 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferences in Detection: Explainability Where it Matters
Jun 05, 2026We propose Differences in Detection (DnD), an intuitive method to compare two object detection models. Based on the same matching algorithm, it complements the standard metrics of mean Average Precision ($mAP$) and TIDE error analysis with the ability to compare two models directly. More specifically, we calculate the intersection of ground truth labels that are recognized by both models, followed by the corresponding difference sets and the complement set of ground truth labels that are missed by both models. The resulting comparison is more direct and intuitive than a comparison of independent summary statistics. It reveals individual and shared mistakes and becomes particularly interesting when combined with error types. In this case, the differences in detection errors can be analyzed naturally in a standard confusion matrix. While valuable in itself, we believe that one of the best applications of DnD is to guide explainability methods such as ODAM towards metric-relevant examples, grounded in structured subsets. The code for our method is available here: https://github.com/JohannesTheo/differences-in-detection
Evaluating the Impact of Data Anonymization on Image Retrieval
Feb 23, 2026With the growing importance of privacy regulations such as the General Data Protection Regulation, anonymizing visual data is becoming increasingly relevant across institutions. However, anonymization can negatively affect the performance of Computer Vision systems that rely on visual features, such as Content-Based Image Retrieval (CBIR). Despite this, the impact of anonymization on CBIR has not been systematically studied. This work addresses this gap, motivated by the DOKIQ project, an artificial intelligence-based system for document verification actively used by the State Criminal Police Office Baden-Württemberg. We propose a simple evaluation framework: retrieval results after anonymization should match those obtained before anonymization as closely as possible. To this end, we systematically assess the impact of anonymization using two public datasets and the internal DOKIQ dataset. Our experiments span three anonymization methods, four anonymization degrees, and four training strategies, all based on the state of the art backbone Self-Distillation with No Labels (DINO)v2. Our results reveal a pronounced retrieval bias in favor of models trained on original data, which produce the most similar retrievals after anonymization. The findings of this paper offer practical insights for developing privacy-compliant CBIR systems while preserving performance.
Generation of Programmatic Rules for Document Forgery Detection Using Large Language Models
Dec 22, 2025Document forgery poses a growing threat to legal, economic, and governmental processes, requiring increasingly sophisticated verification mechanisms. One approach involves the use of plausibility checks, rule-based procedures that assess the correctness and internal consistency of data, to detect anomalies or signs of manipulation. Although these verification procedures are essential for ensuring data integrity, existing plausibility checks are manually implemented by software engineers, which is time-consuming. Recent advances in code generation with large language models (LLMs) offer new potential for automating and scaling the generation of these checks. However, adapting LLMs to the specific requirements of an unknown domain remains a significant challenge. This work investigates the extent to which LLMs, adapted on domain-specific code and data through different fine-tuning strategies, can generate rule-based plausibility checks for forgery detection on constrained hardware resources. We fine-tune open-source LLMs, Llama 3.1 8B and OpenCoder 8B, on structured datasets derived from real-world application scenarios and evaluate the generated plausibility checks on previously unseen forgery patterns. The results demonstrate that the models are capable of generating executable and effective verification procedures. This also highlights the potential of LLMs as scalable tools to support human decision-making in security-sensitive contexts where comprehensibility is required.
A Toolbox for Improving Evolutionary Prompt Search
Nov 07, 2025Evolutionary prompt optimization has demonstrated effectiveness in refining prompts for LLMs. However, existing approaches lack robust operators and efficient evaluation mechanisms. In this work, we propose several key improvements to evolutionary prompt optimization that can partially generalize to prompt optimization in general: 1) decomposing evolution into distinct steps to enhance the evolution and its control, 2) introducing an LLM-based judge to verify the evolutions, 3) integrating human feedback to refine the evolutionary operator, and 4) developing more efficient evaluation strategies that maintain performance while reducing computational overhead. Our approach improves both optimization quality and efficiency. We release our code, enabling prompt optimization on new tasks and facilitating further research in this area.
ViPro-2: Unsupervised State Estimation via Integrated Dynamics for Guiding Video Prediction
Aug 08, 2025Predicting future video frames is a challenging task with many downstream applications. Previous work has shown that procedural knowledge enables deep models for complex dynamical settings, however their model ViPro assumed a given ground truth initial symbolic state. We show that this approach led to the model learning a shortcut that does not actually connect the observed environment with the predicted symbolic state, resulting in the inability to estimate states given an observation if previous states are noisy. In this work, we add several improvements to ViPro that enables the model to correctly infer states from observations without providing a full ground truth state in the beginning. We show that this is possible in an unsupervised manner, and extend the original Orbits dataset with a 3D variant to close the gap to real world scenarios.
Anonymization of Documents for Law Enforcement with Machine Learning
Jan 13, 2025



The steadily increasing utilization of data-driven methods and approaches in areas that handle sensitive personal information such as in law enforcement mandates an ever increasing effort in these institutions to comply with data protection guidelines. In this work, we present a system for automatically anonymizing images of scanned documents, reducing manual effort while ensuring data protection compliance. Our method considers the viability of further forensic processing after anonymization by minimizing automatically redacted areas by combining automatic detection of sensitive regions with knowledge from a manually anonymized reference document. Using a self-supervised image model for instance retrieval of the reference document, our approach requires only one anonymized example to efficiently redact all documents of the same type, significantly reducing processing time. We show that our approach outperforms both a purely automatic redaction system and also a naive copy-paste scheme of the reference anonymization to other documents on a hand-crafted dataset of ground truth redactions.
Divide and Conquer: A Systematic Approach for Industrial Scale High-Definition OpenDRIVE Generation from Sparse Point Clouds
Jul 26, 2024High-definition road maps play a crucial role in the functionality and verification of highly automated driving functions. These contain precise information about the road network, geometry, condition, as well as traffic signs. Despite their importance for the development and evaluation of driving functions, the generation of high-definition maps is still an ongoing research topic. While previous work in this area has primarily focused on the accuracy of road geometry, we present a novel approach for automated large-scale map generation for use in industrial applications. Our proposed method leverages a minimal number of external information about the road to process LiDAR data in segments. These segments are subsequently combined, enabling a flexible and scalable process that achieves high-definition accuracy. Additionally, we showcase the use of the resulting OpenDRIVE in driving function simulation.
* 8 pages, 5 figures, 1 table. arXiv admin note: text overlap with arXiv:2405.07544
Unveiling the Decision-Making Process in Reinforcement Learning with Genetic Programming
Jul 20, 2024



Despite tremendous progress, machine learning and deep learning still suffer from incomprehensible predictions. Incomprehensibility, however, is not an option for the use of (deep) reinforcement learning in the real world, as unpredictable actions can seriously harm the involved individuals. In this work, we propose a genetic programming framework to generate explanations for the decision-making process of already trained agents by imitating them with programs. Programs are interpretable and can be executed to generate explanations of why the agent chooses a particular action. Furthermore, we conduct an ablation study that investigates how extending the domain-specific language by using library learning alters the performance of the method. We compare our results with the previous state of the art for this problem and show that we are comparable in performance but require much less hardware resources and computation time.
Guiding Video Prediction with Explicit Procedural Knowledge
Jun 26, 2024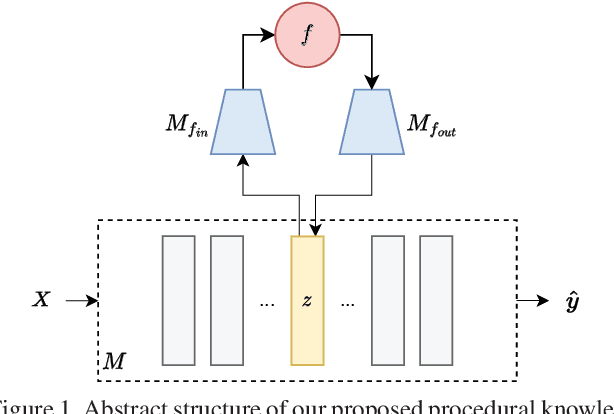

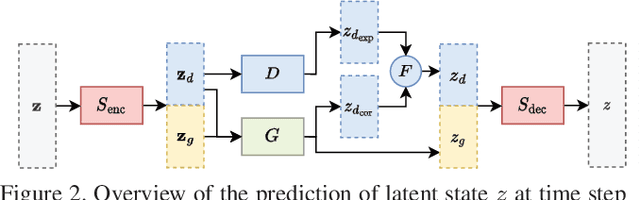

We propose a general way to integrate procedural knowledge of a domain into deep learning models. We apply it to the case of video prediction, building on top of object-centric deep models and show that this leads to a better performance than using data-driven models alone. We develop an architecture that facilitates latent space disentanglement in order to use the integrated procedural knowledge, and establish a setup that allows the model to learn the procedural interface in the latent space using the downstream task of video prediction. We contrast the performance to a state-of-the-art data-driven approach and show that problems where purely data-driven approaches struggle can be handled by using knowledge about the domain, providing an alternative to simply collecting more data.
* Published in 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)
Automatic Odometry-Less OpenDRIVE Generation From Sparse Point Clouds
May 13, 2024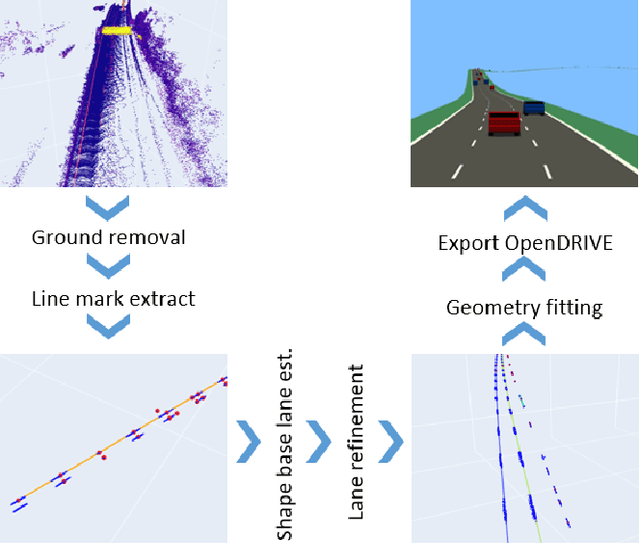
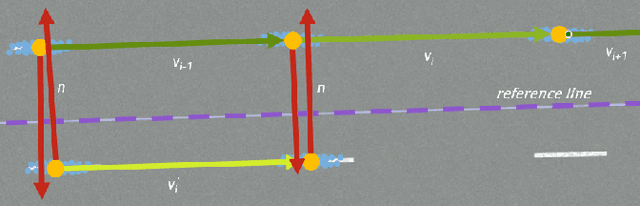

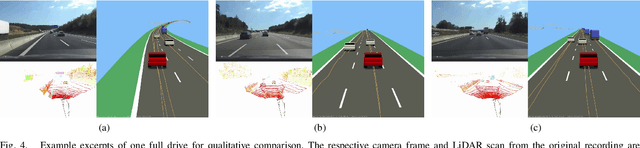
High-resolution road representations are a key factor for the success of (highly) automated driving functions. These representations, for example, high-definition (HD) maps, contain accurate information on a multitude of factors, among others: road geometry, lane information, and traffic signs. Through the growing complexity and functionality of automated driving functions, also the requirements on testing and evaluation grow continuously. This leads to an increasing interest in virtual test drives for evaluation purposes. As roads play a crucial role in traffic flow, accurate real-world representations are needed, especially when deriving realistic driving behavior data. This paper proposes a novel approach to generate realistic road representations based solely on point cloud information, independent of the LiDAR sensor, mounting position, and without the need for odometry data, multi-sensor fusion, machine learning, or highly-accurate calibration. As the primary use case is simulation, we use the OpenDRIVE format for evaluation.
* 8 pages, 4 figures, 3 algorithms, 2 tables