 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-Critic Pretraining for Proximal Policy Optimization
Feb 27, 2026Reinforcement learning (RL) actor-critic algorithms enable autonomous learning but often require a large number of environment interactions, which limits their applicability in robotics. Leveraging expert data can reduce the number of required environment interactions. A common approach is actor pretraining, where the actor network is initialized via behavioral cloning on expert demonstrations and subsequently fine-tuned with RL. In contrast, the initialization of the critic network has received little attention, despite its central role in policy optimization. This paper proposes a pretraining approach for actor-critic algorithms like Proximal Policy Optimization (PPO) that uses expert demonstrations to initialize both networks. The actor is pretrained via behavioral cloning, while the critic is pretrained using returns obtained from rollouts of the pretrained policy. The approach is evaluated on 15 simulated robotic manipulation and locomotion tasks. Experimental results show that actor-critic pretraining improves sample efficiency by 86.1% on average compared to no pretraining and by 30.9% to actor-only pretraining.
Behavioral Cloning for Robotic Connector Assembly: An Empirical Study
Feb 25, 2026Automating the assembly of wire harnesses is challenging in automotive, electrical cabinet, and aircraft production, particularly due to deformable cables and a high variance in connector geometries. In addition, connectors must be inserted with limited force to avoid damage, while their poses can vary significantly. While humans can do this task intuitively by combining visual and haptic feedback, programming an industrial robot for such a task in an adaptable manner remains difficult. This work presents an empirical study investigating the suitability of behavioral cloning for learning an action prediction model for connector insertion that fuses force-torque sensing with a fixed position camera. We compare several network architectures and other design choices using a dataset of up to 300 successful human demonstrations collected via teleoperation of a UR5e robot with a SpaceMouse under varying connector poses. The resulting system is then evaluated against five different connector geometries under varying connector poses, achieving an overall insertion success rate of over 90 %.
Simulation-based Learning of Electrical Cabinet Assembly Using Robot Skills
Feb 16, 2026This paper presents a simulation-driven approach for automating the force-controlled assembly of electrical terminals on DIN-rails, a task traditionally hindered by high programming effort and product variability. The proposed method integrates deep reinforcement learning (DRL) with parameterizable robot skills in a physics-based simulation environment. To realistically model the snap-fit assembly process, we develop and evaluate two types of joining models: analytical models based on beam theory and rigid-body models implemented in the MuJoCo physics engine. These models enable accurate simulation of interaction forces, essential for training DRL agents. The robot skills are structured using the pitasc framework, allowing modular, reusable control strategies. Training is conducted in simulation using Soft Actor-Critic (SAC) and Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithms. Domain randomization is applied to improve robustness. The trained policies are transferred to a physical UR10e robot system without additional tuning. Experimental results demonstrate high success rates (up to 100%) in both simulation and real-world settings, even under significant positional and rotational deviations. The system generalizes well to new terminal types and positions, significantly reducing manual programming effort. This work highlights the potential of combining simulation-based learning with modular robot skills for flexible, scalable automation in small-batch manufacturing. Future work will explore hybrid learning methods, automated environment parameterization, and further refinement of joining models for design integration.
From Overfitting to Reliability: Introducing the Hierarchical Approximate Bayesian Neural Network
Dec 15, 2025In recent years, neural networks have revolutionized various domains, yet challenges such as hyperparameter tuning and overfitting remain significant hurdles. Bayesian neural networks offer a framework to address these challenges by incorporating uncertainty directly into the model, yielding more reliable predictions, particularly for out-of-distribution data. This paper presents Hierarchical Approximate Bayesian Neural Network, a novel approach that uses a Gaussian-inverse-Wishart distribution as a hyperprior of the network's weights to increase both the robustness and performance of the model. We provide analytical representations for the predictive distribution and weight posterior, which amount to the calculation of the parameters of Student's t-distributions in closed form with linear complexity with respect to the number of weights. Our method demonstrates robust performance, effectively addressing issues of overfitting and providing reliable uncertainty estimates, particularly for out-of-distribution tasks. Experimental results indicate that HABNN not only matches but often outperforms state-of-the-art models, suggesting a promising direction for future applications in safety-critical environments.
Efficiently Transforming Neural Networks into Decision Trees: A Path to Ground Truth Explanations with RENTT
Nov 12, 2025Although neural networks are a powerful tool, their widespread use is hindered by the opacity of their decisions and their black-box nature, which result in a lack of trustworthiness. To alleviate this problem, methods in the field of explainable Artificial Intelligence try to unveil how such automated decisions are made. But explainable AI methods are often plagued by missing faithfulness/correctness, meaning that they sometimes provide explanations that do not align with the neural network's decision and logic. Recently, transformations to decision trees have been proposed to overcome such problems. Unfortunately, they typically lack exactness, scalability, or interpretability as the size of the neural network grows. Thus, we generalize these previous results, especially by considering convolutional neural networks, recurrent neural networks, non-ReLU activation functions, and bias terms. Our findings are accompanied by rigorous proofs and we present a novel algorithm RENTT (Runtime Efficient Network to Tree Transformation) designed to compute an exact equivalent decision tree representation of neural networks in a manner that is both runtime and memory efficient. The resulting decision trees are multivariate and thus, possibly too complex to understand. To alleviate this problem, we also provide a method to calculate the ground truth feature importance for neural networks via the equivalent decision trees - for entire models (global), specific input regions (regional), or single decisions (local). All theoretical results are supported by detailed numerical experiments that emphasize two key aspects: the computational efficiency and scalability of our algorithm, and that only RENTT succeeds in uncovering ground truth explanations compared to conventional approximation methods like LIME and SHAP. All code is available at https://github.com/HelenaM23/RENTT .
From Confusion to Clarity: ProtoScore -- A Framework for Evaluating Prototype-Based XAI
Nov 11, 2025The complexity and opacity of neural networks (NNs) pose significant challenges, particularly in high-stakes fields such as healthcare, finance, and law, where understanding decision-making processes is crucial. To address these issues, the field of explainable artificial intelligence (XAI) has developed various methods aimed at clarifying AI decision-making, thereby facilitating appropriate trust and validating the fairness of outcomes. Among these methods, prototype-based explanations offer a promising approach that uses representative examples to elucidate model behavior. However, a critical gap exists regarding standardized benchmarks to objectively compare prototype-based XAI methods, especially in the context of time series data. This lack of reliable benchmarks results in subjective evaluations, hindering progress in the field. We aim to establish a robust framework, ProtoScore, for assessing prototype-based XAI methods across different data types with a focus on time series data, facilitating fair and comprehensive evaluations. By integrating the Co-12 properties of Nauta et al., this framework allows for effectively comparing prototype methods against each other and against other XAI methods, ultimately assisting practitioners in selecting appropriate explanation methods while minimizing the costs associated with user studies. All code is publicly available at https://github.com/HelenaM23/ProtoScore .
ViPro-2: Unsupervised State Estimation via Integrated Dynamics for Guiding Video Prediction
Aug 08, 2025Predicting future video frames is a challenging task with many downstream applications. Previous work has shown that procedural knowledge enables deep models for complex dynamical settings, however their model ViPro assumed a given ground truth initial symbolic state. We show that this approach led to the model learning a shortcut that does not actually connect the observed environment with the predicted symbolic state, resulting in the inability to estimate states given an observation if previous states are noisy. In this work, we add several improvements to ViPro that enables the model to correctly infer states from observations without providing a full ground truth state in the beginning. We show that this is possible in an unsupervised manner, and extend the original Orbits dataset with a 3D variant to close the gap to real world scenarios.
Causal Mechanism Estimation in Multi-Sensor Systems Across Multiple Domains
Jul 23, 2025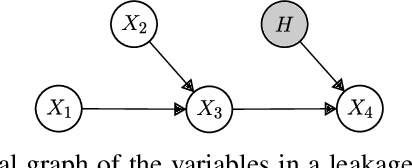
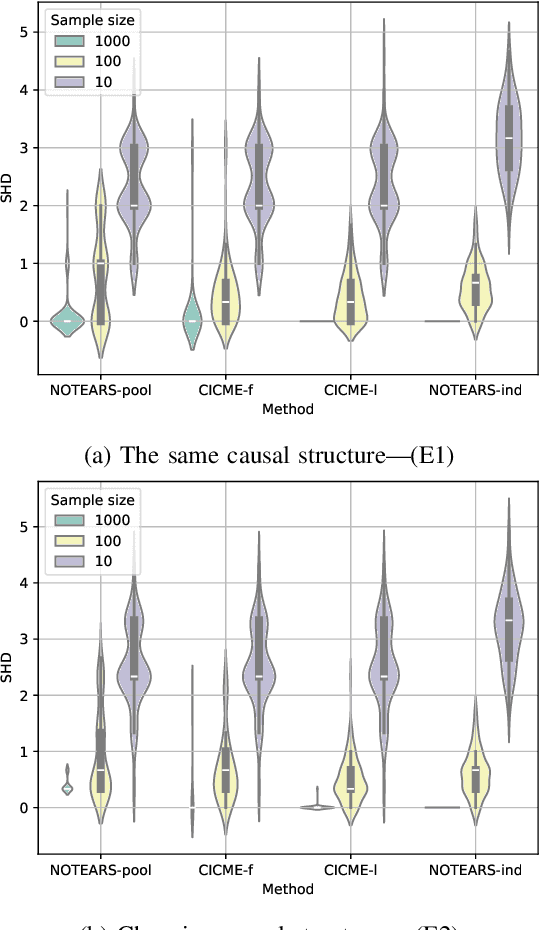
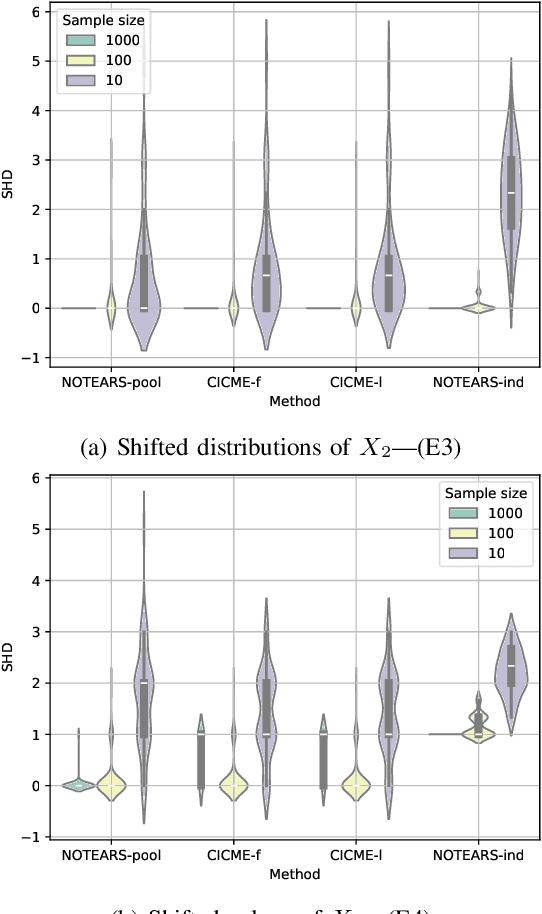
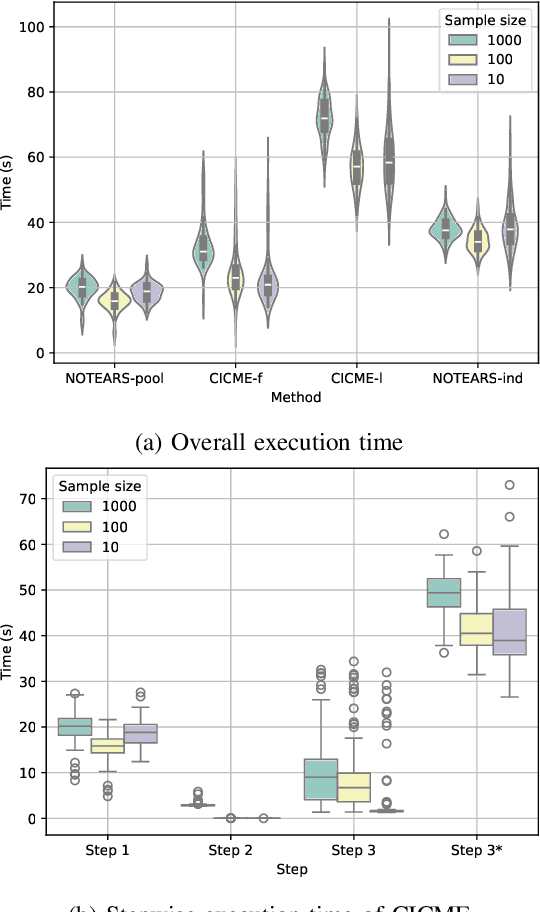
To gain deeper insights into a complex sensor system through the lens of causality, we present common and individual causal mechanism estimation (CICME), a novel three-step approach to inferring causal mechanisms from heterogeneous data collected across multiple domains. By leveraging the principle of Causal Transfer Learning (CTL), CICME is able to reliably detect domain-invariant causal mechanisms when provided with sufficient samples. The identified common causal mechanisms are further used to guide the estimation of the remaining causal mechanisms in each domain individually. The performance of CICME is evaluated on linear Gaussian models under scenarios inspired from a manufacturing process. Building upon existing continuous optimization-based causal discovery methods, we show that CICME leverages the benefits of applying causal discovery on the pooled data and repeatedly on data from individual domains, and it even outperforms both baseline methods under certain scenarios.
Generative Adversarial Networks with Limited Data: A Survey and Benchmarking
Apr 07, 2025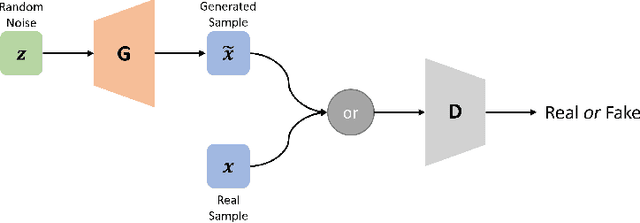
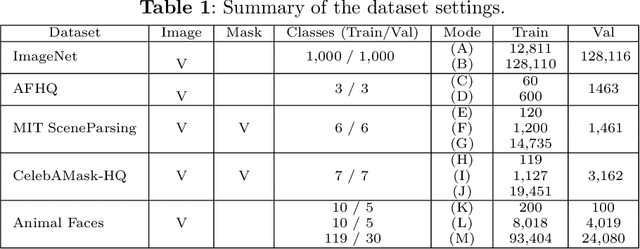
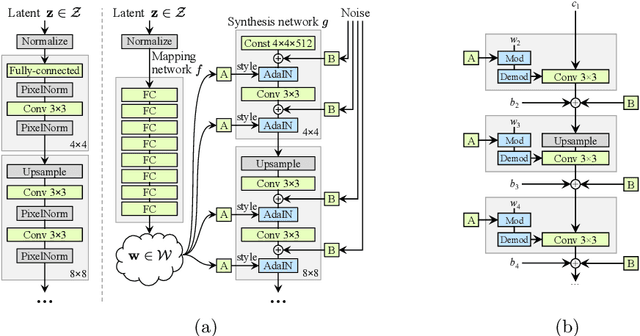
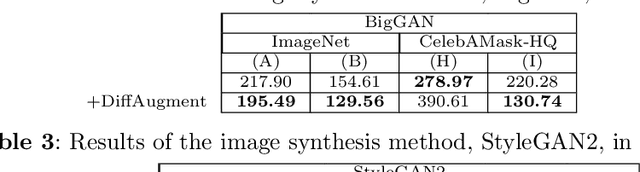
Generative Adversarial Networks (GANs) have shown impressive results in various image synthesis tasks. Vast studies have demonstrated that GANs are more powerful in feature and expression learning compared to other generative models and their latent space encodes rich semantic information. However, the tremendous performance of GANs heavily relies on the access to large-scale training data and deteriorates rapidly when the amount of data is limited. This paper aims to provide an overview of GANs, its variants and applications in various vision tasks, focusing on addressing the limited data issue. We analyze state-of-the-art GANs in limited data regime with designed experiments, along with presenting various methods attempt to tackle this problem from different perspectives. Finally, we further elaborate on remaining challenges and trends for future research.
Sample-Efficient Bayesian Transfer Learning for Online Machine Parameter Optimization
Mar 21, 2025
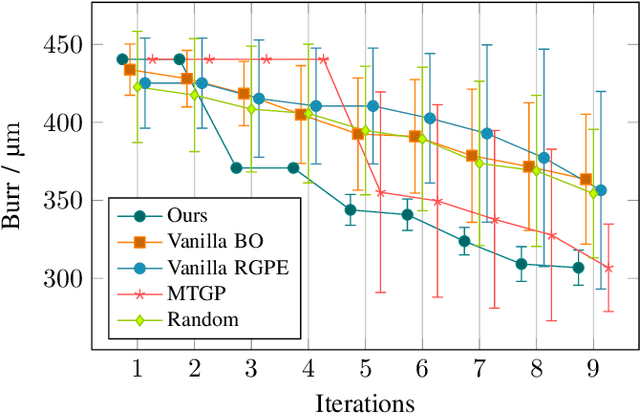
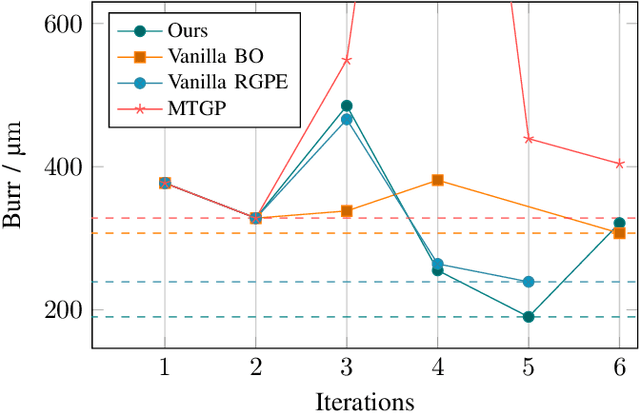
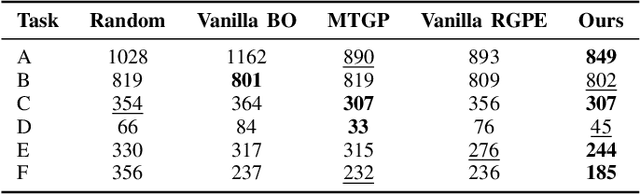
Correctly setting the parameters of a production machine is essential to improve product quality, increase efficiency, and reduce production costs while also supporting sustainability goals. Identifying optimal parameters involves an iterative process of producing an object and evaluating its quality. Minimizing the number of iterations is, therefore, desirable to reduce the costs associated with unsuccessful attempts. This work introduces a method to optimize the machine parameters in the system itself using a Bayesian optimization algorithm. By leveraging existing machine data, we use a transfer learning approach in order to identify an optimum with minimal iterations, resulting in a cost-effective transfer learning algorithm. We validate our approach on a laser machine for cutting sheet metal in the real world.