 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLevel the Level: Balancing Game Levels for Asymmetric Player Archetypes With Reinforcement Learning
Mar 31, 2025

Balancing games, especially those with asymmetric multiplayer content, requires significant manual effort and extensive human playtesting during development. For this reason, this work focuses on generating balanced levels tailored to asymmetric player archetypes, where the disparity in abilities is balanced entirely through the level design. For instance, while one archetype may have an advantage over another, both should have an equal chance of winning. We therefore conceptualize game balancing as a procedural content generation problem and build on and extend a recently introduced method that uses reinforcement learning to balance tile-based game levels. We evaluate the method on four different player archetypes and demonstrate its ability to balance a larger proportion of levels compared to two baseline approaches. Furthermore, our results indicate that as the disparity between player archetypes increases, the required number of training steps grows, while the model's accuracy in achieving balance decreases.
Simulation-Driven Balancing of Competitive Game Levels with Reinforcement Learning
Mar 24, 2025



The balancing process for game levels in competitive two-player contexts involves a lot of manual work and testing, particularly for non-symmetrical game levels. In this work, we frame game balancing as a procedural content generation task and propose an architecture for automatically balancing of tile-based levels within the PCGRL framework (procedural content generation via reinforcement learning). Our architecture is divided into three parts: (1) a level generator, (2) a balancing agent, and (3) a reward modeling simulation. Through repeated simulations, the balancing agent receives rewards for adjusting the level towards a given balancing objective, such as equal win rates for all players. To this end, we propose new swap-based representations to improve the robustness of playability, thereby enabling agents to balance game levels more effectively and quickly compared to traditional PCGRL. By analyzing the agent's swapping behavior, we can infer which tile types have the most impact on the balance. We validate our approach in the Neural MMO (NMMO) environment in a competitive two-player scenario. In this extended conference paper, we present improved results, explore the applicability of the method to various forms of balancing beyond equal balancing, compare the performance to another search-based approach, and discuss the application of existing fairness metrics to game balancing.
* Preprint of the journal (IEEE Transactions on Games) paper of the same name
Unveiling the Decision-Making Process in Reinforcement Learning with Genetic Programming
Jul 20, 2024



Despite tremendous progress, machine learning and deep learning still suffer from incomprehensible predictions. Incomprehensibility, however, is not an option for the use of (deep) reinforcement learning in the real world, as unpredictable actions can seriously harm the involved individuals. In this work, we propose a genetic programming framework to generate explanations for the decision-making process of already trained agents by imitating them with programs. Programs are interpretable and can be executed to generate explanations of why the agent chooses a particular action. Furthermore, we conduct an ablation study that investigates how extending the domain-specific language by using library learning alters the performance of the method. We compare our results with the previous state of the art for this problem and show that we are comparable in performance but require much less hardware resources and computation time.
G-PCGRL: Procedural Graph Data Generation via Reinforcement Learning
Jul 15, 2024

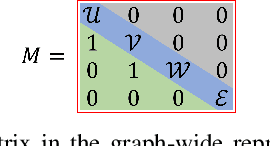

Graph data structures offer a versatile and powerful means to model relationships and interconnections in various domains, promising substantial advantages in data representation, analysis, and visualization. In games, graph-based data structures are omnipresent and represent, for example, game economies, skill trees or complex, branching quest lines. With this paper, we propose G-PCGRL, a novel and controllable method for the procedural generation of graph data using reinforcement learning. Therefore, we frame this problem as manipulating a graph's adjacency matrix to fulfill a given set of constraints. Our method adapts and extends the Procedural Content Generation via Reinforcement Learning (PCGRL) framework and introduces new representations to frame the problem of graph data generation as a Markov decision process. We compare the performance of our method with the original PCGRL, the run time with a random search and evolutionary algorithm, and evaluate G-PCGRL on two graph data domains in games: game economies and skill trees. The results show that our method is capable of generating graph-based content quickly and reliably to support and inspire designers in the game creation process. In addition, trained models are controllable in terms of the type and number of nodes to be generated.
GEEvo: Game Economy Generation and Balancing with Evolutionary Algorithms
Apr 29, 2024Game economy design significantly shapes the player experience and progression speed. Modern game economies are becoming increasingly complex and can be very sensitive to even minor numerical adjustments, which may have an unexpected impact on the overall gaming experience. Consequently, thorough manual testing and fine-tuning during development are essential. Unlike existing works that address algorithmic balancing for specific games or genres, this work adopts a more abstract approach, focusing on game balancing through its economy, detached from a specific game. We propose GEEvo (Game Economy Evolution), a framework to generate graph-based game economies and balancing both, newly generated or existing economies. GEEvo uses a two-step approach where evolutionary algorithms are used to first generate an economy and then balance it based on specified objectives, such as generated resources or damage dealt over time. We define different objectives by differently parameterizing the fitness function using data from multiple simulation runs of the economy. To support this, we define a lightweight and flexible game economy simulation framework. Our method is tested and benchmarked with various balancing objectives on a generated dataset, and we conduct a case study evaluating damage balancing for two fictional economies of two popular game character classes.
Balancing of competitive two-player Game Levels with Reinforcement Learning
Jun 07, 2023The balancing process for game levels in a competitive two-player context involves a lot of manual work and testing, particularly in non-symmetrical game levels. In this paper, we propose an architecture for automated balancing of tile-based levels within the recently introduced PCGRL framework (procedural content generation via reinforcement learning). Our architecture is divided into three parts: (1) a level generator, (2) a balancing agent and, (3) a reward modeling simulation. By playing the level in a simulation repeatedly, the balancing agent is rewarded for modifying it towards the same win rates for all players. To this end, we introduce a novel family of swap-based representations to increase robustness towards playability. We show that this approach is capable to teach an agent how to alter a level for balancing better and faster than plain PCGRL. In addition, by analyzing the agent's swapping behavior, we can draw conclusions about which tile types influence the balancing most. We test and show our results using the Neural MMO (NMMO) environment in a competitive two-player setting.