 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe e-Bike Motor Assembly: Towards Advanced Robotic Manipulation for Flexible Manufacturing
Apr 20, 2023



Robotic manipulation is currently undergoing a profound paradigm shift due to the increasing needs for flexible manufacturing systems, and at the same time, because of the advances in enabling technologies such as sensing, learning, optimization, and hardware. This demands for robots that can observe and reason about their workspace, and that are skillfull enough to complete various assembly processes in weakly-structured settings. Moreover, it remains a great challenge to enable operators for teaching robots on-site, while managing the inherent complexity of perception, control, motion planning and reaction to unexpected situations. Motivated by real-world industrial applications, this paper demonstrates the potential of such a paradigm shift in robotics on the industrial case of an e-Bike motor assembly. The paper presents a concept for teaching and programming adaptive robots on-site and demonstrates their potential for the named applications. The framework includes: (i) a method to teach perception systems onsite in a self-supervised manner, (ii) a general representation of object-centric motion skills and force-sensitive assembly skills, both learned from demonstration, (iii) a sequencing approach that exploits a human-designed plan to perform complex tasks, and (iv) a system solution for adapting and optimizing skills online. The aforementioned components are interfaced through a four-layer software architecture that makes our framework a tangible industrial technology. To demonstrate the generality of the proposed framework, we provide, in addition to the motivating e-Bike motor assembly, a further case study on dense box packing for logistics automation.
Defect Transfer GAN: Diverse Defect Synthesis for Data Augmentation
Feb 16, 2023Data-hunger and data-imbalance are two major pitfalls in many deep learning approaches. For example, on highly optimized production lines, defective samples are hardly acquired while non-defective samples come almost for free. The defects however often seem to resemble each other, e.g., scratches on different products may only differ in a few characteristics. In this work, we introduce a framework, Defect Transfer GAN (DT-GAN), which learns to represent defect types independent of and across various background products and yet can apply defect-specific styles to generate realistic defective images. An empirical study on the MVTec AD and two additional datasets showcase DT-GAN outperforms state-of-the-art image synthesis methods w.r.t. sample fidelity and diversity in defect generation. We further demonstrate benefits for a critical downstream task in manufacturing -- defect classification. Results show that the augmented data from DT-GAN provides consistent gains even in the few samples regime and reduces the error rate up to 51% compared to both traditional and advanced data augmentation methods.
Qgraph-bounded Q-learning: Stabilizing Model-Free Off-Policy Deep Reinforcement Learning
Jul 15, 2020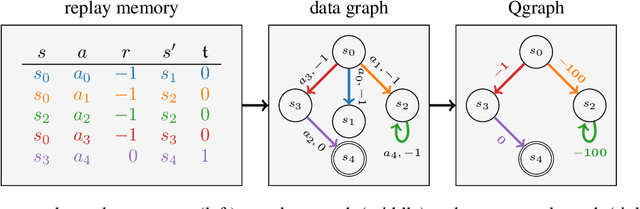
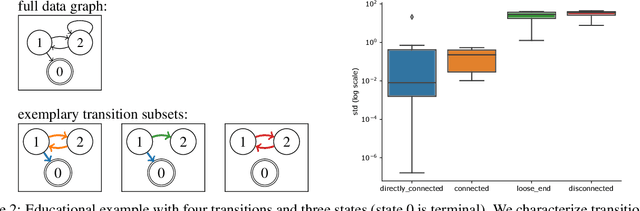

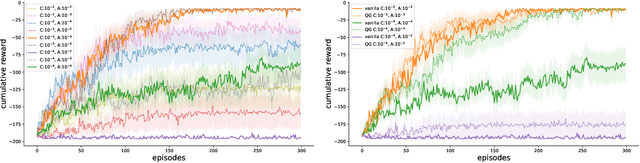
In state of the art model-free off-policy deep reinforcement learning, a replay memory is used to store past experience and derive all network updates. Even if both state and action spaces are continuous, the replay memory only holds a finite number of transitions. We represent these transitions in a data graph and link its structure to soft divergence. By selecting a subgraph with a favorable structure, we construct a simplified Markov Decision Process for which exact Q-values can be computed efficiently as more data comes in. The subgraph and its associated Q-values can be represented as a QGraph. We show that the Q-value for each transition in the simplified MDP is a lower bound of the Q-value for the same transition in the original continuous Q-learning problem. By using these lower bounds in temporal difference learning, our method QG-DDPG is less prone to soft divergence and exhibits increased sample efficiency while being more robust to hyperparameters. QGraphs also retain information from transitions that have already been overwritten in the replay memory, which can decrease the algorithm's sensitivity to the replay memory capacity.
End-to-End Eye Movement Detection Using Convolutional Neural Networks
Sep 08, 2016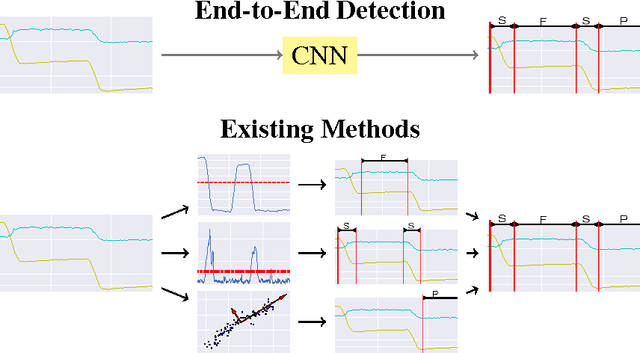
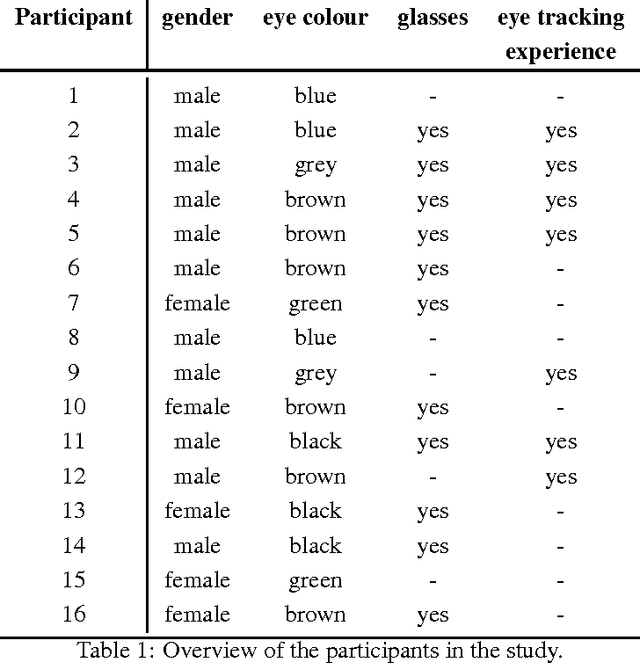

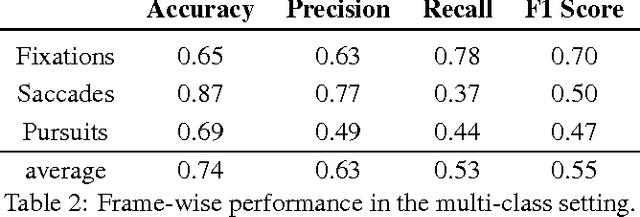
Common computational methods for automated eye movement detection - i.e. the task of detecting different types of eye movement in a continuous stream of gaze data - are limited in that they either involve thresholding on hand-crafted signal features, require individual detectors each only detecting a single movement, or require pre-segmented data. We propose a novel approach for eye movement detection that only involves learning a single detector end-to-end, i.e. directly from the continuous gaze data stream and simultaneously for different eye movements without any manual feature crafting or segmentation. Our method is based on convolutional neural networks (CNN) that recently demonstrated superior performance in a variety of tasks in computer vision, signal processing, and machine learning. We further introduce a novel multi-participant dataset that contains scripted and free-viewing sequences of ground-truth annotated saccades, fixations, and smooth pursuits. We show that our CNN-based method outperforms state-of-the-art baselines by a large margin on this challenging dataset, thereby underlining the significant potential of this approach for holistic, robust, and accurate eye movement protocol analysis.