 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Natural Language-Driven Assembly Using Foundation Models
Jun 23, 2024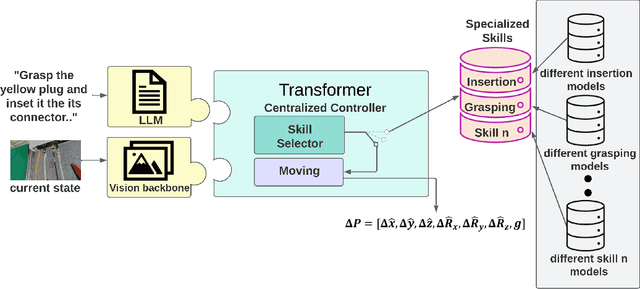
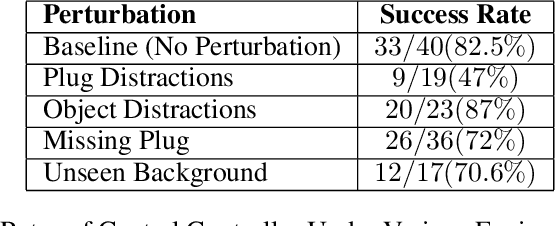
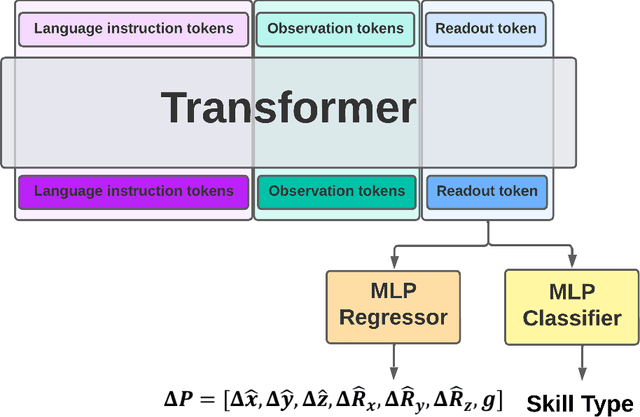

Large Language Models (LLMs) and strong vision models have enabled rapid research and development in the field of Vision-Language-Action models that enable robotic control. The main objective of these methods is to develop a generalist policy that can control robots with various embodiments. However, in industrial robotic applications such as automated assembly and disassembly, some tasks, such as insertion, demand greater accuracy and involve intricate factors like contact engagement, friction handling, and refined motor skills. Implementing these skills using a generalist policy is challenging because these policies might integrate further sensory data, including force or torque measurements, for enhanced precision. In our method, we present a global control policy based on LLMs that can transfer the control policy to a finite set of skills that are specifically trained to perform high-precision tasks through dynamic context switching. The integration of LLMs into this framework underscores their significance in not only interpreting and processing language inputs but also in enriching the control mechanisms for diverse and intricate robotic operations.
Uncertainty-driven Exploration Strategies for Online Grasp Learning
Sep 21, 2023Existing grasp prediction approaches are mostly based on offline learning, while, ignored the exploratory grasp learning during online adaptation to new picking scenarios, i.e., unseen object portfolio, camera and bin settings etc. In this paper, we present a novel method for online learning of grasp predictions for robotic bin picking in a principled way. Existing grasp prediction approaches are mostly based on offline learning, while, ignored the exploratory grasp learning during online adaptation to new picking scenarios, i.e., unseen object portfolio, camera and bin settings etc. In this paper, we present a novel method for online learning of grasp predictions for robotic bin picking in a principled way. Specifically, the online learning algorithm with an effective exploration strategy can significantly improve its adaptation performance to unseen environment settings. To this end, we first propose to formulate online grasp learning as a RL problem that will allow to adapt both grasp reward prediction and grasp poses. We propose various uncertainty estimation schemes based on Bayesian Uncertainty Quantification and Distributional Ensembles. We carry out evaluations on real-world bin picking scenes of varying difficulty. The objects in the bin have various challenging physical and perceptual characteristics that can be characterized by semi- or total transparency, and irregular or curved surfaces. The results of our experiments demonstrate a notable improvement in the suggested approach compared to conventional online learning methods which incorporate only naive exploration strategies.
A Hybrid Approach for Learning to Shift and Grasp with Elaborate Motion Primitives
Nov 02, 2021

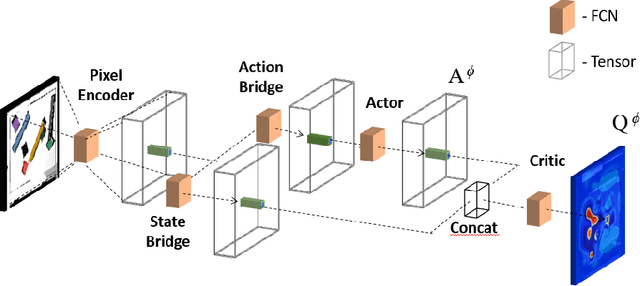

Many possible fields of application of robots in real world settings hinge on the ability of robots to grasp objects. As a result, robot grasping has been an active field of research for many years. With our publication we contribute to the endeavor of enabling robots to grasp, with a particular focus on bin picking applications. Bin picking is especially challenging due to the often cluttered and unstructured arrangement of objects and the often limited graspability of objects by simple top down grasps. To tackle these challenges, we propose a fully self-supervised reinforcement learning approach based on a hybrid discrete-continuous adaptation of soft actor-critic (SAC). We employ parametrized motion primitives for pushing and grasping movements in order to enable a flexibly adaptable behavior to the difficult setups we consider. Furthermore, we use data augmentation to increase sample efficiency. We demonnstrate our proposed method on challenging picking scenarios in which planar grasp learning or action discretization methods would face a lot of difficulties
SOLO: Search Online, Learn Offline for Combinatorial Optimization Problems
Apr 08, 2021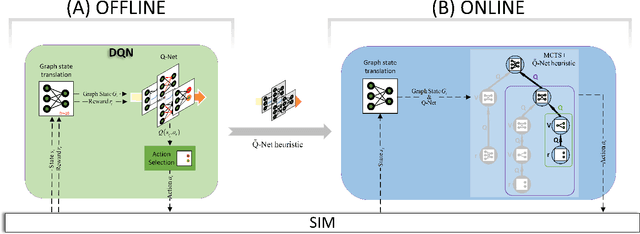
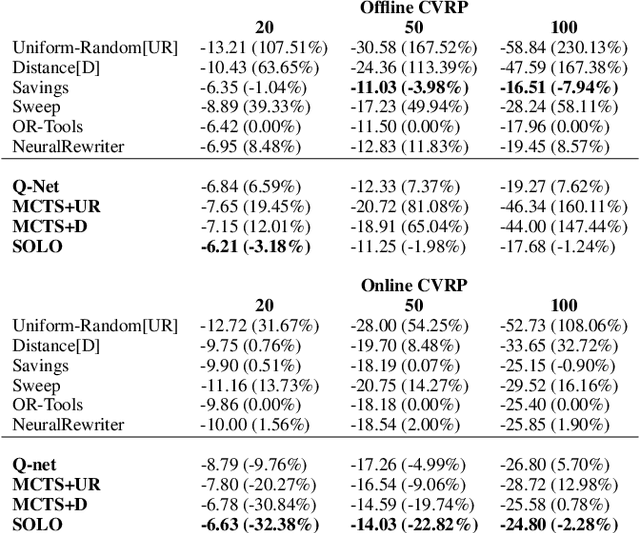

We study combinatorial problems with real world applications such as machine scheduling, routing, and assignment. We propose a method that combines Reinforcement Learning (RL) and planning. This method can equally be applied to both the offline, as well as online, variants of the combinatorial problem, in which the problem components (e.g., jobs in scheduling problems) are not known in advance, but rather arrive during the decision-making process. Our solution is quite generic, scalable, and leverages distributional knowledge of the problem parameters. We frame the solution process as an MDP, and take a Deep Q-Learning approach wherein states are represented as graphs, thereby allowing our trained policies to deal with arbitrary changes in a principled manner. Though learned policies work well in expectation, small deviations can have substantial negative effects in combinatorial settings. We mitigate these drawbacks by employing our graph-convolutional policies as non-optimal heuristics in a compatible search algorithm, Monte Carlo Tree Search, to significantly improve overall performance. We demonstrate our method on two problems: Machine Scheduling and Capacitated Vehicle Routing. We show that our method outperforms custom-tailored mathematical solvers, state of the art learning-based algorithms, and common heuristics, both in computation time and performance.
Monte-Carlo Planning: Theoretically Fast Convergence Meets Practical Efficiency
Sep 26, 2013
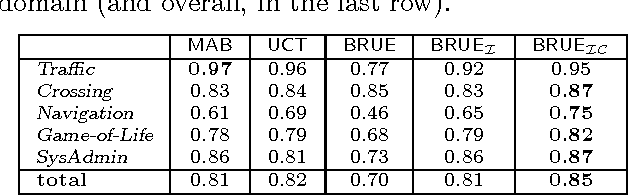

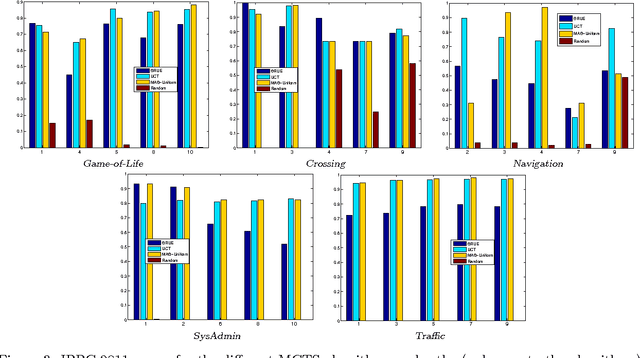
Popular Monte-Carlo tree search (MCTS) algorithms for online planning, such as epsilon-greedy tree search and UCT, aim at rapidly identifying a reasonably good action, but provide rather poor worst-case guarantees on performance improvement over time. In contrast, a recently introduced MCTS algorithm BRUE guarantees exponential-rate improvement over time, yet it is not geared towards identifying reasonably good choices right at the go. We take a stand on the individual strengths of these two classes of algorithms, and show how they can be effectively connected. We then rationalize a principle of "selective tree expansion", and suggest a concrete implementation of this principle within MCTS. The resulting algorithm,s favorably compete with other MCTS algorithms under short planning times, while preserving the attractive convergence properties of BRUE.
Simple Regret Optimization in Online Planning for Markov Decision Processes
Dec 19, 2012
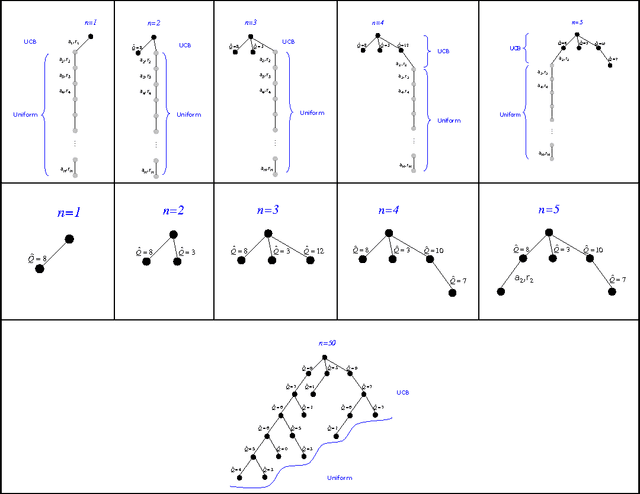
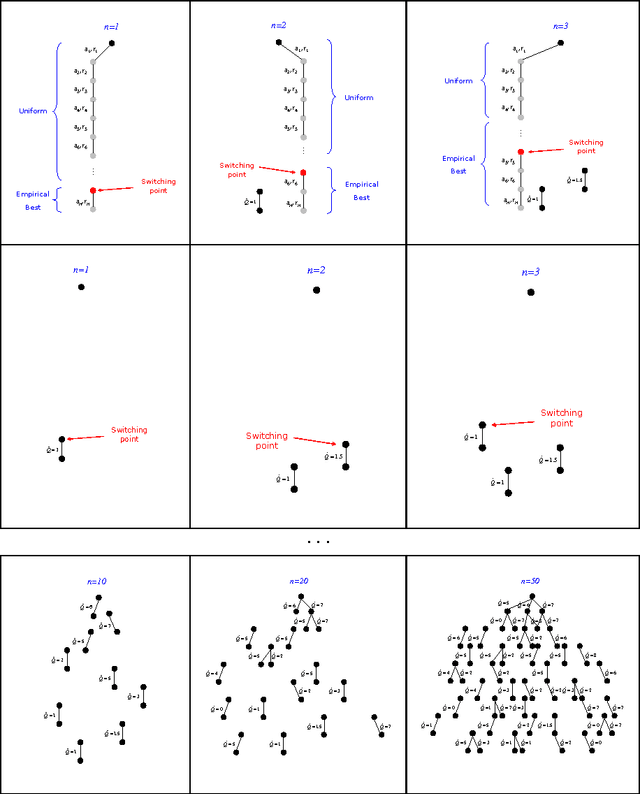
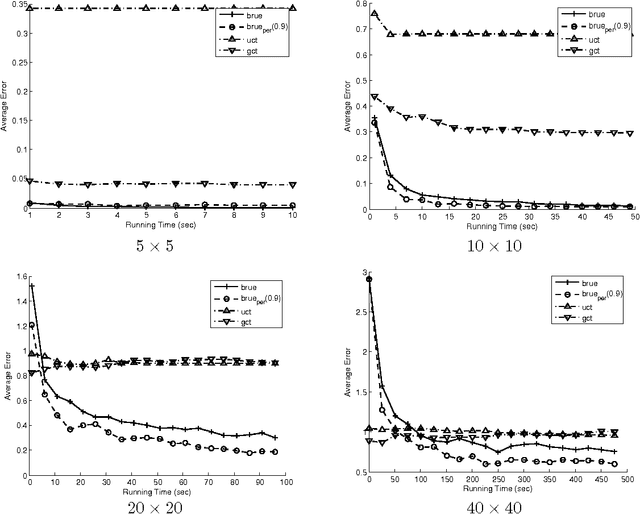
We consider online planning in Markov decision processes (MDPs). In online planning, the agent focuses on its current state only, deliberates about the set of possible policies from that state onwards and, when interrupted, uses the outcome of that exploratory deliberation to choose what action to perform next. The performance of algorithms for online planning is assessed in terms of simple regret, which is the agent's expected performance loss when the chosen action, rather than an optimal one, is followed. To date, state-of-the-art algorithms for online planning in general MDPs are either best effort, or guarantee only polynomial-rate reduction of simple regret over time. Here we introduce a new Monte-Carlo tree search algorithm, BRUE, that guarantees exponential-rate reduction of simple regret and error probability. This algorithm is based on a simple yet non-standard state-space sampling scheme, MCTS2e, in which different parts of each sample are dedicated to different exploratory objectives. Our empirical evaluation shows that BRUE not only provides superior performance guarantees, but is also very effective in practice and favorably compares to state-of-the-art. We then extend BRUE with a variant of "learning by forgetting." The resulting set of algorithms, BRUE(alpha), generalizes BRUE, improves the exponential factor in the upper bound on its reduction rate, and exhibits even more attractive empirical performance.