 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrievability in an Integrated Retrieval System: An Extended Study
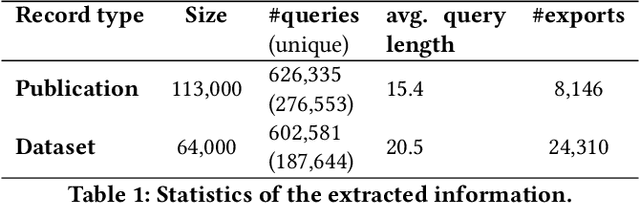
Mar 27, 2023Retrievability measures the influence a retrieval system has on the access to information in a given collection of items. This measure can help in making an evaluation of the search system based on which insights can be drawn. In this paper, we investigate the retrievability in an integrated search system consisting of items from various categories, particularly focussing on datasets, publications \ijdl{and variables} in a real-life Digital Library (DL). The traditional metrics, that is, the Lorenz curve and Gini coefficient, are employed to visualize the diversity in retrievability scores of the \ijdl{three} retrievable document types (specifically datasets, publications, and variables). Our results show a significant popularity bias with certain items being retrieved more often than others. Particularly, it has been shown that certain datasets are more likely to be retrieved than other datasets in the same category. In contrast, the retrievability scores of items from the variable or publication category are more evenly distributed. We have observed that the distribution of document retrievability is more diverse for datasets as compared to publications and variables.
Studying Retrievability of Publications and Datasets in an Integrated Retrieval System
May 02, 2022


In this paper, we investigate the retrievability of datasets and publications in a real-life Digital Library (DL). The measure of retrievability was originally developed to quantify the influence that a retrieval system has on the access to information. Retrievability can also enable DL engineers to evaluate their search engine to determine the ease with which the content in the collection can be accessed. Following this methodology, in our study, we propose a system-oriented approach for studying dataset and publication retrieval. A speciality of this paper is the focus on measuring the accessibility biases of various types of DL items and including a metric of usefulness. Among other metrics, we use Lorenz curves and Gini coefficients to visualize the differences of the two retrievable document types (specifically datasets and publications). Empirical results reported in the paper show a distinguishable diversity in the retrievability scores among the documents of different types.
ConSTR: A Contextual Search Term Recommender
Jun 08, 2021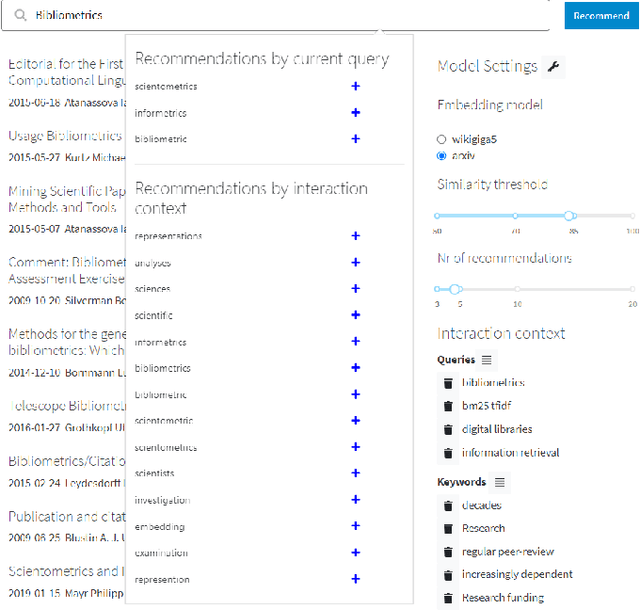
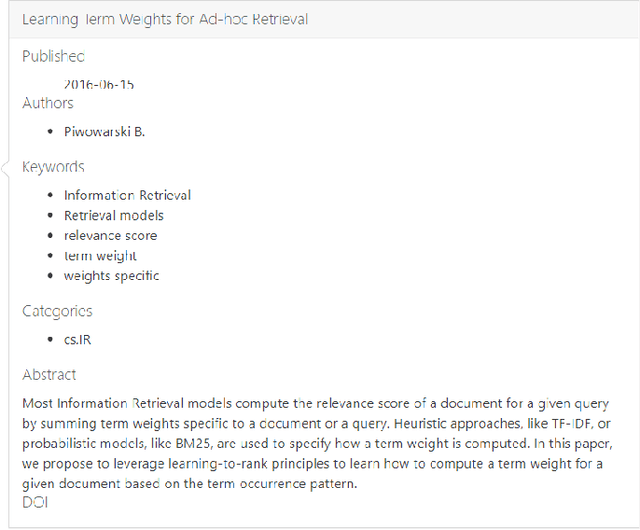
In this demo paper, we present ConSTR, a novel Contextual Search Term Recommender that utilises the user's interaction context for search term recommendation and literature retrieval. ConSTR integrates a two-layered recommendation interface: the first layer suggests terms with respect to a user's current search term, and the second layer suggests terms based on the users' previous search activities (interaction context). For the demonstration, ConSTR is built on the arXiv, an academic repository consisting of 1.8 million documents.