 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional regression in practice: an empirical study of finite-sample prediction, variable selection and ranking
Paper and Code
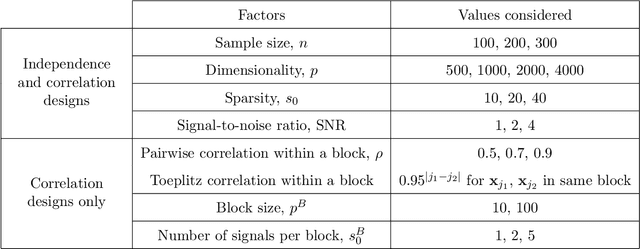
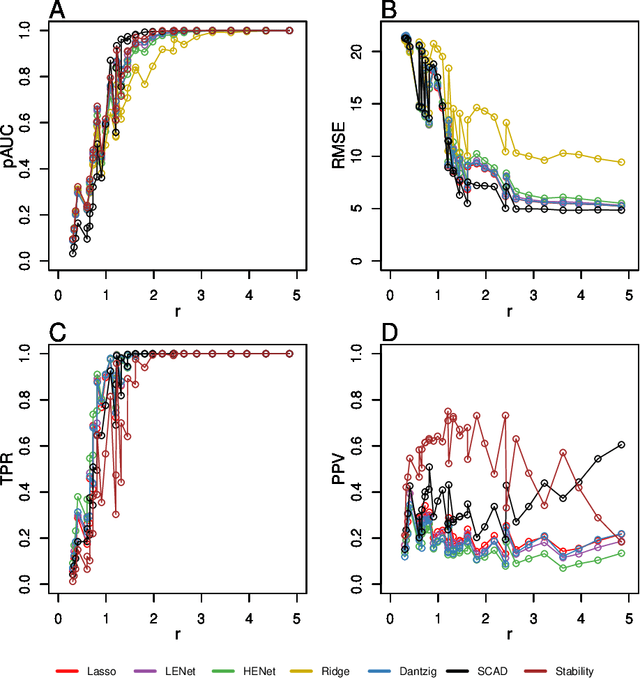
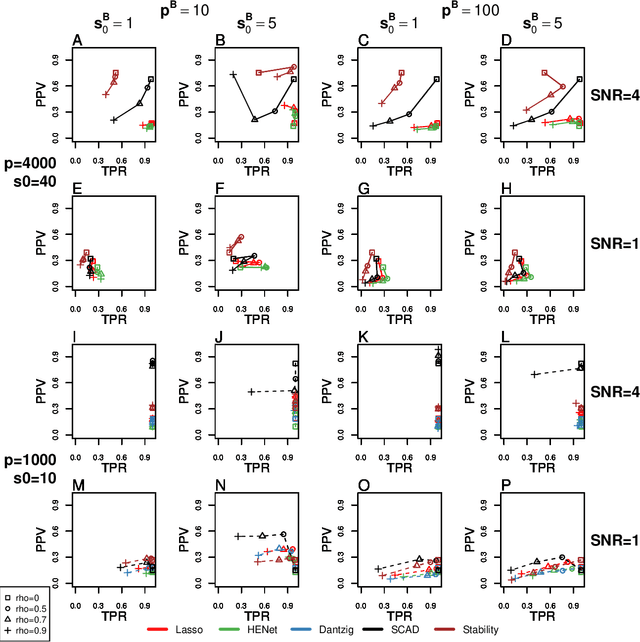
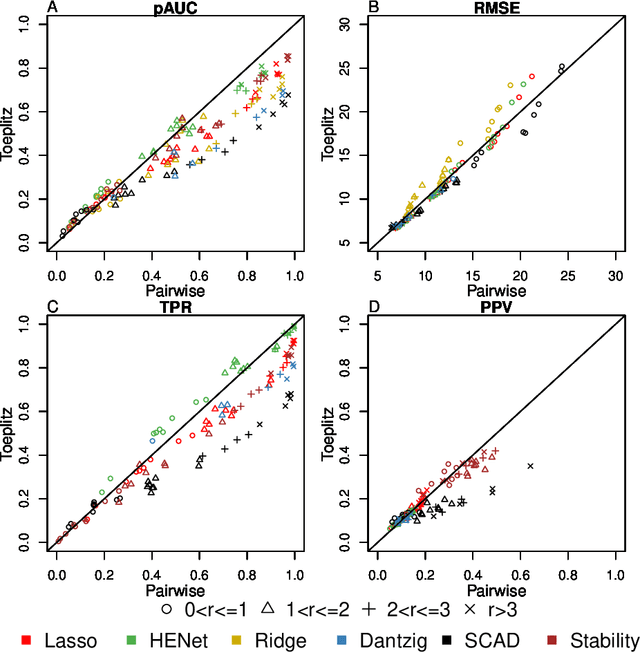
Penalized likelihood methods are widely used for high-dimensional regression. Although many methods have been proposed and the associated theory is now well-developed, the relative efficacy of different methods in finite-sample settings, as encountered in practice, remains incompletely understood. There is therefore a need for empirical investigations in this area that can offer practical insight and guidance to users of these methods. In this paper we present a large-scale comparison of penalized regression methods. We distinguish between three related goals: prediction, variable selection and variable ranking. Our results span more than 1,800 data-generating scenarios, allowing us to systematically consider the influence of various factors (sample size, dimensionality, sparsity, signal strength and multicollinearity). We consider several widely-used methods (Lasso, Elastic Net, Ridge Regression, SCAD, the Dantzig Selector as well as Stability Selection). We find considerable variation in performance between methods, with results dependent on details of the data-generating scenario and the specific goal. Our results support a `no panacea' view, with no unambiguous winner across all scenarios, even in this restricted setting where all data align well with the assumptions underlying the methods. Lasso is well-behaved, performing competitively in many scenarios, while SCAD is highly variable. Substantial benefits from a Ridge-penalty are only seen in the most challenging scenarios with strong multi-collinearity. The results are supported by semi-synthetic analyzes using gene expression data from cancer samples. Our empirical results complement existing theory and provide a resource to compare methods across a range of scenarios and metrics.