 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear Causal Discovery for Grouped Data
Jun 05, 2025Inferring cause-effect relationships from observational data has gained significant attention in recent years, but most methods are limited to scalar random variables. In many important domains, including neuroscience, psychology, social science, and industrial manufacturing, the causal units of interest are groups of variables rather than individual scalar measurements. Motivated by these applications, we extend nonlinear additive noise models to handle random vectors, establishing a two-step approach for causal graph learning: First, infer the causal order among random vectors. Second, perform model selection to identify the best graph consistent with this order. We introduce effective and novel solutions for both steps in the vector case, demonstrating strong performance in simulations. Finally, we apply our method to real-world assembly line data with partial knowledge of causal ordering among variable groups.
$\texttt{causalAssembly}$: Generating Realistic Production Data for Benchmarking Causal Discovery
Jun 19, 2023



Algorithms for causal discovery have recently undergone rapid advances and increasingly draw on flexible nonparametric methods to process complex data. With these advances comes a need for adequate empirical validation of the causal relationships learned by different algorithms. However, for most real data sources true causal relations remain unknown. This issue is further compounded by privacy concerns surrounding the release of suitable high-quality data. To help address these challenges, we gather a complex dataset comprising measurements from an assembly line in a manufacturing context. This line consists of numerous physical processes for which we are able to provide ground truth causal relationships on the basis of a detailed study of the underlying physics. We use the assembly line data and associated ground truth information to build a system for generation of semisynthetic manufacturing data that supports benchmarking of causal discovery methods. To accomplish this, we employ distributional random forests in order to flexibly estimate and represent conditional distributions that may be combined into joint distributions that strictly adhere to a causal model over the observed variables. The estimated conditionals and tools for data generation are made available in our Python library $\texttt{causalAssembly}$. Using the library, we showcase how to benchmark several well-known causal discovery algorithms.
High-Dimensional Undirected Graphical Models for Arbitrary Mixed Data
Nov 21, 2022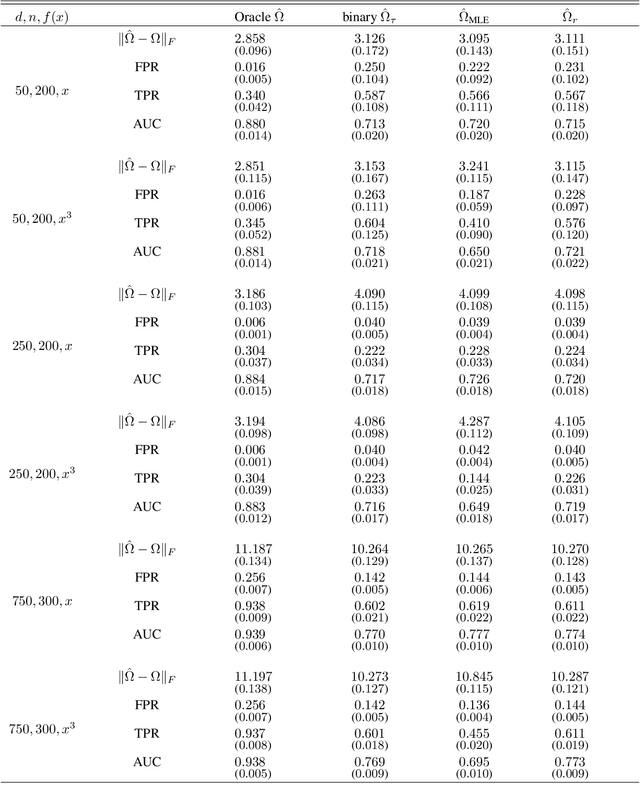
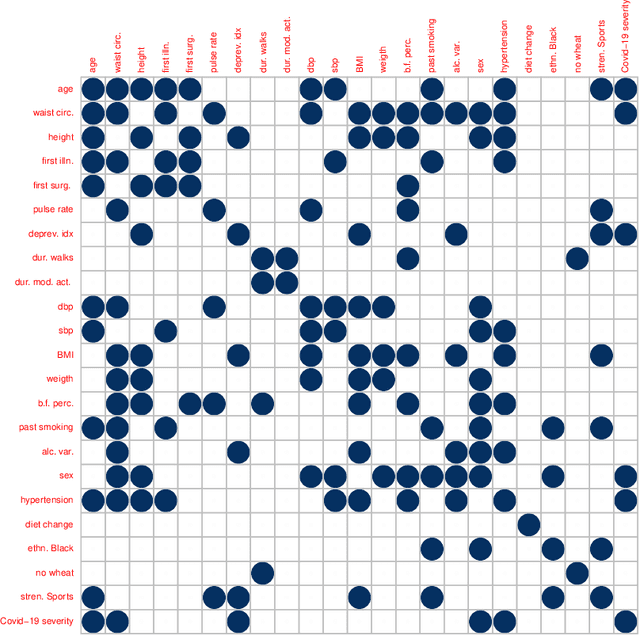
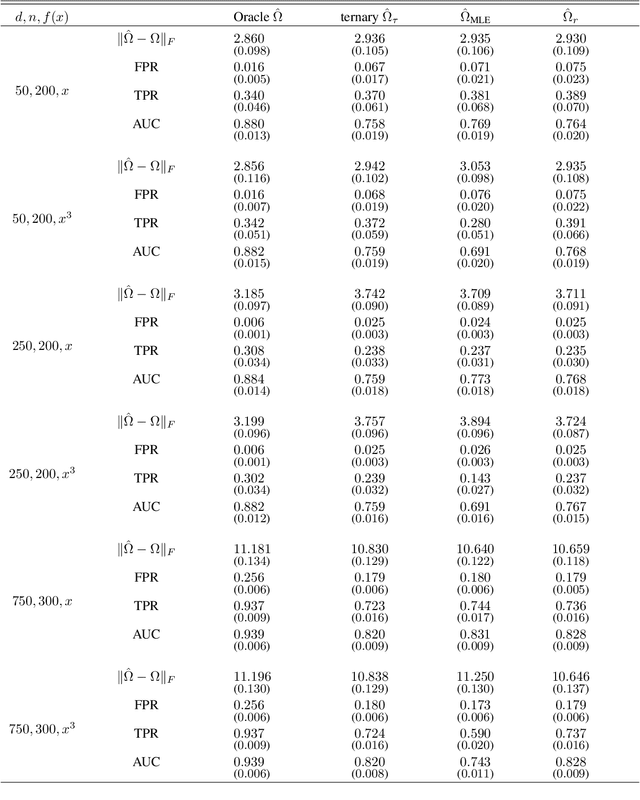
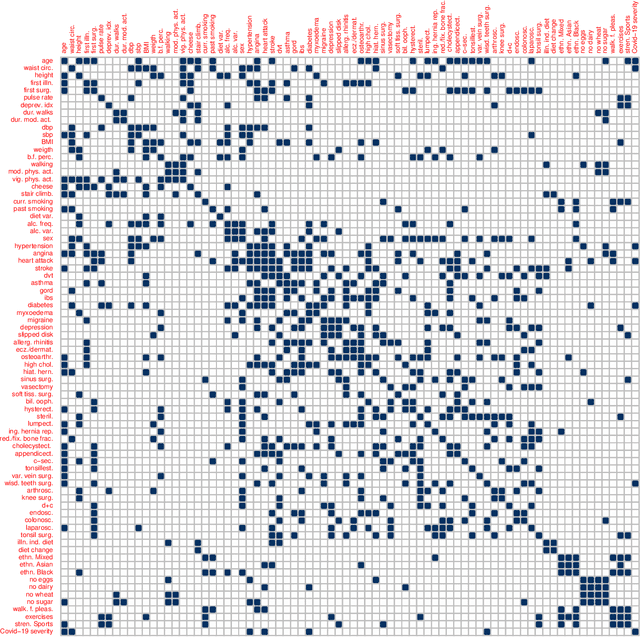
Graphical models are an important tool in exploring relationships between variables in complex, multivariate data. Methods for learning such graphical models are well developed in the case where all variables are either continuous or discrete, including in high-dimensions. However, in many applications data span variables of different types (e.g. continuous, count, binary, ordinal, etc.), whose principled joint analysis is nontrivial. Latent Gaussian copula models, in which all variables are modeled as transformations of underlying jointly Gaussian variables, represent a useful approach. Recent advances have shown how the binary-continuous case can be tackled, but the general mixed variable type regime remains challenging. In this work, we make the simple yet useful observation that classical ideas concerning polychoric and polyserial correlations can be leveraged in a latent Gaussian copula framework. Building on this observation we propose flexible and scalable methodology for data with variables of entirely general mixed type. We study the key properties of the approaches theoretically and empirically, via extensive simulations as well an illustrative application to data from the UK Biobank concerning COVID-19 risk factors.