 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncrypted Neural Networks without Overflows
May 21, 2026Fully homomorphic encryption (FHE) enables private inference by evaluating neural networks on encrypted data. In this way, we can delegate the computation to a third party server without ever revealing the user's data. Currently, the CKKS scheme is the backbone of most efficient FHE implementations, but it only supports addition, multiplication, and array rotation operations, thus requiring all activation functions of the neural network to be approximated by polynomials within a certain interval, imposing strict design tolerances. In this paper, we demonstrate for the first time that this scheme is vulnerable to overflow attacks, i.e., seemingly benign inputs that can exceed such tolerances of the FHE circuit, thereby causing corrupt and unusable outputs. To avoid them, we propose a formal verification technique that computes certified bounds on the ranges of all neurons in the network. By construction, our method eliminates overflows and, in our experiments, removed observed overflows on all benchmarks, reducing failure rates from up to 47% to 0%. Moreover, our overflow-free solution is compatible with most CKKS-based frameworks, as it allows to simply substitute standard polynomials by polynomials with rigorously designed ranges.
Optimized Symbolic Interval Propagation for Neural Network Verification
Dec 15, 2022Neural networks are increasingly applied in safety critical domains, their verification thus is gaining importance. A large class of recent algorithms for proving input-output relations of feed-forward neural networks are based on linear relaxations and symbolic interval propagation. However, due to variable dependencies, the approximations deteriorate with increasing depth of the network. In this paper we present DPNeurifyFV, a novel branch-and-bound solver for ReLU networks with low dimensional input-space that is based on symbolic interval propagation with fresh variables and input-splitting. A new heuristic for choosing the fresh variables allows to ameliorate the dependency problem, while our novel splitting heuristic, in combination with several other improvements, speeds up the branch-and-bound procedure. We evaluate our approach on the airborne collision avoidance networks ACAS Xu and demonstrate runtime improvements compared to state-of-the-art tools.
Geometric Path Enumeration for Equivalence Verification of Neural Networks
Dec 13, 2021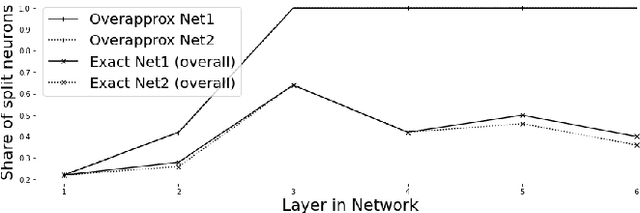
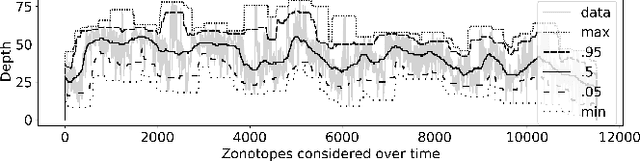
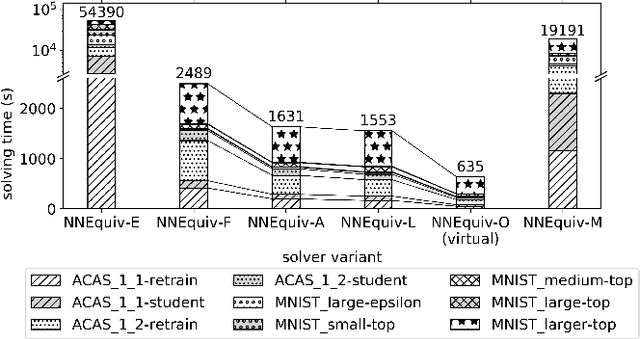
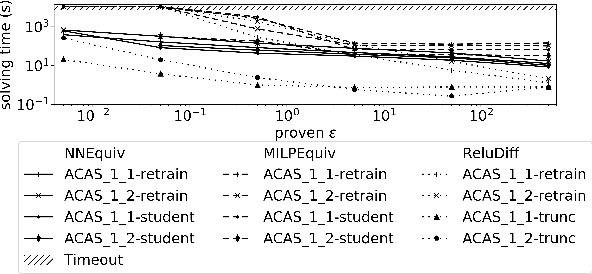
As neural networks (NNs) are increasingly introduced into safety-critical domains, there is a growing need to formally verify NNs before deployment. In this work we focus on the formal verification problem of NN equivalence which aims to prove that two NNs (e.g. an original and a compressed version) show equivalent behavior. Two approaches have been proposed for this problem: Mixed integer linear programming and interval propagation. While the first approach lacks scalability, the latter is only suitable for structurally similar NNs with small weight changes. The contribution of our paper has four parts. First, we show a theoretical result by proving that the epsilon-equivalence problem is coNP-complete. Secondly, we extend Tran et al.'s single NN geometric path enumeration algorithm to a setting with multiple NNs. In a third step, we implement the extended algorithm for equivalence verification and evaluate optimizations necessary for its practical use. Finally, we perform a comparative evaluation showing use-cases where our approach outperforms the previous state of the art, both, for equivalence verification as well as for counter-example finding.
* Paper presented at The 33rd IEEE International Conference on Tools with Artificial Intelligence (ICTAI)
Machine Learning Techniques for Software Quality Assurance: A Survey
Apr 29, 2021
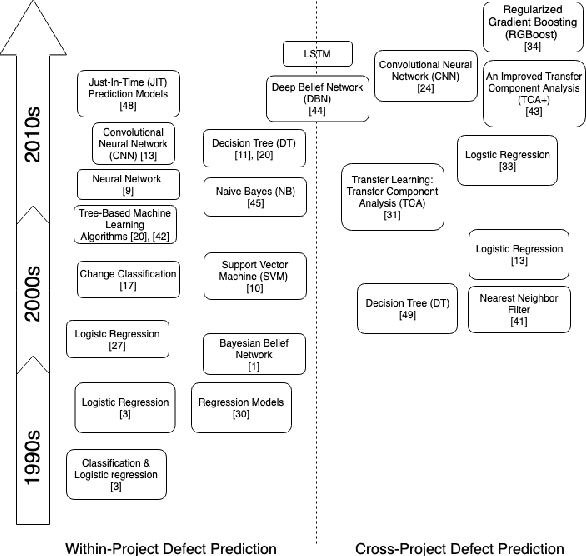
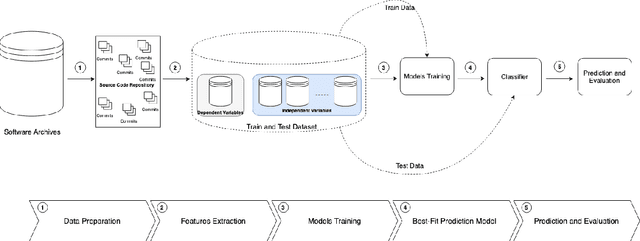
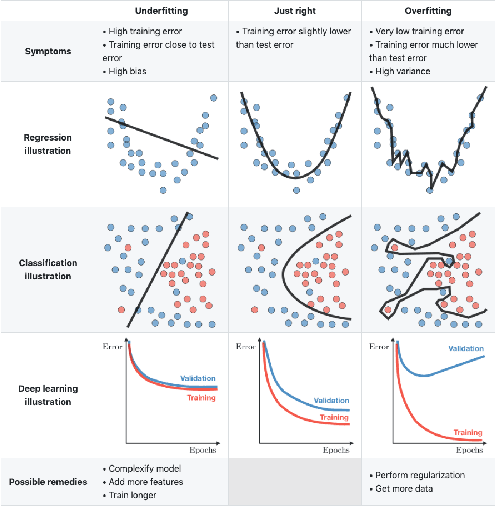
Over the last years, machine learning techniques have been applied to more and more application domains, including software engineering and, especially, software quality assurance. Important application domains have been, e.g., software defect prediction or test case selection and prioritization. The ability to predict which components in a large software system are most likely to contain the largest numbers of faults in the next release helps to better manage projects, including early estimation of possible release delays, and affordably guide corrective actions to improve the quality of the software. However, developing robust fault prediction models is a challenging task and many techniques have been proposed in the literature. Closely related to estimating defect-prone parts of a software system is the question of how to select and prioritize test cases, and indeed test case prioritization has been extensively researched as a means for reducing the time taken to discover regressions in software. In this survey, we discuss various approaches in both fault prediction and test case prioritization, also explaining how in recent studies deep learning algorithms for fault prediction help to bridge the gap between programs' semantics and fault prediction features. We also review recently proposed machine learning methods for test case prioritization (TCP), and their ability to reduce the cost of regression testing without negatively affecting fault detection capabilities.
Collaborative Management of Benchmark Instances and their Attributes
Sep 07, 2020



Experimental evaluation is an integral part in the design process of algorithms. Publicly available benchmark instances are widely used to evaluate methods in SAT solving. For the interpretation of results and the design of algorithm portfolios their attributes are crucial. Capturing the interrelation of benchmark instances and their attributes is considerably simplified through our specification of a benchmark instance identifier. Thus, our tool increases the availability of both by providing means to manage and retrieve benchmark instances by their attributes and vice versa. Like this, it facilitates the design and analysis of SAT experiments and the exchange of results.