 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Toolbox for Improving Evolutionary Prompt Search
Nov 07, 2025Evolutionary prompt optimization has demonstrated effectiveness in refining prompts for LLMs. However, existing approaches lack robust operators and efficient evaluation mechanisms. In this work, we propose several key improvements to evolutionary prompt optimization that can partially generalize to prompt optimization in general: 1) decomposing evolution into distinct steps to enhance the evolution and its control, 2) introducing an LLM-based judge to verify the evolutions, 3) integrating human feedback to refine the evolutionary operator, and 4) developing more efficient evaluation strategies that maintain performance while reducing computational overhead. Our approach improves both optimization quality and efficiency. We release our code, enabling prompt optimization on new tasks and facilitating further research in this area.
Anonymization of Documents for Law Enforcement with Machine Learning
Jan 13, 2025



The steadily increasing utilization of data-driven methods and approaches in areas that handle sensitive personal information such as in law enforcement mandates an ever increasing effort in these institutions to comply with data protection guidelines. In this work, we present a system for automatically anonymizing images of scanned documents, reducing manual effort while ensuring data protection compliance. Our method considers the viability of further forensic processing after anonymization by minimizing automatically redacted areas by combining automatic detection of sensitive regions with knowledge from a manually anonymized reference document. Using a self-supervised image model for instance retrieval of the reference document, our approach requires only one anonymized example to efficiently redact all documents of the same type, significantly reducing processing time. We show that our approach outperforms both a purely automatic redaction system and also a naive copy-paste scheme of the reference anonymization to other documents on a hand-crafted dataset of ground truth redactions.
Fine-tuning BERT for Low-Resource Natural Language Understanding via Active Learning
Dec 04, 2020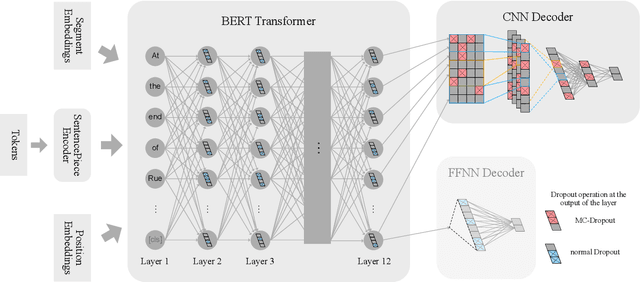
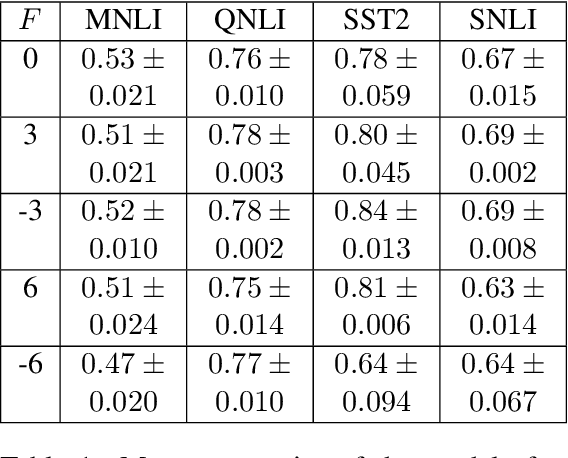

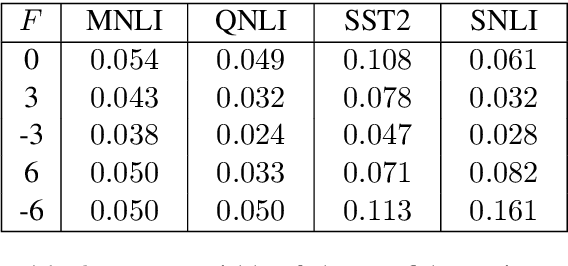
Recently, leveraging pre-trained Transformer based language models in down stream, task specific models has advanced state of the art results in natural language understanding tasks. However, only a little research has explored the suitability of this approach in low resource settings with less than 1,000 training data points. In this work, we explore fine-tuning methods of BERT -- a pre-trained Transformer based language model -- by utilizing pool-based active learning to speed up training while keeping the cost of labeling new data constant. Our experimental results on the GLUE data set show an advantage in model performance by maximizing the approximate knowledge gain of the model when querying from the pool of unlabeled data. Finally, we demonstrate and analyze the benefits of freezing layers of the language model during fine-tuning to reduce the number of trainable parameters, making it more suitable for low-resource settings.
Low-Resource Text Classification using Domain-Adversarial Learning
Jul 13, 2018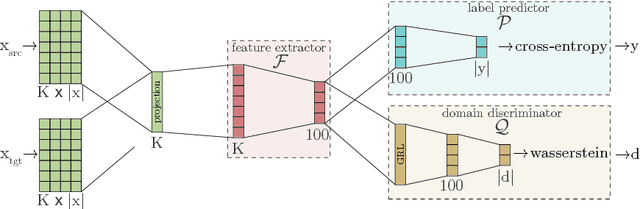
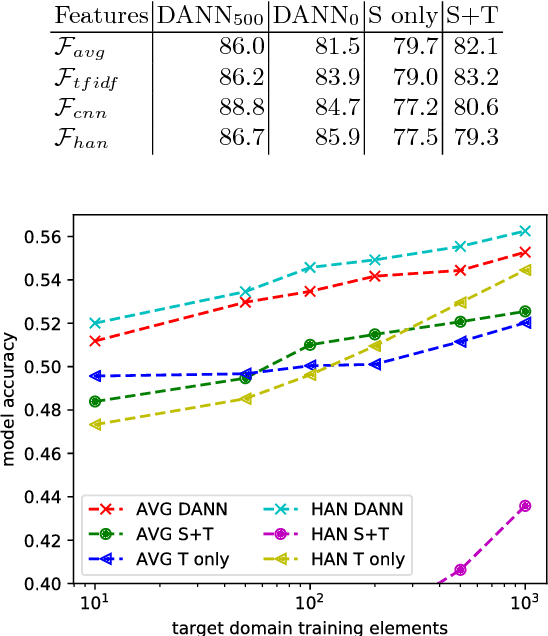
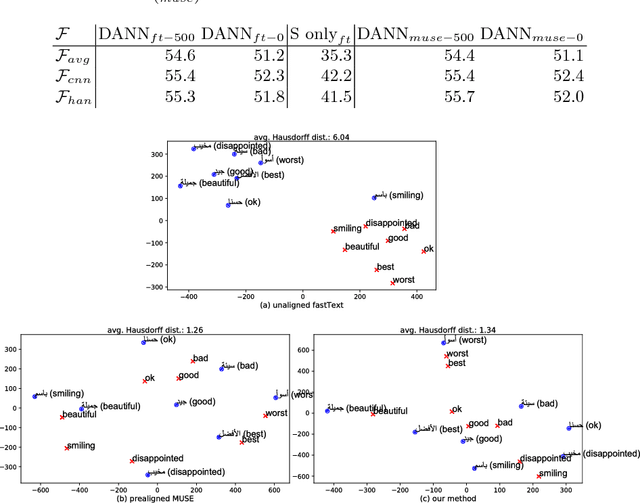
Deep learning techniques have recently shown to be successful in many natural language processing tasks forming state-of-the-art systems. They require, however, a large amount of annotated data which is often missing. This paper explores the use of domain-adversarial learning as a regularizer to avoid overfitting when training domain invariant features for deep, complex neural network in low-resource and zero-resource settings in new target domains or languages. In the case of new languages, we show that monolingual word-vectors can be directly used for training without pre-alignment. Their projection into a common space can be learnt ad-hoc at training time reaching the final performance of pretrained multilingual word-vectors.