 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIPer: A Human-Inspired Scene Perception Model for Multifunctional Mobile Robots
Apr 27, 2024Taking over arbitrary tasks like humans do with a mobile service robot in open-world settings requires a holistic scene perception for decision-making and high-level control. This paper presents a human-inspired scene perception model to minimize the gap between human and robotic capabilities. The approach takes over fundamental neuroscience concepts, such as a triplet perception split into recognition, knowledge representation, and knowledge interpretation. A recognition system splits the background and foreground to integrate exchangeable image-based object detectors and SLAM, a multi-layer knowledge base represents scene information in a hierarchical structure and offers interfaces for high-level control, and knowledge interpretation methods deploy spatio-temporal scene analysis and perceptual learning for self-adjustment. A single-setting ablation study is used to evaluate the impact of each component on the overall performance for a fetch-and-carry scenario in two simulated and one real-world environment.
Towards Packaging Unit Detection for Automated Palletizing Tasks
Aug 11, 2023For various automated palletizing tasks, the detection of packaging units is a crucial step preceding the actual handling of the packaging units by an industrial robot. We propose an approach to this challenging problem that is fully trained on synthetically generated data and can be robustly applied to arbitrary real world packaging units without further training or setup effort. The proposed approach is able to handle sparse and low quality sensor data, can exploit prior knowledge if available and generalizes well to a wide range of products and application scenarios. To demonstrate the practical use of our approach, we conduct an extensive evaluation on real-world data with a wide range of different retail products. Further, we integrated our approach in a lab demonstrator and a commercial solution will be marketed through an industrial partner.
Precise Object Placement with Pose Distance Estimations for Different Objects and Grippers
Oct 03, 2021
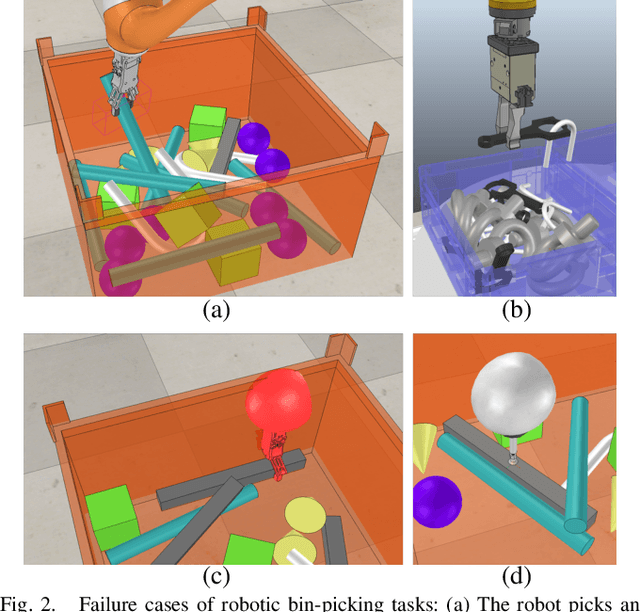

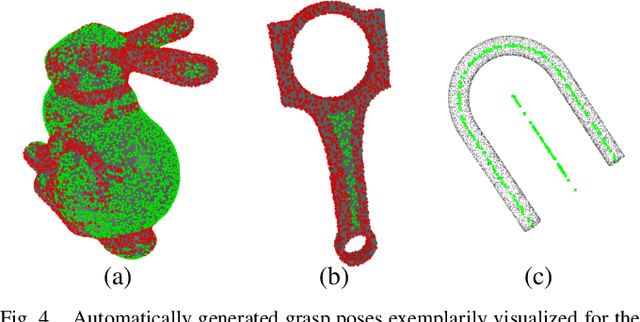
This paper introduces a novel approach for the grasping and precise placement of various known rigid objects using multiple grippers within highly cluttered scenes. Using a single depth image of the scene, our method estimates multiple 6D object poses together with an object class, a pose distance for object pose estimation, and a pose distance from a target pose for object placement for each automatically obtained grasp pose with a single forward pass of a neural network. By incorporating model knowledge into the system, our approach has higher success rates for grasping than state-of-the-art model-free approaches. Furthermore, our method chooses grasps that result in significantly more precise object placements than prior model-based work.
Deep Workpiece Region Segmentation for Bin Picking
Sep 08, 2019



For most industrial bin picking solutions, the pose of a workpiece is localized by matching a CAD model to point cloud obtained from 3D sensor. Distinguishing flat workpieces from bottom of the bin in point cloud imposes challenges in the localization of workpieces that lead to wrong or phantom detections. In this paper, we propose a framework that solves this problem by automatically segmenting workpiece regions from non-workpiece regions in a point cloud data. It is done in real time by applying a fully convolutional neural network trained on both simulated and real data. The real data has been labelled by our novel technique which automatically generates ground truth labels for real point clouds. Along with real time workpiece segmentation, our framework also helps in improving the number of detected workpieces and estimating the correct object poses. Moreover, it decreases the computation time by approximately 1s due to a reduction of the search space for the object pose estimation.