 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Large Language Models for Named Entity Recognition in Traditional Chinese Medicine against COVID-19 Literature: Comparative Study
Aug 24, 2024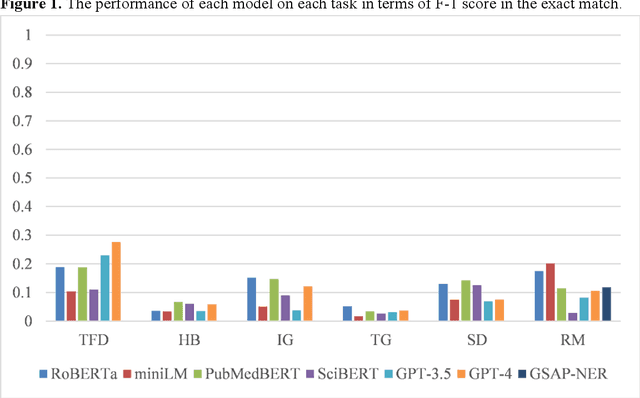
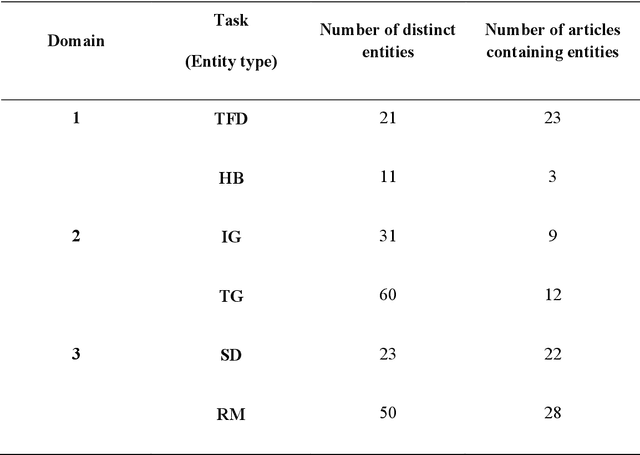
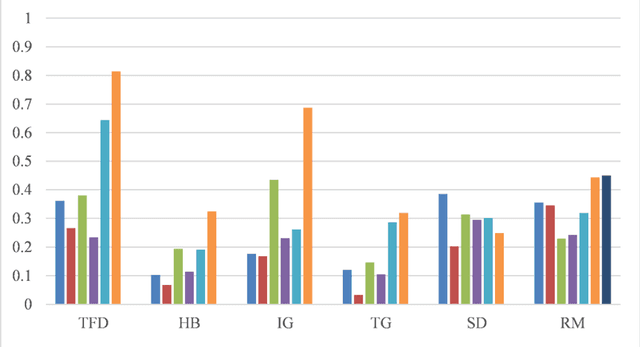
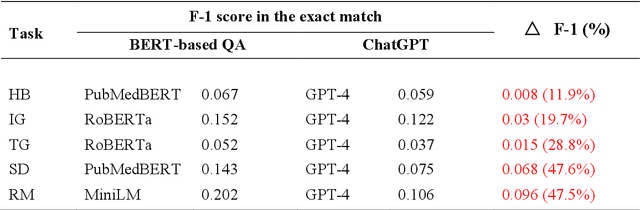
Objective: To explore and compare the performance of ChatGPT and other state-of-the-art LLMs on domain-specific NER tasks covering different entity types and domains in TCM against COVID-19 literature. Methods: We established a dataset of 389 articles on TCM against COVID-19, and manually annotated 48 of them with 6 types of entities belonging to 3 domains as the ground truth, against which the NER performance of LLMs can be assessed. We then performed NER tasks for the 6 entity types using ChatGPT (GPT-3.5 and GPT-4) and 4 state-of-the-art BERT-based question-answering (QA) models (RoBERTa, MiniLM, PubMedBERT and SciBERT) without prior training on the specific task. A domain fine-tuned model (GSAP-NER) was also applied for a comprehensive comparison. Results: The overall performance of LLMs varied significantly in exact match and fuzzy match. In the fuzzy match, ChatGPT surpassed BERT-based QA models in 5 out of 6 tasks, while in exact match, BERT-based QA models outperformed ChatGPT in 5 out of 6 tasks but with a smaller F-1 difference. GPT-4 showed a significant advantage over other models in fuzzy match, especially on the entity type of TCM formula and the Chinese patent drug (TFD) and ingredient (IG). Although GPT-4 outperformed BERT-based models on entity type of herb, target, and research method, none of the F-1 scores exceeded 0.5. GSAP-NER, outperformed GPT-4 in terms of F-1 by a slight margin on RM. ChatGPT achieved considerably higher recalls than precisions, particularly in the fuzzy match. Conclusions: The NER performance of LLMs is highly dependent on the entity type, and their performance varies across application scenarios. ChatGPT could be a good choice for scenarios where high recall is favored. However, for knowledge acquisition in rigorous scenarios, neither ChatGPT nor BERT-based QA models are off-the-shelf tools for professional practitioners.
UniMEL: A Unified Framework for Multimodal Entity Linking with Large Language Models
Jul 23, 2024

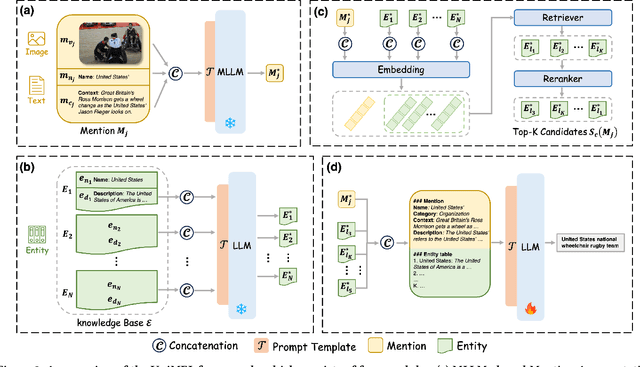
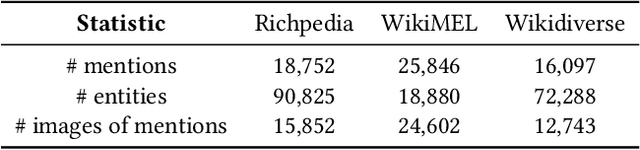
Multimodal Entity Linking (MEL) is a crucial task that aims at linking ambiguous mentions within multimodal contexts to the referent entities in a multimodal knowledge base, such as Wikipedia. Existing methods focus heavily on using complex mechanisms and extensive model tuning methods to model the multimodal interaction on specific datasets. However, these methods overcomplicate the MEL task and overlook the visual semantic information, which makes them costly and hard to scale. Moreover, these methods can not solve the issues like textual ambiguity, redundancy, and noisy images, which severely degrade their performance. Fortunately, the advent of Large Language Models (LLMs) with robust capabilities in text understanding and reasoning, particularly Multimodal Large Language Models (MLLMs) that can process multimodal inputs, provides new insights into addressing this challenge. However, how to design a universally applicable LLMs-based MEL approach remains a pressing challenge. To this end, we propose UniMEL, a unified framework which establishes a new paradigm to process multimodal entity linking tasks using LLMs. In this framework, we employ LLMs to augment the representation of mentions and entities individually by integrating textual and visual information and refining textual information. Subsequently, we employ the embedding-based method for retrieving and re-ranking candidate entities. Then, with only ~0.26% of the model parameters fine-tuned, LLMs can make the final selection from the candidate entities. Extensive experiments on three public benchmark datasets demonstrate that our solution achieves state-of-the-art performance, and ablation studies verify the effectiveness of all modules. Our code is available at https://anonymous.4open.science/r/UniMEL/.