 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Individual Dynamics from Sparse Cross-Sectional Snapshots
May 22, 2026Predicting how a dynamical unit evolves over time - how an individual ages, an epidemic spreads, or a physical system degrades - typically requires dense longitudinal tracking. When only extremely sparse or entirely cross-sectional data is available, inferring individualized, continuous-time trajectories is fundamentally ill-posed. Existing methods force a strict compromise: sequence models (e.g. latent ODEs) require dense longitudinal data, while cross-sectional methods (e.g. optimal transport, flow matching-based) map aggregate populations, losing individual dynamics. In this paper, we demonstrate that this dichotomy can be broken. We introduce CADENCE, a principled probabilistic framework that recovers continuous individual trajectories from isolated snapshots by anchoring latent dynamics to static, individual-level contexts. We provide novel identifiability guarantees for single-timepoint trajectory inference. By combining a score-based spatial encoder (bijective Probability Flow ODE) to eliminate diffeomorphic ambiguities with a Soft Mixture-of-Experts (SMoE) router, we show that individual dynamical parameters and routing function are jointly identifiable. Across a suite of benchmarks spanning physical systems to real-world biological data, CADENCE, trained strictly on extremely sparse snapshots with context structure, matches or exceeds the performance of state-of-the-art sequential models trained on dense, full-trajectory data.
Causal Cellular Context Transfer Learning (C3TL): An Efficient Architecture for Prediction of Unseen Perturbation Effects
Mar 13, 2026Predicting the effects of chemical and genetic perturbations on quantitative cell states is a central challenge in computational biology, molecular medicine and drug discovery. Recent work has leveraged large-scale single-cell data and massive foundation models to address this task. However, such computational resources and extensive datasets are not always accessible in academic or clinical settings, hence limiting utility. Here we propose a lightweight framework for perturbation effect prediction that exploits the structured nature of biological interventions and specific inductive biases/invariances. Our approach leverages available information concerning perturbation effects to allow generalization to novel contexts and requires only widely-available bulk molecular data. Extensive testing, comparing predictions of context-specific perturbation effects against real, large-scale interventional experiments, demonstrates accurate prediction in new contexts. The proposed approach is competitive with SOTA foundation models but requires simpler data, much smaller model sizes and less time. Focusing on robust bulk signals and efficient architectures, we show that accurate prediction of perturbation effects is possible without proprietary hardware or very large models, hence opening up ways to leverage causal learning approaches in biomedicine generally.
Evolving Afferent Architectures: Biologically-inspired Models for Damage-Avoidance Learning
Feb 04, 2026We introduce Afferent Learning, a framework that produces Computational Afferent Traces (CATs) as adaptive, internal risk signals for damage-avoidance learning. Inspired by biological systems, the framework uses a two-level architecture: evolutionary optimization (outer loop) discovers afferent sensing architectures that enable effective policy learning, while reinforcement learning (inner loop) trains damage-avoidance policies using these signals. This formalizes afferent sensing as providing an inductive bias for efficient learning: architectures are selected based on their ability to enable effective learning (rather than directly minimizing damage). We provide theoretical convergence guarantees under smoothness and bounded-noise assumptions. We illustrate the general approach in the challenging context of biomechanical digital twins operating over long time horizons (multiple decades of the life-course). Here, we find that CAT-based evolved architectures achieve significantly higher efficiency and better age-robustness than hand-designed baselines, enabling policies that exhibit age-dependent behavioral adaptation (23% reduction in high-risk actions). Ablation studies validate CAT signals, evolution, and predictive discrepancy as essential. We release code and data for reproducibility.
Many Experiments, Few Repetitions, Unpaired Data, and Sparse Effects: Is Causal Inference Possible?
Jan 21, 2026We study the problem of estimating causal effects under hidden confounding in the following unpaired data setting: we observe some covariates $X$ and an outcome $Y$ under different experimental conditions (environments) but do not observe them jointly; we either observe $X$ or $Y$. Under appropriate regularity conditions, the problem can be cast as an instrumental variable (IV) regression with the environment acting as a (possibly high-dimensional) instrument. When there are many environments but only a few observations per environment, standard two-sample IV estimators fail to be consistent. We propose a GMM-type estimator based on cross-fold sample splitting of the instrument-covariate sample and prove that it is consistent as the number of environments grows but the sample size per environment remains constant. We further extend the method to sparse causal effects via $\ell_1$-regularized estimation and post-selection refitting.
Large Language Models for Zero-shot Inference of Causal Structures in Biology
Mar 06, 2025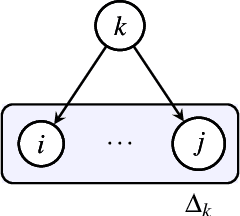
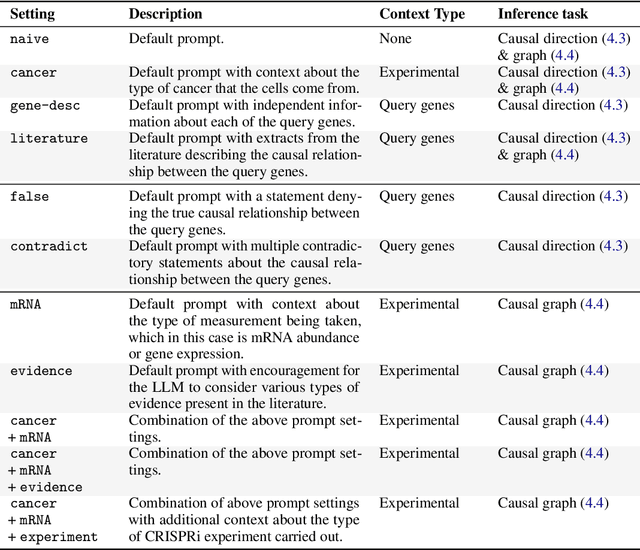
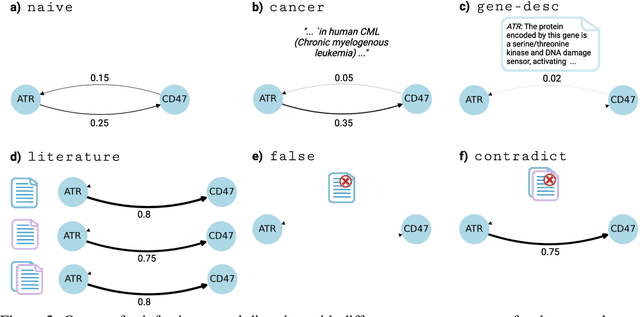
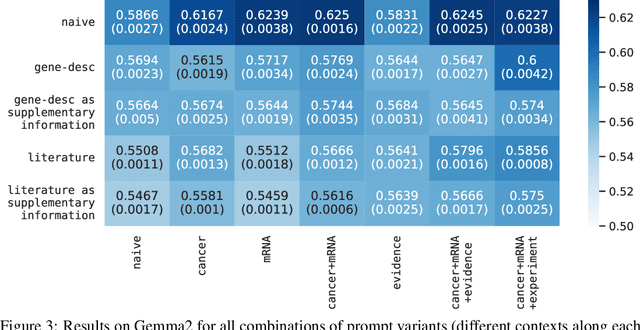
Genes, proteins and other biological entities influence one another via causal molecular networks. Causal relationships in such networks are mediated by complex and diverse mechanisms, through latent variables, and are often specific to cellular context. It remains challenging to characterise such networks in practice. Here, we present a novel framework to evaluate large language models (LLMs) for zero-shot inference of causal relationships in biology. In particular, we systematically evaluate causal claims obtained from an LLM using real-world interventional data. This is done over one hundred variables and thousands of causal hypotheses. Furthermore, we consider several prompting and retrieval-augmentation strategies, including large, and potentially conflicting, collections of scientific articles. Our results show that with tailored augmentation and prompting, even relatively small LLMs can capture meaningful aspects of causal structure in biological systems. This supports the notion that LLMs could act as orchestration tools in biological discovery, by helping to distil current knowledge in ways amenable to downstream analysis. Our approach to assessing LLMs with respect to experimental data is relevant for a broad range of problems at the intersection of causal learning, LLMs and scientific discovery.
Simulation-based Benchmarking for Causal Structure Learning in Gene Perturbation Experiments
Jul 08, 2024



Causal structure learning (CSL) refers to the task of learning causal relationships from data. Advances in CSL now allow learning of causal graphs in diverse application domains, which has the potential to facilitate data-driven causal decision-making. Real-world CSL performance depends on a number of $\textit{context-specific}$ factors, including context-specific data distributions and non-linear dependencies, that are important in practical use-cases. However, our understanding of how to assess and select CSL methods in specific contexts remains limited. To address this gap, we present $\textit{CausalRegNet}$, a multiplicative effect structural causal model that allows for generating observational and interventional data incorporating context-specific properties, with a focus on the setting of gene perturbation experiments. Using real-world gene perturbation data, we show that CausalRegNet generates accurate distributions and scales far better than current simulation frameworks. We illustrate the use of CausalRegNet in assessing CSL methods in the context of interventional experiments in biology.
Learning Latent Dynamics via Invariant Decomposition and (Spatio-)Temporal Transformers
Jun 21, 2023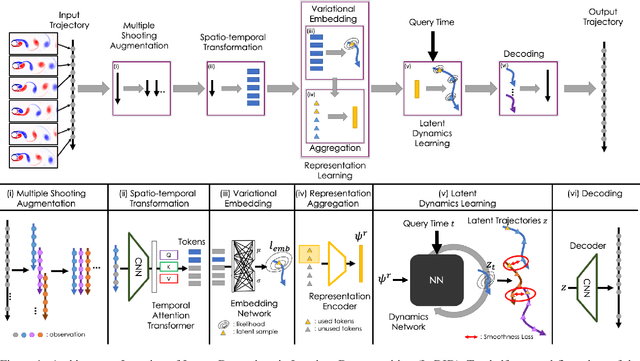
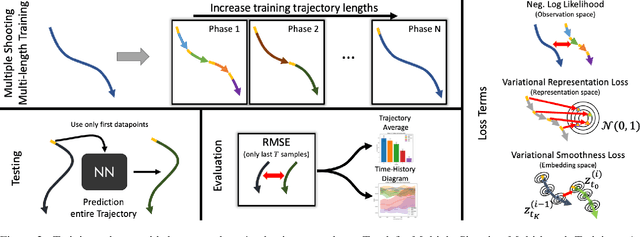
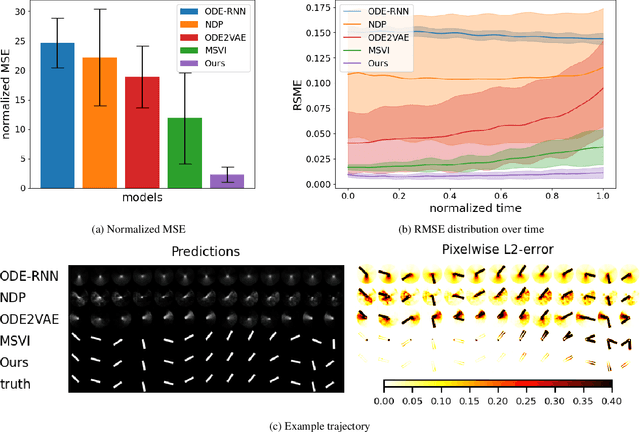
We propose a method for learning dynamical systems from high-dimensional empirical data that combines variational autoencoders and (spatio-)temporal attention within a framework designed to enforce certain scientifically-motivated invariances. We focus on the setting in which data are available from multiple different instances of a system whose underlying dynamical model is entirely unknown at the outset. The approach rests on a separation into an instance-specific encoding (capturing initial conditions, constants etc.) and a latent dynamics model that is itself universal across all instances/realizations of the system. The separation is achieved in an automated, data-driven manner and only empirical data are required as inputs to the model. The approach allows effective inference of system behaviour at any continuous time but does not require an explicit neural ODE formulation, which makes it efficient and highly scalable. We study behaviour through simple theoretical analyses and extensive experiments on synthetic and real-world datasets. The latter investigate learning the dynamics of complex systems based on finite data and show that the proposed approach can outperform state-of-the-art neural-dynamical models. We study also more general inductive bias in the context of transfer to data obtained under entirely novel system interventions. Overall, our results provide a promising new framework for efficiently learning dynamical models from heterogeneous data with potential applications in a wide range of fields including physics, medicine, biology and engineering.
Deep Learning of Causal Structures in High Dimensions
Dec 09, 2022Recent years have seen rapid progress at the intersection between causality and machine learning. Motivated by scientific applications involving high-dimensional data, in particular in biomedicine, we propose a deep neural architecture for learning causal relationships between variables from a combination of empirical data and prior causal knowledge. We combine convolutional and graph neural networks within a causal risk framework to provide a flexible and scalable approach. Empirical results include linear and nonlinear simulations (where the underlying causal structures are known and can be directly compared against), as well as a real biological example where the models are applied to high-dimensional molecular data and their output compared against entirely unseen validation experiments. These results demonstrate the feasibility of using deep learning approaches to learn causal networks in large-scale problems spanning thousands of variables.
High-Dimensional Undirected Graphical Models for Arbitrary Mixed Data
Nov 21, 2022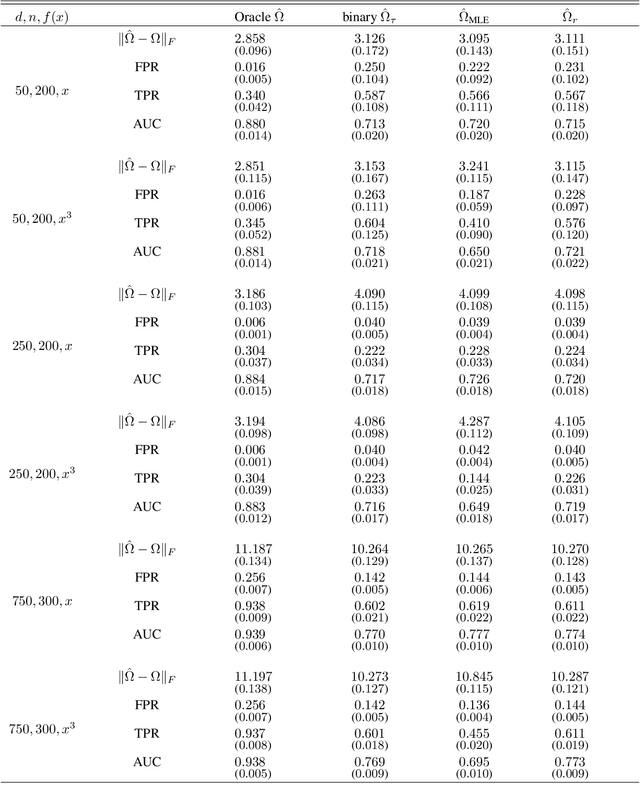
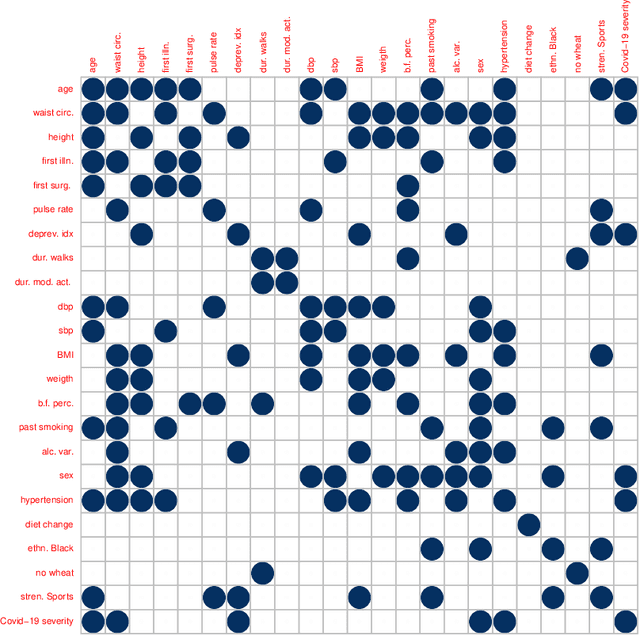
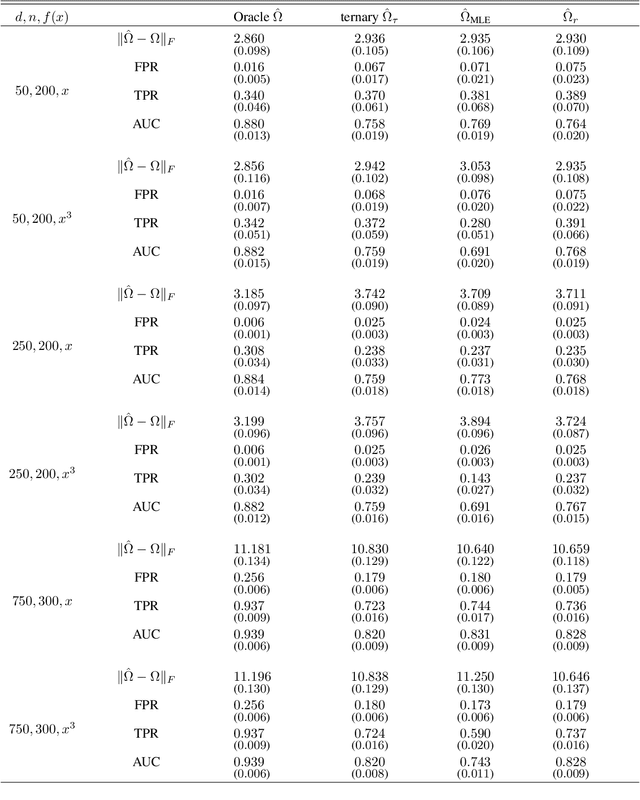
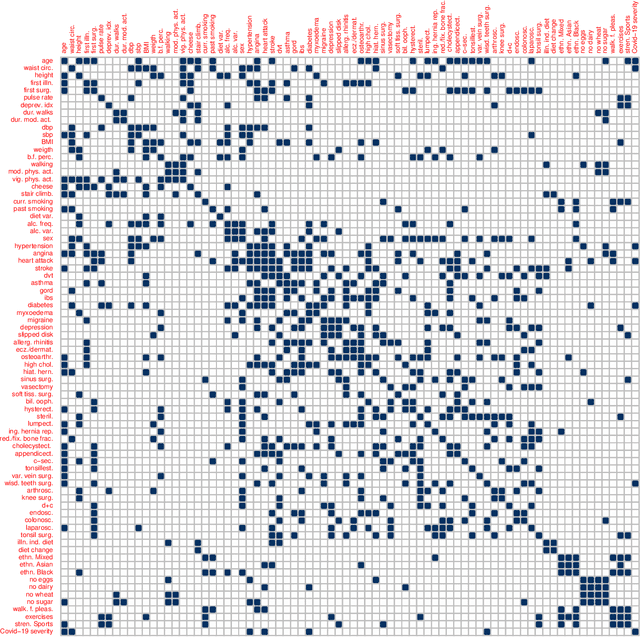
Graphical models are an important tool in exploring relationships between variables in complex, multivariate data. Methods for learning such graphical models are well developed in the case where all variables are either continuous or discrete, including in high-dimensions. However, in many applications data span variables of different types (e.g. continuous, count, binary, ordinal, etc.), whose principled joint analysis is nontrivial. Latent Gaussian copula models, in which all variables are modeled as transformations of underlying jointly Gaussian variables, represent a useful approach. Recent advances have shown how the binary-continuous case can be tackled, but the general mixed variable type regime remains challenging. In this work, we make the simple yet useful observation that classical ideas concerning polychoric and polyserial correlations can be leveraged in a latent Gaussian copula framework. Building on this observation we propose flexible and scalable methodology for data with variables of entirely general mixed type. We study the key properties of the approaches theoretically and empirically, via extensive simulations as well an illustrative application to data from the UK Biobank concerning COVID-19 risk factors.
Scalable Regularised Joint Mixture Models
May 03, 2022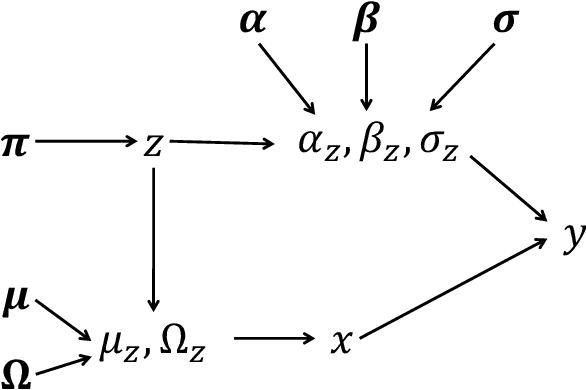
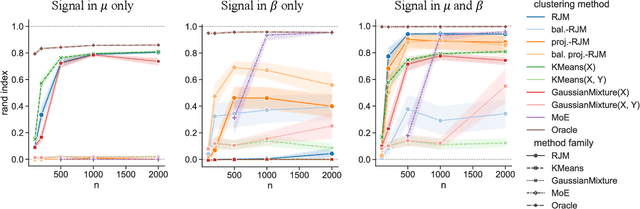
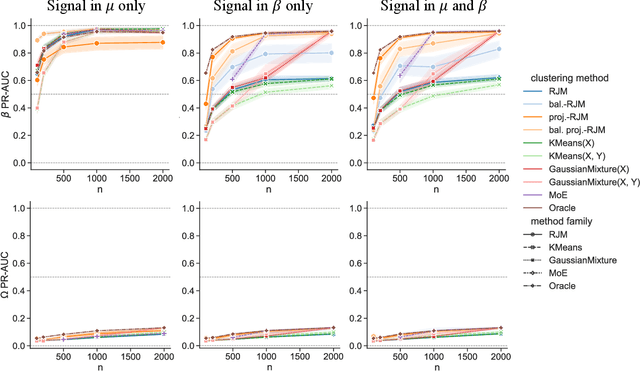
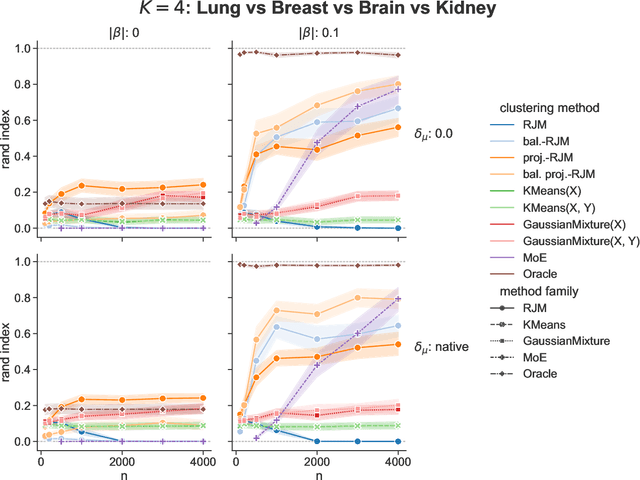
In many applications, data can be heterogeneous in the sense of spanning latent groups with different underlying distributions. When predictive models are applied to such data the heterogeneity can affect both predictive performance and interpretability. Building on developments at the intersection of unsupervised learning and regularised regression, we propose an approach for heterogeneous data that allows joint learning of (i) explicit multivariate feature distributions, (ii) high-dimensional regression models and (iii) latent group labels, with both (i) and (ii) specific to latent groups and both elements informing (iii). The approach is demonstrably effective in high dimensions, combining data reduction for computational efficiency with a re-weighting scheme that retains key signals even when the number of features is large. We discuss in detail these aspects and their impact on modelling and computation, including EM convergence. The approach is modular and allows incorporation of data reductions and high-dimensional estimators that are suitable for specific applications. We show results from extensive simulations and real data experiments, including highly non-Gaussian data. Our results allow efficient, effective analysis of high-dimensional data in settings, such as biomedicine, where both interpretable prediction and explicit feature space models are needed but hidden heterogeneity may be a concern.