we train on an unordered set of RGB images. This allows for learning from a single camera view, e.g., in an existing robotic cell with a fix-mounted camera. We create synthetic views and dense pixel correspondences using data augmentations. We find our descriptors are competitive to the existing methods, despite the simpler data recording and setup requirements. We show that training on synthetic correspondences provides descriptor consistency across a broad range of camera views. We compare against training with geometric correspondence from multiple views and provide ablation studies. We also show a robotic bin-picking experiment using descriptors learned from a fix-mounted camera for defining grasp preferences.
Optimizing Demonstrated Robot Manipulation Skills for Temporal Logic Constraints
Sep 07, 2022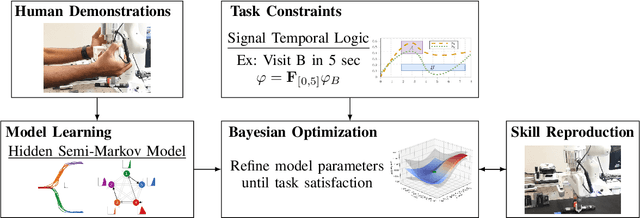

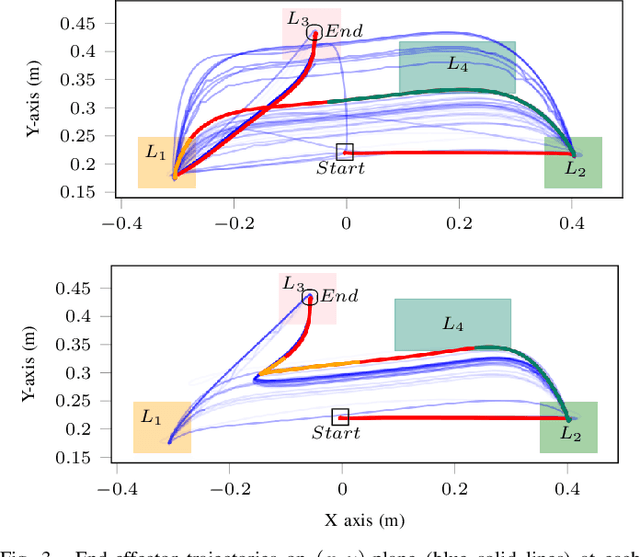

For performing robotic manipulation tasks, the core problem is determining suitable trajectories that fulfill the task requirements. Various approaches to compute such trajectories exist, being learning and optimization the main driving techniques. Our work builds on the learning-from-demonstration (LfD) paradigm, where an expert demonstrates motions, and the robot learns to imitate them. However, expert demonstrations are not sufficient to capture all sorts of task specifications, such as the timing to grasp an object. In this paper, we propose a new method that considers formal task specifications within LfD skills. Precisely, we leverage Signal Temporal Logic (STL), an expressive form of temporal properties of systems, to formulate task specifications and use black-box optimization (BBO) to adapt an LfD skill accordingly. We demonstrate our approach in simulation and on a real industrial setting using several tasks that showcase how our approach addresses the LfD limitations using STL and BBO.