 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Zero-shot Inference of Causal Structures in Biology
Mar 06, 2025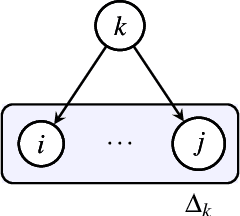
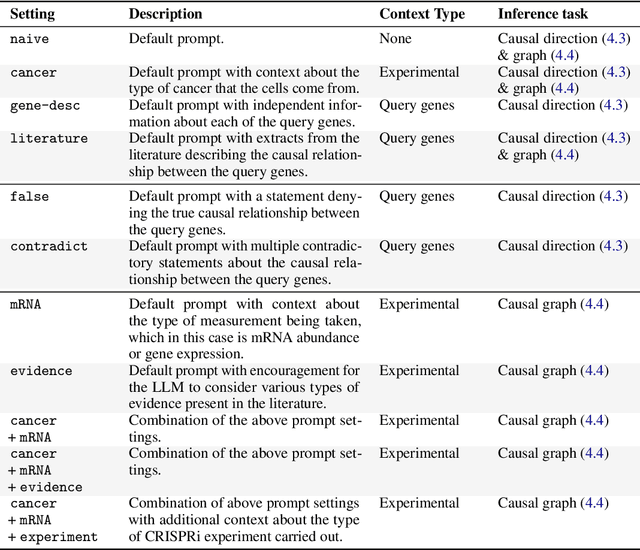
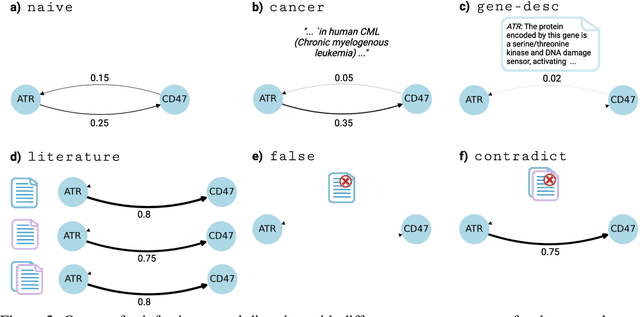
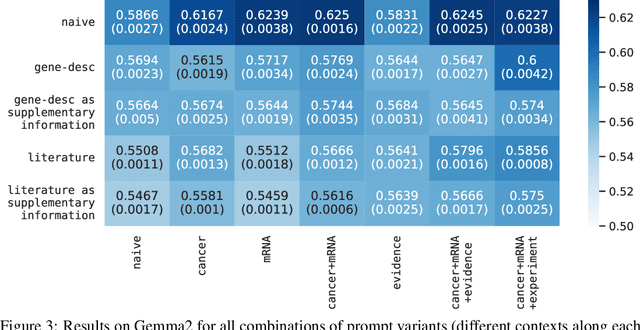
Genes, proteins and other biological entities influence one another via causal molecular networks. Causal relationships in such networks are mediated by complex and diverse mechanisms, through latent variables, and are often specific to cellular context. It remains challenging to characterise such networks in practice. Here, we present a novel framework to evaluate large language models (LLMs) for zero-shot inference of causal relationships in biology. In particular, we systematically evaluate causal claims obtained from an LLM using real-world interventional data. This is done over one hundred variables and thousands of causal hypotheses. Furthermore, we consider several prompting and retrieval-augmentation strategies, including large, and potentially conflicting, collections of scientific articles. Our results show that with tailored augmentation and prompting, even relatively small LLMs can capture meaningful aspects of causal structure in biological systems. This supports the notion that LLMs could act as orchestration tools in biological discovery, by helping to distil current knowledge in ways amenable to downstream analysis. Our approach to assessing LLMs with respect to experimental data is relevant for a broad range of problems at the intersection of causal learning, LLMs and scientific discovery.
Towards Responsible Governance of Biological Design Tools
Nov 30, 2023Recent advancements in generative machine learning have enabled rapid progress in biological design tools (BDTs) such as protein structure and sequence prediction models. The unprecedented predictive accuracy and novel design capabilities of BDTs present new and significant dual-use risks. For example, their predictive accuracy allows biological agents, whether vaccines or pathogens, to be developed more quickly, while the design capabilities could be used to discover drugs or evade DNA screening techniques. Similar to other dual-use AI systems, BDTs present a wicked problem: how can regulators uphold public safety without stifling innovation? We highlight how current regulatory proposals that are primarily tailored toward large language models may be less effective for BDTs, which require fewer computational resources to train and are often developed in an open-source manner. We propose a range of measures to mitigate the risk that BDTs are misused, across the areas of responsible development, risk assessment, transparency, access management, cybersecurity, and investing in resilience. Implementing such measures will require close coordination between developers and governments.