 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAncestral causal learning in high dimensions with a human genome-wide application
Paper and Code
May 27, 2019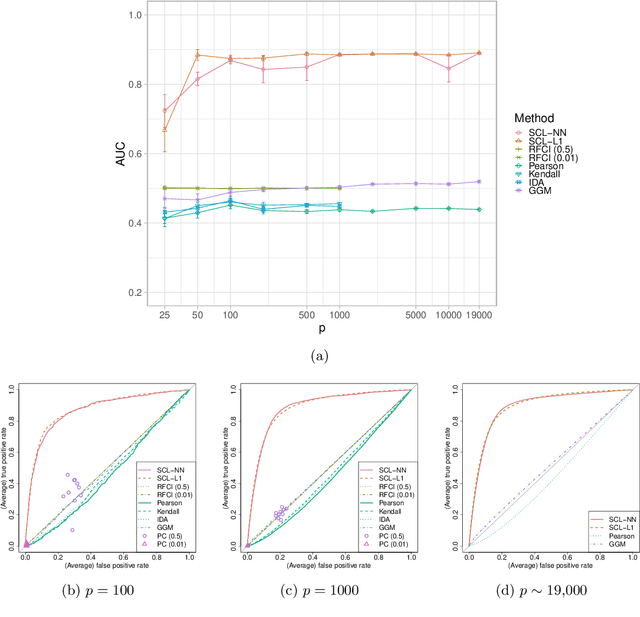
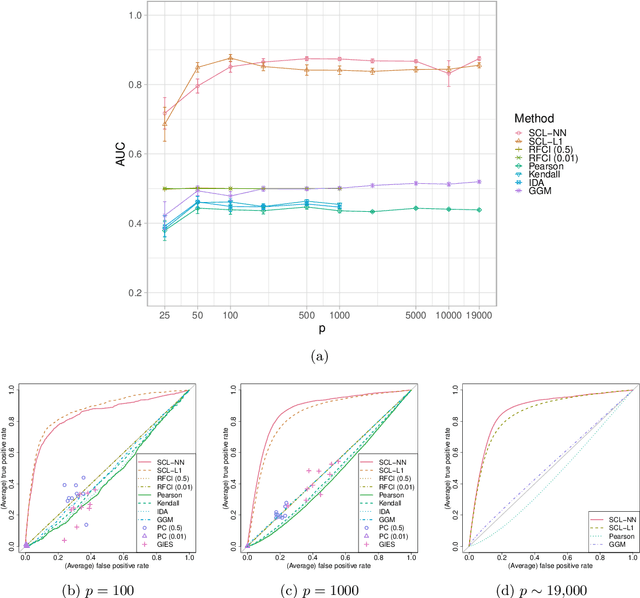
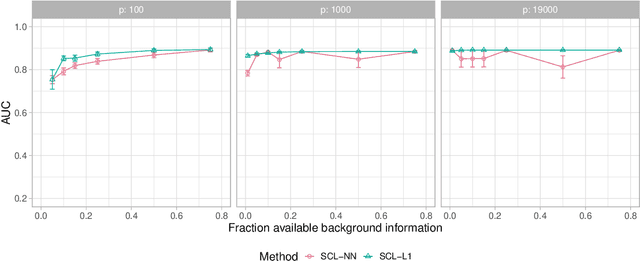
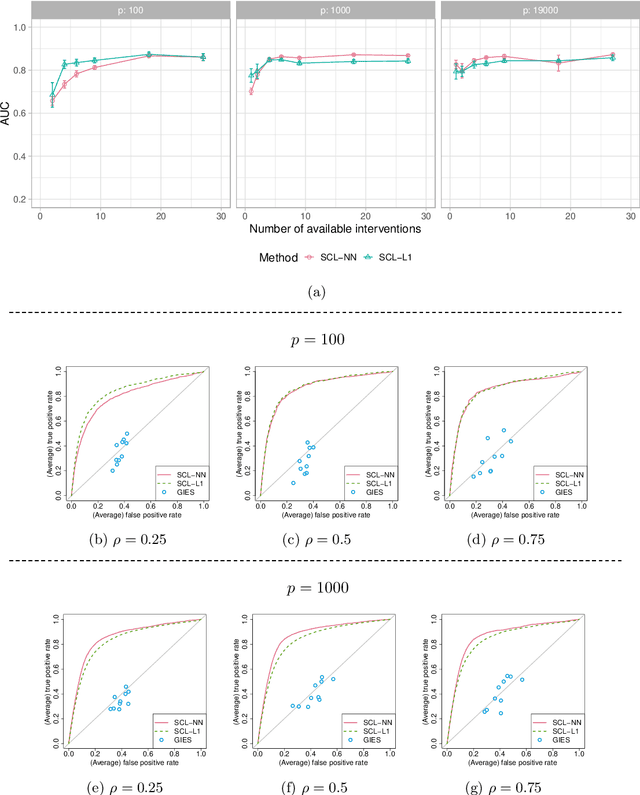
We consider learning ancestral causal relationships in high dimensions. Our approach is driven by a supervised learning perspective, with discrete indicators of causal relationships treated as labels to be learned from available data. We focus on the setting in which some causal (ancestral) relationships are known (via background knowledge or experimental data) and put forward a general approach that scales to large problems. This is motivated by problems in human biology which are characterized by high dimensionality and potentially many latent variables. We present a case study involving interventional data from human cells with total dimension $p \! \sim \! 19{,}000$. Performance is assessed empirically by testing model output against previously unseen interventional data. The proposed approach is highly effective and demonstrably scalable to the human genome-wide setting. We consider sensitivity to background knowledge and find that results are robust to nontrivial perturbations of the input information. We consider also the case, relevant to some applications, where the only prior information available concerns a small number of known ancestral relationships.