 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Blind Source Separation with Dissociative Principal Component Analysis
Nov 19, 2024



Sparse principal component analysis (sPCA) enhances the interpretability of principal components (PCs) by imposing sparsity constraints on loading vectors (LVs). However, when used as a precursor to independent component analysis (ICA) for blind source separation (BSS), sPCA may underperform due to its focus on simplicity, potentially disregarding some statistical information essential for effective ICA. To overcome this limitation, a sophisticated approach is proposed that preserves the interpretability advantages of sPCA while significantly enhancing its source extraction capabilities. This consists of two tailored algorithms, dissociative PCA (DPCA1 and DPCA2), which employ adaptive and firm thresholding alongside gradient and coordinate descent approaches to optimize the proposed model dynamically. These algorithms integrate left and right singular vectors from singular value decomposition (SVD) through dissociation matrices (DMs) that replace traditional singular values, thus capturing latent interdependencies effectively to model complex source relationships. This leads to refined PCs and LVs that more accurately represent the underlying data structure. The proposed approach avoids focusing on individual eigenvectors, instead, it collaboratively combines multiple eigenvectors to disentangle interdependencies within each SVD variate. The superior performance of the proposed DPCA algorithms is demonstrated across four varied imaging applications including functional magnetic resonance imaging (fMRI) source retrieval, foreground-background separation, image reconstruction, and image inpainting. They outperformed traditional methods such as PCA+ICA, PPCA+ICA, SPCA+ICA, PMD, and GPower.
Precise Object Placement with Pose Distance Estimations for Different Objects and Grippers
Oct 03, 2021
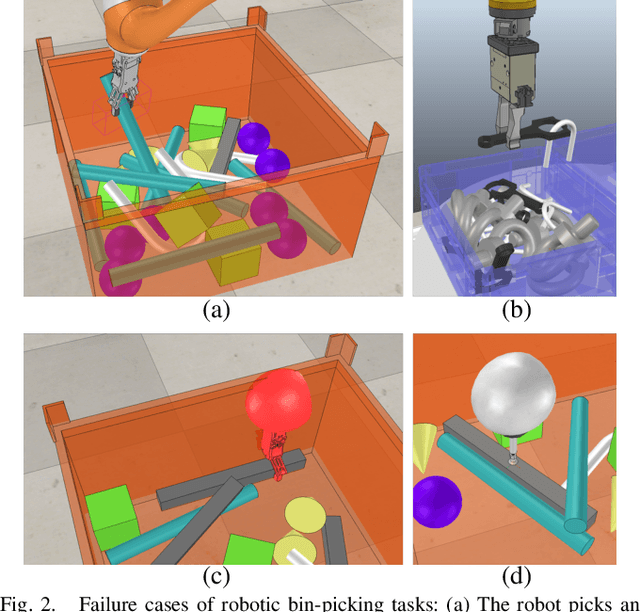

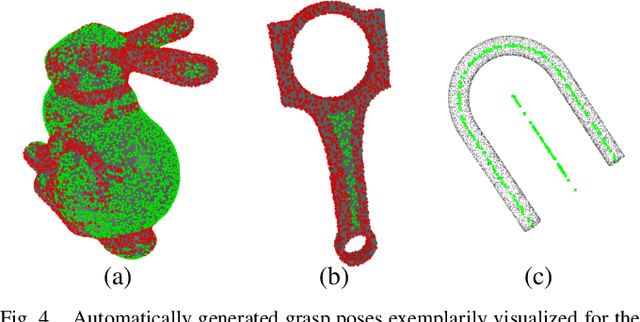
This paper introduces a novel approach for the grasping and precise placement of various known rigid objects using multiple grippers within highly cluttered scenes. Using a single depth image of the scene, our method estimates multiple 6D object poses together with an object class, a pose distance for object pose estimation, and a pose distance from a target pose for object placement for each automatically obtained grasp pose with a single forward pass of a neural network. By incorporating model knowledge into the system, our approach has higher success rates for grasping than state-of-the-art model-free approaches. Furthermore, our method chooses grasps that result in significantly more precise object placements than prior model-based work.
Multi-Modal Three-Stream Network for Action Recognition
Sep 08, 2019


Human action recognition in video is an active yet challenging research topic due to high variation and complexity of data. In this paper, a novel video based action recognition framework utilizing complementary cues is proposed to handle this complex problem. Inspired by the successful two stream networks for action classification, additional pose features are studied and fused to enhance understanding of human action in a more abstract and semantic way. Towards practices, not only ground truth poses but also noisy estimated poses are incorporated in the framework with our proposed pre-processing module. The whole framework and each cue are evaluated on varied benchmarking datasets as JHMDB, sub-JHMDB and Penn Action. Our results outperform state-of-the-art performance on these datasets and show the strength of complementary cues.
Deep Workpiece Region Segmentation for Bin Picking
Sep 08, 2019



For most industrial bin picking solutions, the pose of a workpiece is localized by matching a CAD model to point cloud obtained from 3D sensor. Distinguishing flat workpieces from bottom of the bin in point cloud imposes challenges in the localization of workpieces that lead to wrong or phantom detections. In this paper, we propose a framework that solves this problem by automatically segmenting workpiece regions from non-workpiece regions in a point cloud data. It is done in real time by applying a fully convolutional neural network trained on both simulated and real data. The real data has been labelled by our novel technique which automatically generates ground truth labels for real point clouds. Along with real time workpiece segmentation, our framework also helps in improving the number of detected workpieces and estimating the correct object poses. Moreover, it decreases the computation time by approximately 1s due to a reduction of the search space for the object pose estimation.