 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLevel the Level: Balancing Game Levels for Asymmetric Player Archetypes With Reinforcement Learning
Mar 31, 2025

Balancing games, especially those with asymmetric multiplayer content, requires significant manual effort and extensive human playtesting during development. For this reason, this work focuses on generating balanced levels tailored to asymmetric player archetypes, where the disparity in abilities is balanced entirely through the level design. For instance, while one archetype may have an advantage over another, both should have an equal chance of winning. We therefore conceptualize game balancing as a procedural content generation problem and build on and extend a recently introduced method that uses reinforcement learning to balance tile-based game levels. We evaluate the method on four different player archetypes and demonstrate its ability to balance a larger proportion of levels compared to two baseline approaches. Furthermore, our results indicate that as the disparity between player archetypes increases, the required number of training steps grows, while the model's accuracy in achieving balance decreases.
Simulation-Driven Balancing of Competitive Game Levels with Reinforcement Learning
Mar 24, 2025



The balancing process for game levels in competitive two-player contexts involves a lot of manual work and testing, particularly for non-symmetrical game levels. In this work, we frame game balancing as a procedural content generation task and propose an architecture for automatically balancing of tile-based levels within the PCGRL framework (procedural content generation via reinforcement learning). Our architecture is divided into three parts: (1) a level generator, (2) a balancing agent, and (3) a reward modeling simulation. Through repeated simulations, the balancing agent receives rewards for adjusting the level towards a given balancing objective, such as equal win rates for all players. To this end, we propose new swap-based representations to improve the robustness of playability, thereby enabling agents to balance game levels more effectively and quickly compared to traditional PCGRL. By analyzing the agent's swapping behavior, we can infer which tile types have the most impact on the balance. We validate our approach in the Neural MMO (NMMO) environment in a competitive two-player scenario. In this extended conference paper, we present improved results, explore the applicability of the method to various forms of balancing beyond equal balancing, compare the performance to another search-based approach, and discuss the application of existing fairness metrics to game balancing.
* Preprint of the journal (IEEE Transactions on Games) paper of the same name
G-PCGRL: Procedural Graph Data Generation via Reinforcement Learning
Jul 15, 2024

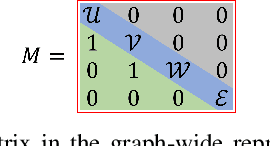

Graph data structures offer a versatile and powerful means to model relationships and interconnections in various domains, promising substantial advantages in data representation, analysis, and visualization. In games, graph-based data structures are omnipresent and represent, for example, game economies, skill trees or complex, branching quest lines. With this paper, we propose G-PCGRL, a novel and controllable method for the procedural generation of graph data using reinforcement learning. Therefore, we frame this problem as manipulating a graph's adjacency matrix to fulfill a given set of constraints. Our method adapts and extends the Procedural Content Generation via Reinforcement Learning (PCGRL) framework and introduces new representations to frame the problem of graph data generation as a Markov decision process. We compare the performance of our method with the original PCGRL, the run time with a random search and evolutionary algorithm, and evaluate G-PCGRL on two graph data domains in games: game economies and skill trees. The results show that our method is capable of generating graph-based content quickly and reliably to support and inspire designers in the game creation process. In addition, trained models are controllable in terms of the type and number of nodes to be generated.
GEEvo: Game Economy Generation and Balancing with Evolutionary Algorithms
Apr 29, 2024Game economy design significantly shapes the player experience and progression speed. Modern game economies are becoming increasingly complex and can be very sensitive to even minor numerical adjustments, which may have an unexpected impact on the overall gaming experience. Consequently, thorough manual testing and fine-tuning during development are essential. Unlike existing works that address algorithmic balancing for specific games or genres, this work adopts a more abstract approach, focusing on game balancing through its economy, detached from a specific game. We propose GEEvo (Game Economy Evolution), a framework to generate graph-based game economies and balancing both, newly generated or existing economies. GEEvo uses a two-step approach where evolutionary algorithms are used to first generate an economy and then balance it based on specified objectives, such as generated resources or damage dealt over time. We define different objectives by differently parameterizing the fitness function using data from multiple simulation runs of the economy. To support this, we define a lightweight and flexible game economy simulation framework. Our method is tested and benchmarked with various balancing objectives on a generated dataset, and we conduct a case study evaluating damage balancing for two fictional economies of two popular game character classes.
ACLSum: A New Dataset for Aspect-based Summarization of Scientific Publications
Mar 08, 2024



Extensive efforts in the past have been directed toward the development of summarization datasets. However, a predominant number of these resources have been (semi)-automatically generated, typically through web data crawling, resulting in subpar resources for training and evaluating summarization systems, a quality compromise that is arguably due to the substantial costs associated with generating ground-truth summaries, particularly for diverse languages and specialized domains. To address this issue, we present ACLSum, a novel summarization dataset carefully crafted and evaluated by domain experts. In contrast to previous datasets, ACLSum facilitates multi-aspect summarization of scientific papers, covering challenges, approaches, and outcomes in depth. Through extensive experiments, we evaluate the quality of our resource and the performance of models based on pretrained language models and state-of-the-art large language models (LLMs). Additionally, we explore the effectiveness of extractive versus abstractive summarization within the scholarly domain on the basis of automatically discovered aspects. Our results corroborate previous findings in the general domain and indicate the general superiority of end-to-end aspect-based summarization. Our data is released at https://github.com/sobamchan/aclsum.
ROUGE-K: Do Your Summaries Have Keywords?
Mar 08, 2024



Keywords, that is, content-relevant words in summaries play an important role in efficient information conveyance, making it critical to assess if system-generated summaries contain such informative words during evaluation. However, existing evaluation metrics for extreme summarization models do not pay explicit attention to keywords in summaries, leaving developers ignorant of their presence. To address this issue, we present a keyword-oriented evaluation metric, dubbed ROUGE-K, which provides a quantitative answer to the question of -- \textit{How well do summaries include keywords?} Through the lens of this keyword-aware metric, we surprisingly find that a current strong baseline model often misses essential information in their summaries. Our analysis reveals that human annotators indeed find the summaries with more keywords to be more relevant to the source documents. This is an important yet previously overlooked aspect in evaluating summarization systems. Finally, to enhance keyword inclusion, we propose four approaches for incorporating word importance into a transformer-based model and experimentally show that it enables guiding models to include more keywords while keeping the overall quality. Our code is released at https://github.com/sobamchan/rougek.
Balancing of competitive two-player Game Levels with Reinforcement Learning
Jun 07, 2023The balancing process for game levels in a competitive two-player context involves a lot of manual work and testing, particularly in non-symmetrical game levels. In this paper, we propose an architecture for automated balancing of tile-based levels within the recently introduced PCGRL framework (procedural content generation via reinforcement learning). Our architecture is divided into three parts: (1) a level generator, (2) a balancing agent and, (3) a reward modeling simulation. By playing the level in a simulation repeatedly, the balancing agent is rewarded for modifying it towards the same win rates for all players. To this end, we introduce a novel family of swap-based representations to increase robustness towards playability. We show that this approach is capable to teach an agent how to alter a level for balancing better and faster than plain PCGRL. In addition, by analyzing the agent's swapping behavior, we can draw conclusions about which tile types influence the balancing most. We test and show our results using the Neural MMO (NMMO) environment in a competitive two-player setting.
Overview of the SV-Ident 2022 Shared Task on Survey Variable Identification in Social Science Publications
Sep 19, 2022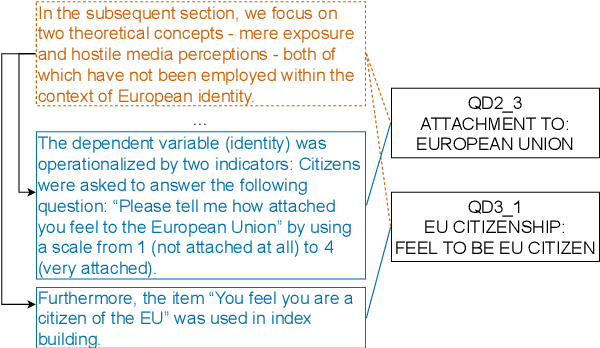
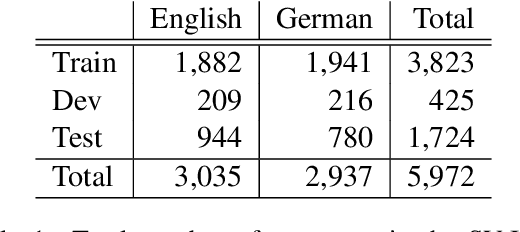

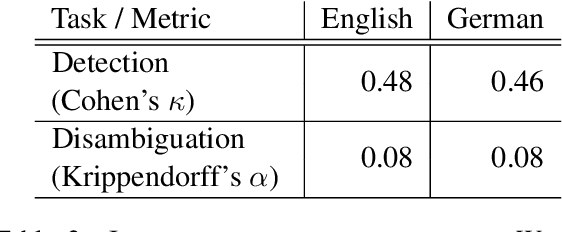
In this paper, we provide an overview of the SV-Ident shared task as part of the 3rd Workshop on Scholarly Document Processing (SDP) at COLING 2022. In the shared task, participants were provided with a sentence and a vocabulary of variables, and asked to identify which variables, if any, are mentioned in individual sentences from scholarly documents in full text. Two teams made a total of 9 submissions to the shared task leaderboard. While none of the teams improve on the baseline systems, we still draw insights from their submissions. Furthermore, we provide a detailed evaluation. Data and baselines for our shared task are freely available at https://github.com/vadis-project/sv-ident
Towards Automated Survey Variable Search and Summarization in Social Science Publications
Sep 14, 2022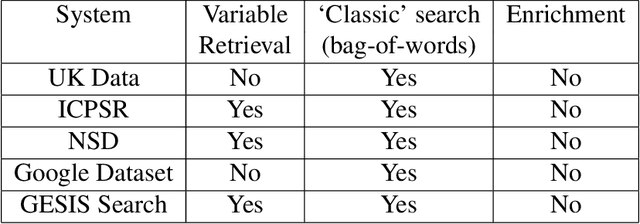
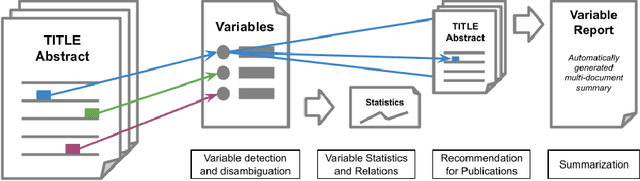
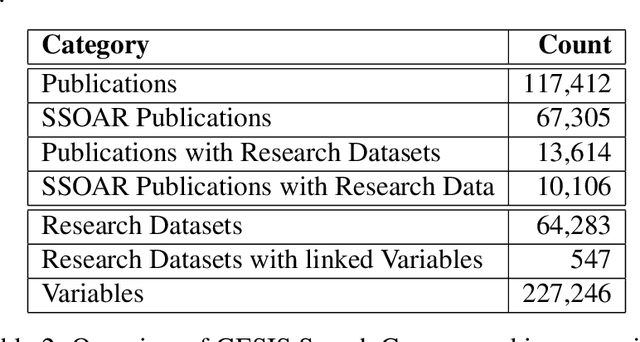
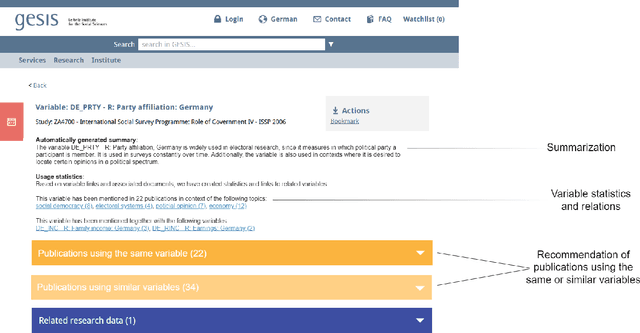
Nowadays there is a growing trend in many scientific disciplines to support researchers by providing enhanced information access through linking of publications and underlying datasets, so as to support research with infrastructure to enhance reproducibility and reusability of research results. In this research note, we present an overview of an ongoing research project, named VADIS (VAriable Detection, Interlinking and Summarization), that aims at developing technology and infrastructure for enhanced information access in the Social Sciences via search and summarization of publications on the basis of automatic identification and indexing of survey variables in text. We provide an overview of the overarching vision underlying our project, its main components, and related challenges, as well as a thorough discussion of how these are meant to address the limitations of current information access systems for publications in the Social Sciences. We show how this goal can be concretely implemented in an end-user system by presenting a search prototype, which is based on user requirements collected from qualitative interviews with empirical Social Science researchers.
X-SCITLDR: Cross-Lingual Extreme Summarization of Scholarly Documents
May 30, 2022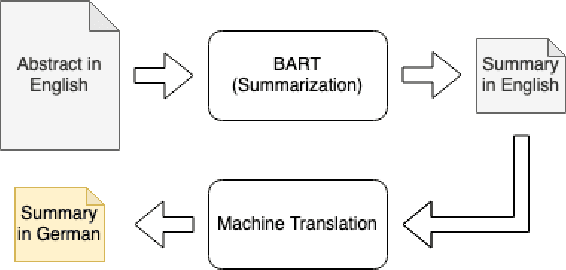

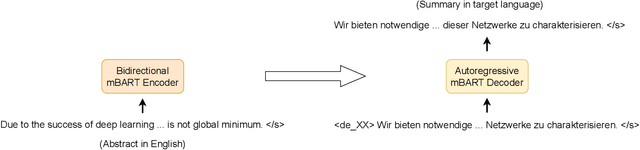

The number of scientific publications nowadays is rapidly increasing, causing information overload for researchers and making it hard for scholars to keep up to date with current trends and lines of work. Consequently, recent work on applying text mining technologies for scholarly publications has investigated the application of automatic text summarization technologies, including extreme summarization, for this domain. However, previous work has concentrated only on monolingual settings, primarily in English. In this paper, we fill this research gap and present an abstractive cross-lingual summarization dataset for four different languages in the scholarly domain, which enables us to train and evaluate models that process English papers and generate summaries in German, Italian, Chinese and Japanese. We present our new X-SCITLDR dataset for multilingual summarization and thoroughly benchmark different models based on a state-of-the-art multilingual pre-trained model, including a two-stage `summarize and translate' approach and a direct cross-lingual model. We additionally explore the benefits of intermediate-stage training using English monolingual summarization and machine translation as intermediate tasks and analyze performance in zero- and few-shot scenarios.