 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewrite the News: Tracing Editorial Reuse Across News Agencies
Mar 31, 2026This paper investigates sentence-level text reuse in multilingual journalism, analyzing where reused content occurs within articles. We present a weakly supervised method for detecting sentence-level cross-lingual reuse without requiring full translations, designed to support automated pre-selection to reduce information overload for journalists (Holyst et al., 2024). The study compares English-language articles from the Slovenian Press Agency (STA) with reports from 15 foreign agencies (FA) in seven languages, using publication timestamps to retain the earliest likely foreign source for each reused sentence. We analyze 1,037 STA and 237,551 FA articles from two time windows (October 7-November 2, 2023; February 1-28, 2025) and identify 1,087 aligned sentence pairs after filtering to the earliest sources. Reuse occurs in 52% of STA articles and 1.6% of FA articles and is predominantly non-literal, involving paraphrase and compositional reuse from multiple sources. Reused content tends to appear in the middle and end of English articles, while leads are more often original, indicating that simple lexical matching overlooks substantial editorial reuse. Compared with prior work focused on monolingual overlap, we (i) detect reuse across languages without requiring full translation, (ii) use publication timing to identify likely sources, and (iii) analyze where reused material is situated within articles. Dataset and code: https://github.com/kunturs/lrec2026-rewrite-news.
Analysing Calls to Order in German Parliamentary Debates
Mar 27, 2026Parliamentary debate constitutes a central arena of political power, shaping legislative outcomes and public discourse. Incivility within this arena signals political polarization and institutional conflict. This study presents a systematic investigation of incivility in the German Bundestag by examining calls to order (CtO; plural: CtOs) as formal indicators of norm violations. Despite their relevance, CtOs have received little systematic attention in parliamentary research. We introduce a rule-based method for detecting and annotating CtOs in parliamentary speeches and present a novel dataset of German parliamentary debates spanning 72 years that includes annotated CtO instances. Additionally, we develop the first classification system for CtO triggers and analyze the factors associated with their occurrence. Our findings show that, despite formal regulations, the issuance of CtOs is partly subjective and influenced by session presidents and parliamentary dynamics, with certain individuals disproportionately affected. An insult towards individuals is the most frequent cause of CtO. In general, male members and those belonging to opposition parties receive more calls to order than their female and coalition-party counterparts. Most CtO triggers were detected in speeches dedicated to governmental affairs and actions of the presidency. The CtO triggers dataset is available at: https://github.com/kalawinka/cto_analysis.
Cultural Analytics for Good: Building Inclusive Evaluation Frameworks for Historical IR
Jan 17, 2026This work bridges the fields of information retrieval and cultural analytics to support equitable access to historical knowledge. Using the British Library BL19 digital collection (more than 35,000 works from 1700-1899), we construct a benchmark for studying changes in language, terminology and retrieval in the 19th-century fiction and non-fiction. Our approach combines expert-driven query design, paragraph-level relevance annotation, and Large Language Model (LLM) assistance to create a scalable evaluation framework grounded in human expertise. We focus on knowledge transfer from fiction to non-fiction, investigating how narrative understanding and semantic richness in fiction can improve retrieval for scholarly and factual materials. This interdisciplinary framework not only improves retrieval accuracy but also fosters interpretability, transparency, and cultural inclusivity in digital archives. Our work provides both practical evaluation resources and a methodological paradigm for developing retrieval systems that support richer, historically aware engagement with digital archives, ultimately working towards more emancipatory knowledge infrastructures.
NFDI4DS Shared Tasks for Scholarly Document Processing
Sep 26, 2025Shared tasks are powerful tools for advancing research through community-based standardised evaluation. As such, they play a key role in promoting findable, accessible, interoperable, and reusable (FAIR), as well as transparent and reproducible research practices. This paper presents an updated overview of twelve shared tasks developed and hosted under the German National Research Data Infrastructure for Data Science and Artificial Intelligence (NFDI4DS) consortium, covering a diverse set of challenges in scholarly document processing. Hosted at leading venues, the tasks foster methodological innovations and contribute open-access datasets, models, and tools for the broader research community, which are integrated into the consortium's research data infrastructure.
Chatting with Papers: A Hybrid Approach Using LLMs and Knowledge Graphs
May 16, 2025This demo paper reports on a new workflow \textit{GhostWriter} that combines the use of Large Language Models and Knowledge Graphs (semantic artifacts) to support navigation through collections. Situated in the research area of Retrieval Augmented Generation, this specific workflow details the creation of local and adaptable chatbots. Based on the tool-suite \textit{EverythingData} at the backend, \textit{GhostWriter} provides an interface that enables querying and ``chatting'' with a collection. Applied iteratively, the workflow supports the information needs of researchers when interacting with a collection of papers, whether it be to gain an overview, to learn more about a specific concept and its context, and helps the researcher ultimately to refine their research question in a controlled way. We demonstrate the workflow for a collection of articles from the \textit{method data analysis} journal published by GESIS -- Leibniz-Institute for the Social Sciences. We also point to further application areas.
Annotating Scientific Uncertainty: A comprehensive model using linguistic patterns and comparison with existing approaches
Mar 14, 2025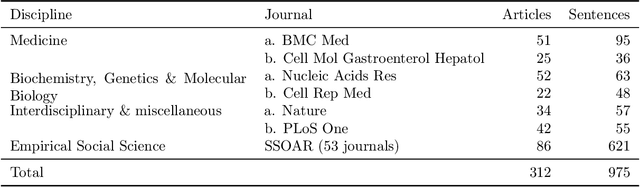

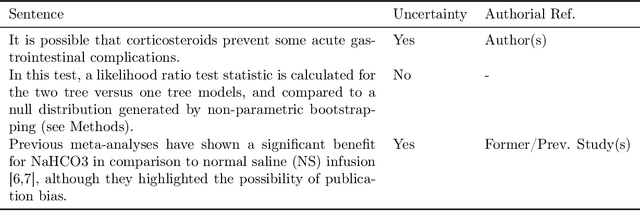
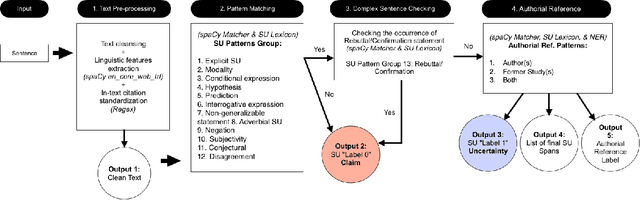
UnScientify, a system designed to detect scientific uncertainty in scholarly full text. The system utilizes a weakly supervised technique to identify verbally expressed uncertainty in scientific texts and their authorial references. The core methodology of UnScientify is based on a multi-faceted pipeline that integrates span pattern matching, complex sentence analysis and author reference checking. This approach streamlines the labeling and annotation processes essential for identifying scientific uncertainty, covering a variety of uncertainty expression types to support diverse applications including information retrieval, text mining and scientific document processing. The evaluation results highlight the trade-offs between modern large language models (LLMs) and the UnScientify system. UnScientify, which employs more traditional techniques, achieved superior performance in the scientific uncertainty detection task, attaining an accuracy score of 0.808. This finding underscores the continued relevance and efficiency of UnScientify's simple rule-based and pattern matching strategy for this specific application. The results demonstrate that in scenarios where resource efficiency, interpretability, and domain-specific adaptability are critical, traditional methods can still offer significant advantages.
Originality in scientific titles and abstracts can predict citation count
Feb 03, 2025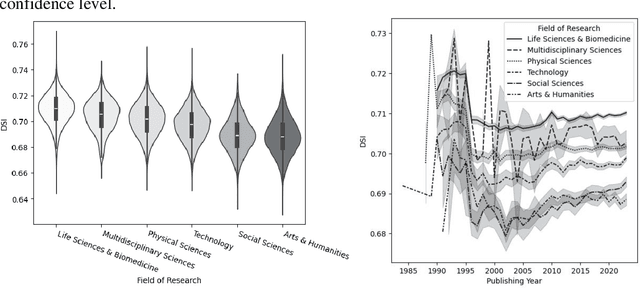
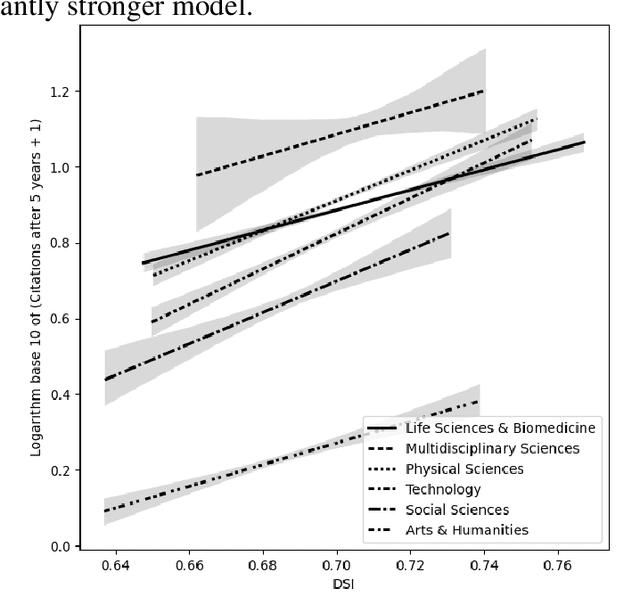
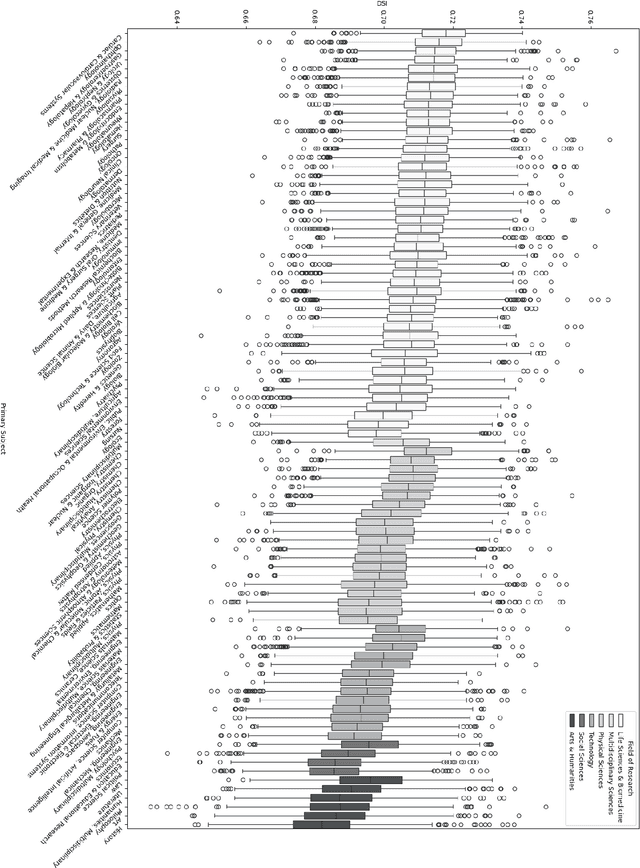
In this research-in-progress paper, we apply a computational measure correlating with originality from creativity science: Divergent Semantic Integration (DSI), to a selection of 99,557 scientific abstracts and titles selected from the Web of Science. We observe statistically significant differences in DSI between subject and field of research, and a slight rise in DSI over time. We model the base 10 logarithm of the citation count after 5 years with DSI and find a statistically significant positive correlation in all fields of research with an adjusted $R^2$ of 0.13.
Utilizing Large Language Models for Named Entity Recognition in Traditional Chinese Medicine against COVID-19 Literature: Comparative Study
Aug 24, 2024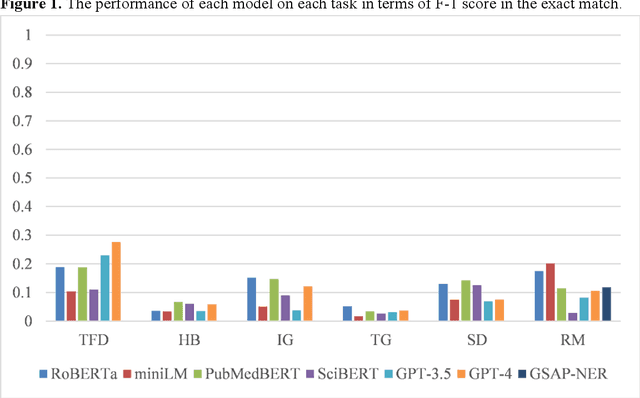
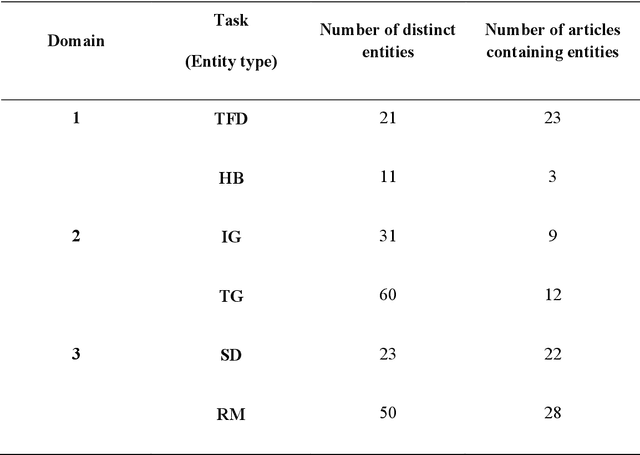
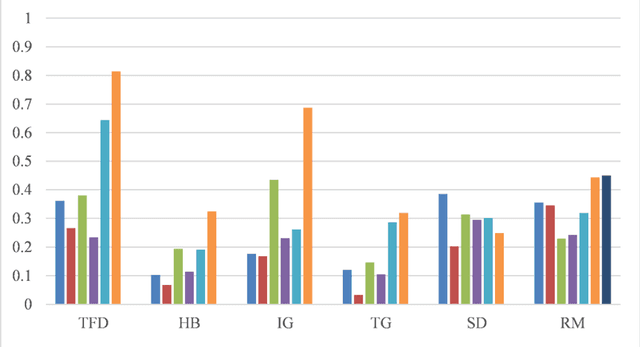
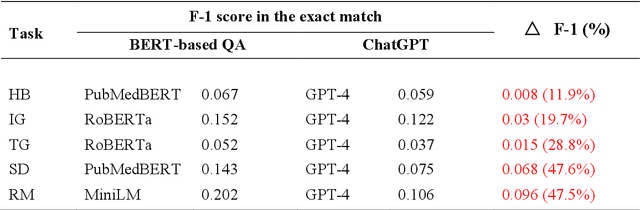
Objective: To explore and compare the performance of ChatGPT and other state-of-the-art LLMs on domain-specific NER tasks covering different entity types and domains in TCM against COVID-19 literature. Methods: We established a dataset of 389 articles on TCM against COVID-19, and manually annotated 48 of them with 6 types of entities belonging to 3 domains as the ground truth, against which the NER performance of LLMs can be assessed. We then performed NER tasks for the 6 entity types using ChatGPT (GPT-3.5 and GPT-4) and 4 state-of-the-art BERT-based question-answering (QA) models (RoBERTa, MiniLM, PubMedBERT and SciBERT) without prior training on the specific task. A domain fine-tuned model (GSAP-NER) was also applied for a comprehensive comparison. Results: The overall performance of LLMs varied significantly in exact match and fuzzy match. In the fuzzy match, ChatGPT surpassed BERT-based QA models in 5 out of 6 tasks, while in exact match, BERT-based QA models outperformed ChatGPT in 5 out of 6 tasks but with a smaller F-1 difference. GPT-4 showed a significant advantage over other models in fuzzy match, especially on the entity type of TCM formula and the Chinese patent drug (TFD) and ingredient (IG). Although GPT-4 outperformed BERT-based models on entity type of herb, target, and research method, none of the F-1 scores exceeded 0.5. GSAP-NER, outperformed GPT-4 in terms of F-1 by a slight margin on RM. ChatGPT achieved considerably higher recalls than precisions, particularly in the fuzzy match. Conclusions: The NER performance of LLMs is highly dependent on the entity type, and their performance varies across application scenarios. ChatGPT could be a good choice for scenarios where high recall is favored. However, for knowledge acquisition in rigorous scenarios, neither ChatGPT nor BERT-based QA models are off-the-shelf tools for professional practitioners.
VADIS -- a VAriable Detection, Interlinking and Summarization system
Dec 20, 2023The VADIS system addresses the demand of providing enhanced information access in the domain of the social sciences. This is achieved by allowing users to search and use survey variables in context of their underlying research data and scholarly publications which have been interlinked with each other.
UnScientify: Detecting Scientific Uncertainty in Scholarly Full Text
Jul 26, 2023



This demo paper presents UnScientify, an interactive system designed to detect scientific uncertainty in scholarly full text. The system utilizes a weakly supervised technique that employs a fine-grained annotation scheme to identify verbally formulated uncertainty at the sentence level in scientific texts. The pipeline for the system includes a combination of pattern matching, complex sentence checking, and authorial reference checking. Our approach automates labeling and annotation tasks for scientific uncertainty identification, taking into account different types of scientific uncertainty, that can serve various applications such as information retrieval, text mining, and scholarly document processing. Additionally, UnScientify provides interpretable results, aiding in the comprehension of identified instances of scientific uncertainty in text.