 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Contribution of XAI for the Safe Development and Certification of AI: An Expert-Based Analysis
Jul 22, 2024Developing and certifying safe - or so-called trustworthy - AI has become an increasingly salient issue, especially in light of upcoming regulation such as the EU AI Act. In this context, the black-box nature of machine learning models limits the use of conventional avenues of approach towards certifying complex technical systems. As a potential solution, methods to give insights into this black-box - devised in the field of eXplainable AI (XAI) - could be used. In this study, the potential and shortcomings of such methods for the purpose of safe AI development and certification are discussed in 15 qualitative interviews with experts out of the areas of (X)AI and certification. We find that XAI methods can be a helpful asset for safe AI development, as they can show biases and failures of ML-models, but since certification relies on comprehensive and correct information about technical systems, their impact is expected to be limited.
Machine Learning Techniques for Software Quality Assurance: A Survey
Apr 29, 2021
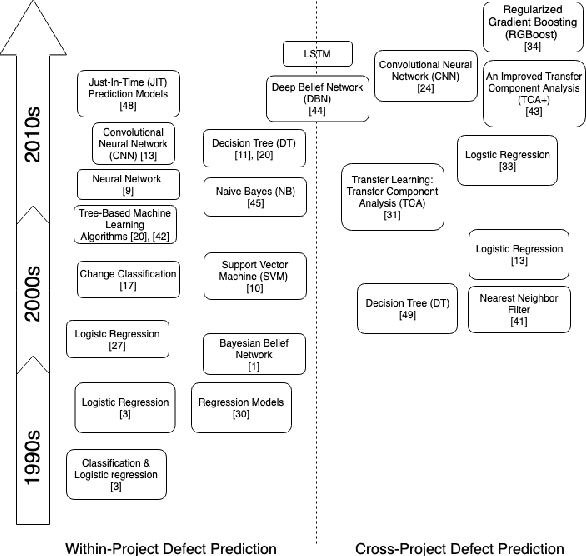
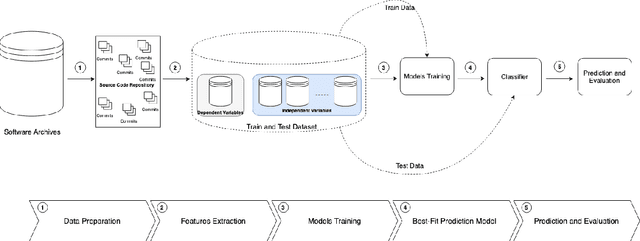
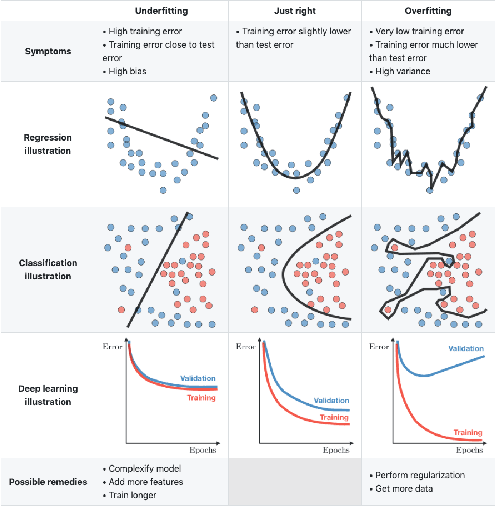
Over the last years, machine learning techniques have been applied to more and more application domains, including software engineering and, especially, software quality assurance. Important application domains have been, e.g., software defect prediction or test case selection and prioritization. The ability to predict which components in a large software system are most likely to contain the largest numbers of faults in the next release helps to better manage projects, including early estimation of possible release delays, and affordably guide corrective actions to improve the quality of the software. However, developing robust fault prediction models is a challenging task and many techniques have been proposed in the literature. Closely related to estimating defect-prone parts of a software system is the question of how to select and prioritize test cases, and indeed test case prioritization has been extensively researched as a means for reducing the time taken to discover regressions in software. In this survey, we discuss various approaches in both fault prediction and test case prioritization, also explaining how in recent studies deep learning algorithms for fault prediction help to bridge the gap between programs' semantics and fault prediction features. We also review recently proposed machine learning methods for test case prioritization (TCP), and their ability to reduce the cost of regression testing without negatively affecting fault detection capabilities.