 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViPro-2: Unsupervised State Estimation via Integrated Dynamics for Guiding Video Prediction
Aug 08, 2025Predicting future video frames is a challenging task with many downstream applications. Previous work has shown that procedural knowledge enables deep models for complex dynamical settings, however their model ViPro assumed a given ground truth initial symbolic state. We show that this approach led to the model learning a shortcut that does not actually connect the observed environment with the predicted symbolic state, resulting in the inability to estimate states given an observation if previous states are noisy. In this work, we add several improvements to ViPro that enables the model to correctly infer states from observations without providing a full ground truth state in the beginning. We show that this is possible in an unsupervised manner, and extend the original Orbits dataset with a 3D variant to close the gap to real world scenarios.
Anonymization of Documents for Law Enforcement with Machine Learning
Jan 13, 2025



The steadily increasing utilization of data-driven methods and approaches in areas that handle sensitive personal information such as in law enforcement mandates an ever increasing effort in these institutions to comply with data protection guidelines. In this work, we present a system for automatically anonymizing images of scanned documents, reducing manual effort while ensuring data protection compliance. Our method considers the viability of further forensic processing after anonymization by minimizing automatically redacted areas by combining automatic detection of sensitive regions with knowledge from a manually anonymized reference document. Using a self-supervised image model for instance retrieval of the reference document, our approach requires only one anonymized example to efficiently redact all documents of the same type, significantly reducing processing time. We show that our approach outperforms both a purely automatic redaction system and also a naive copy-paste scheme of the reference anonymization to other documents on a hand-crafted dataset of ground truth redactions.
Guiding Video Prediction with Explicit Procedural Knowledge
Jun 26, 2024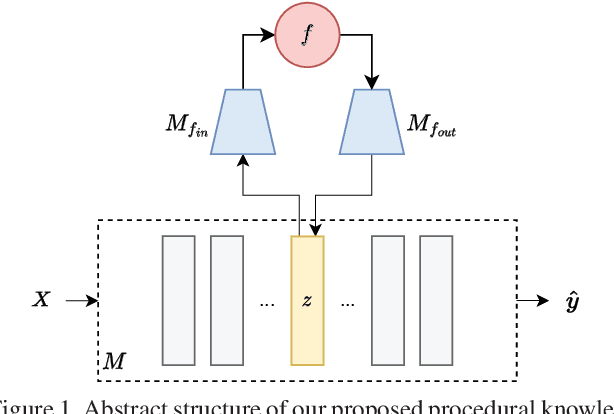

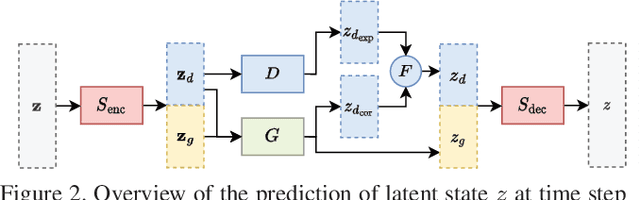

We propose a general way to integrate procedural knowledge of a domain into deep learning models. We apply it to the case of video prediction, building on top of object-centric deep models and show that this leads to a better performance than using data-driven models alone. We develop an architecture that facilitates latent space disentanglement in order to use the integrated procedural knowledge, and establish a setup that allows the model to learn the procedural interface in the latent space using the downstream task of video prediction. We contrast the performance to a state-of-the-art data-driven approach and show that problems where purely data-driven approaches struggle can be handled by using knowledge about the domain, providing an alternative to simply collecting more data.
* Published in 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)