 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Mechanism Estimation in Multi-Sensor Systems Across Multiple Domains
Jul 23, 2025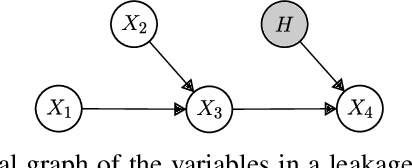
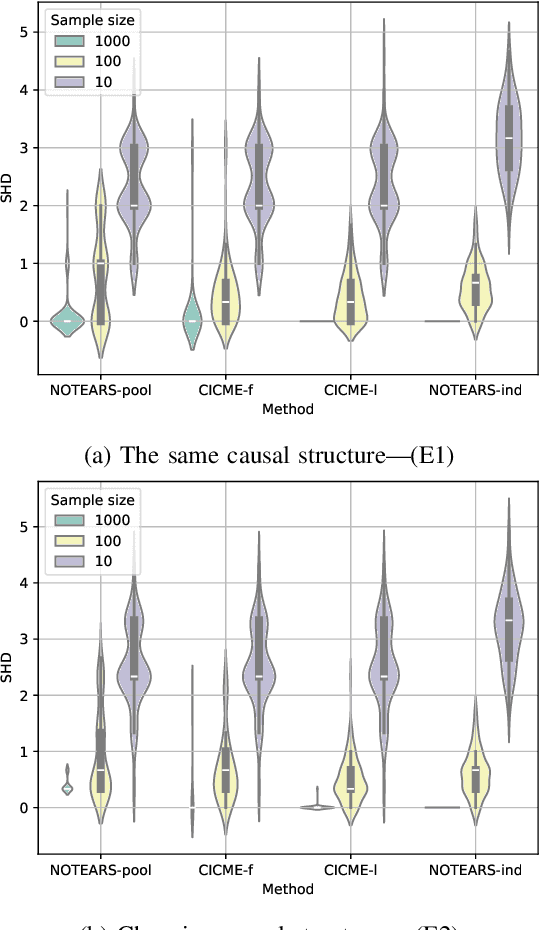
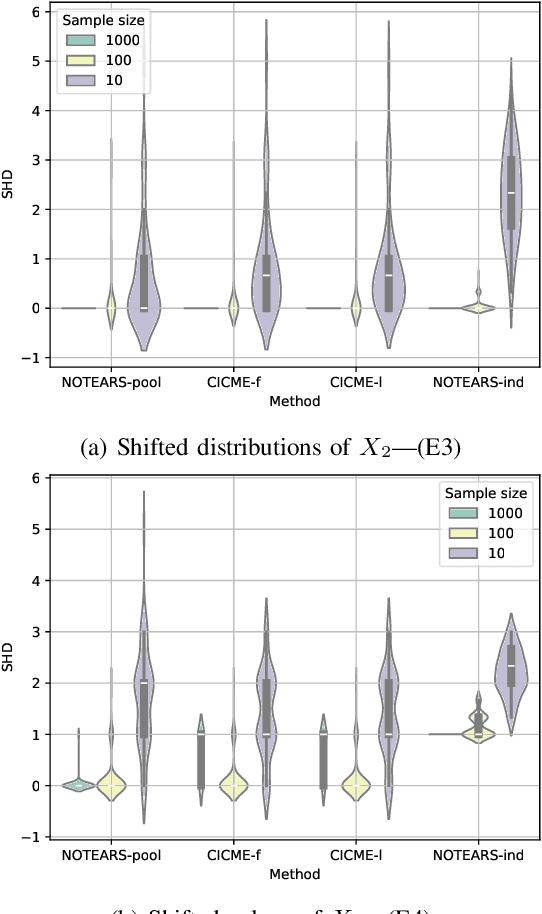
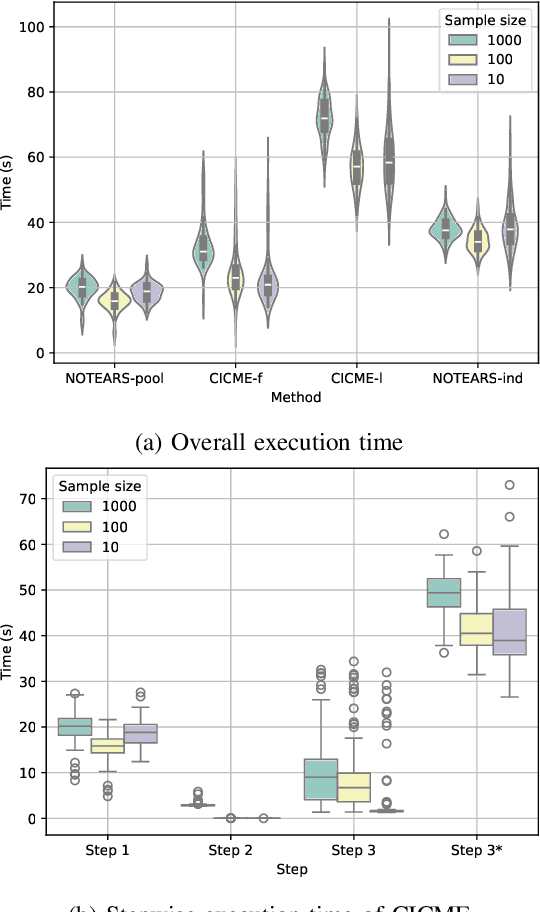
To gain deeper insights into a complex sensor system through the lens of causality, we present common and individual causal mechanism estimation (CICME), a novel three-step approach to inferring causal mechanisms from heterogeneous data collected across multiple domains. By leveraging the principle of Causal Transfer Learning (CTL), CICME is able to reliably detect domain-invariant causal mechanisms when provided with sufficient samples. The identified common causal mechanisms are further used to guide the estimation of the remaining causal mechanisms in each domain individually. The performance of CICME is evaluated on linear Gaussian models under scenarios inspired from a manufacturing process. Building upon existing continuous optimization-based causal discovery methods, we show that CICME leverages the benefits of applying causal discovery on the pooled data and repeatedly on data from individual domains, and it even outperforms both baseline methods under certain scenarios.
CausalMan: A physics-based simulator for large-scale causality
Feb 18, 2025A comprehensive understanding of causality is critical for navigating and operating within today's complex real-world systems. The absence of realistic causal models with known data generating processes complicates fair benchmarking. In this paper, we present the CausalMan simulator, modeled after a real-world production line. The simulator features a diverse range of linear and non-linear mechanisms and challenging-to-predict behaviors, such as discrete mode changes. We demonstrate the inadequacy of many state-of-the-art approaches and analyze the significant differences in their performance and tractability, both in terms of runtime and memory complexity. As a contribution, we will release the CausalMan large-scale simulator. We present two derived datasets, and perform an extensive evaluation of both.
$\texttt{causalAssembly}$: Generating Realistic Production Data for Benchmarking Causal Discovery
Jun 19, 2023



Algorithms for causal discovery have recently undergone rapid advances and increasingly draw on flexible nonparametric methods to process complex data. With these advances comes a need for adequate empirical validation of the causal relationships learned by different algorithms. However, for most real data sources true causal relations remain unknown. This issue is further compounded by privacy concerns surrounding the release of suitable high-quality data. To help address these challenges, we gather a complex dataset comprising measurements from an assembly line in a manufacturing context. This line consists of numerous physical processes for which we are able to provide ground truth causal relationships on the basis of a detailed study of the underlying physics. We use the assembly line data and associated ground truth information to build a system for generation of semisynthetic manufacturing data that supports benchmarking of causal discovery methods. To accomplish this, we employ distributional random forests in order to flexibly estimate and represent conditional distributions that may be combined into joint distributions that strictly adhere to a causal model over the observed variables. The estimated conditionals and tools for data generation are made available in our Python library $\texttt{causalAssembly}$. Using the library, we showcase how to benchmark several well-known causal discovery algorithms.