Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Text Classification using Domain-Adversarial Learning
Paper and Code
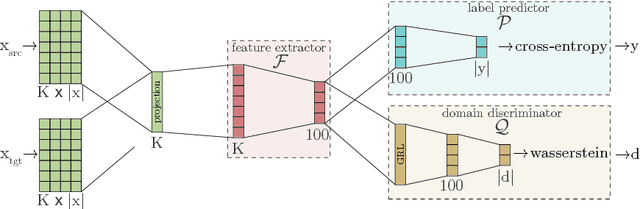
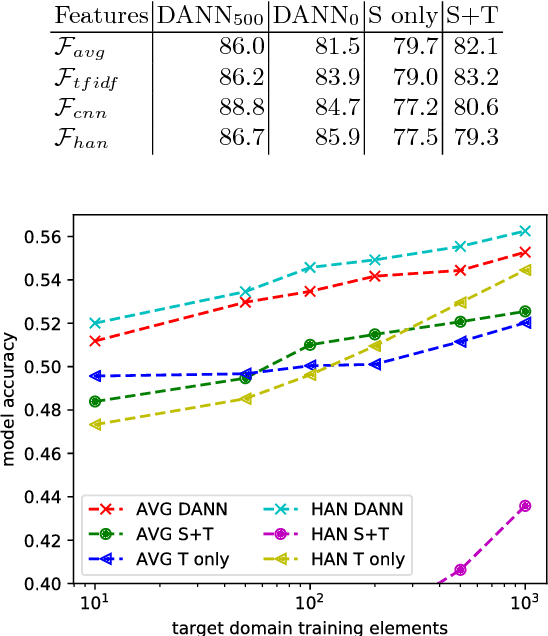
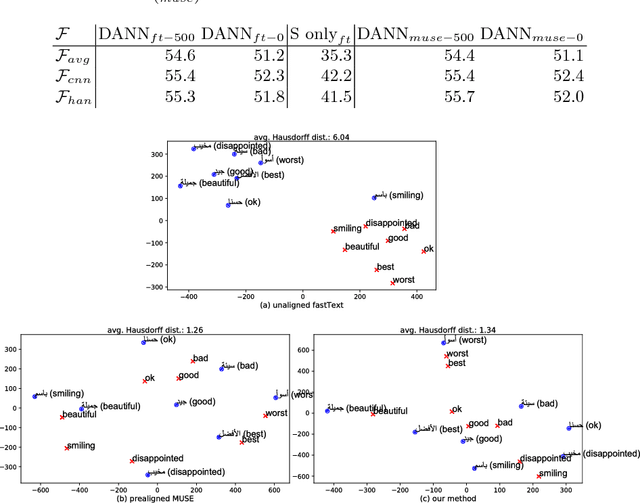
Deep learning techniques have recently shown to be successful in many natural language processing tasks forming state-of-the-art systems. They require, however, a large amount of annotated data which is often missing. This paper explores the use of domain-adversarial learning as a regularizer to avoid overfitting when training domain invariant features for deep, complex neural network in low-resource and zero-resource settings in new target domains or languages. In the case of new languages, we show that monolingual word-vectors can be directly used for training without pre-alignment. Their projection into a common space can be learnt ad-hoc at training time reaching the final performance of pretrained multilingual word-vectors.
* To be published on the 6th International Conference on Statistical
Language and Speech Processing (SLSP) 2018
View paper on