 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General Modality Translation with Contrastive and Predictive Latent Diffusion Bridge
Oct 23, 2025

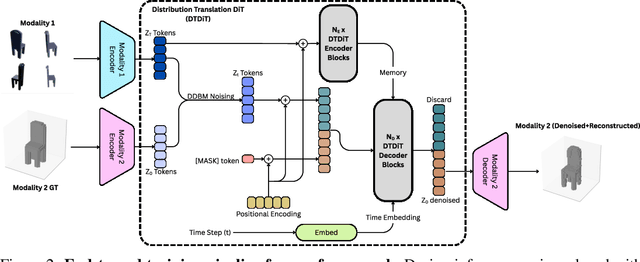

Recent advances in generative modeling have positioned diffusion models as state-of-the-art tools for sampling from complex data distributions. While these models have shown remarkable success across single-modality domains such as images and audio, extending their capabilities to Modality Translation (MT), translating information across different sensory modalities, remains an open challenge. Existing approaches often rely on restrictive assumptions, including shared dimensionality, Gaussian source priors, and modality-specific architectures, which limit their generality and theoretical grounding. In this work, we propose the Latent Denoising Diffusion Bridge Model (LDDBM), a general-purpose framework for modality translation based on a latent-variable extension of Denoising Diffusion Bridge Models. By operating in a shared latent space, our method learns a bridge between arbitrary modalities without requiring aligned dimensions. We introduce a contrastive alignment loss to enforce semantic consistency between paired samples and design a domain-agnostic encoder-decoder architecture tailored for noise prediction in latent space. Additionally, we propose a predictive loss to guide training toward accurate cross-domain translation and explore several training strategies to improve stability. Our approach supports arbitrary modality pairs and performs strongly on diverse MT tasks, including multi-view to 3D shape generation, image super-resolution, and multi-view scene synthesis. Comprehensive experiments and ablations validate the effectiveness of our framework, establishing a new strong baseline in general modality translation. For more information, see our project page: https://sites.google.com/view/lddbm/home.
Gradient-Free Neural Network Training on the Edge
Oct 13, 2024



Training neural networks is computationally heavy and energy-intensive. Many methodologies were developed to save computational requirements and energy by reducing the precision of network weights at inference time and introducing techniques such as rounding, stochastic rounding, and quantization. However, most of these techniques still require full gradient precision at training time, which makes training such models prohibitive on edge devices. This work presents a novel technique for training neural networks without needing gradients. This enables a training process where all the weights are one or two bits, without any hidden full precision computations. We show that it is possible to train models without gradient-based optimization techniques by identifying erroneous contributions of each neuron towards the expected classification and flipping the relevant bits using logical operations. We tested our method on several standard datasets and achieved performance comparable to corresponding gradient-based baselines with a fraction of the compute power.
Towards Natural Language-Driven Assembly Using Foundation Models
Jun 23, 2024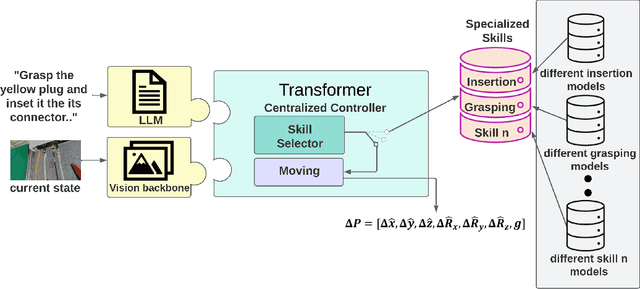
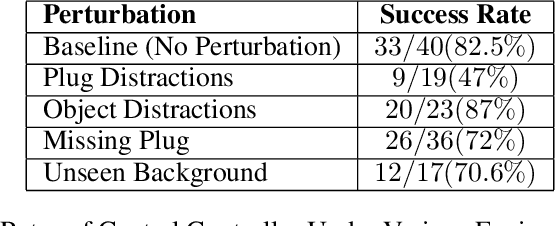
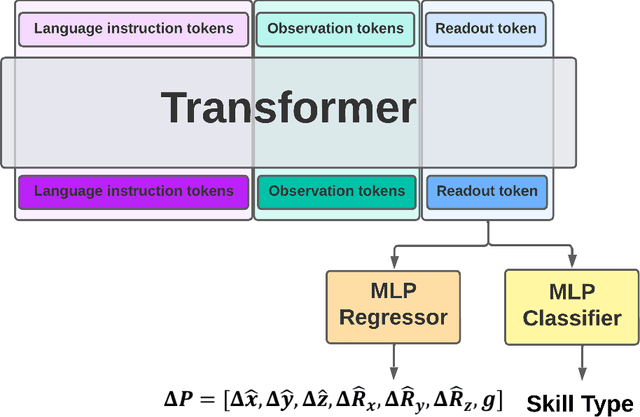

Large Language Models (LLMs) and strong vision models have enabled rapid research and development in the field of Vision-Language-Action models that enable robotic control. The main objective of these methods is to develop a generalist policy that can control robots with various embodiments. However, in industrial robotic applications such as automated assembly and disassembly, some tasks, such as insertion, demand greater accuracy and involve intricate factors like contact engagement, friction handling, and refined motor skills. Implementing these skills using a generalist policy is challenging because these policies might integrate further sensory data, including force or torque measurements, for enhanced precision. In our method, we present a global control policy based on LLMs that can transfer the control policy to a finite set of skills that are specifically trained to perform high-precision tasks through dynamic context switching. The integration of LLMs into this framework underscores their significance in not only interpreting and processing language inputs but also in enriching the control mechanisms for diverse and intricate robotic operations.
ISCUTE: Instance Segmentation of Cables Using Text Embedding
Feb 27, 2024In the field of robotics and automation, conventional object recognition and instance segmentation methods face a formidable challenge when it comes to perceiving Deformable Linear Objects (DLOs) like wires, cables, and flexible tubes. This challenge arises primarily from the lack of distinct attributes such as shape, color, and texture, which calls for tailored solutions to achieve precise identification. In this work, we propose a foundation model-based DLO instance segmentation technique that is text-promptable and user-friendly. Specifically, our approach combines the text-conditioned semantic segmentation capabilities of CLIPSeg model with the zero-shot generalization capabilities of Segment Anything Model (SAM). We show that our method exceeds SOTA performance on DLO instance segmentation, achieving a mIoU of $91.21\%$. We also introduce a rich and diverse DLO-specific dataset for instance segmentation.