 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMEL: A Unified Framework for Multimodal Entity Linking with Large Language Models
Jul 23, 2024

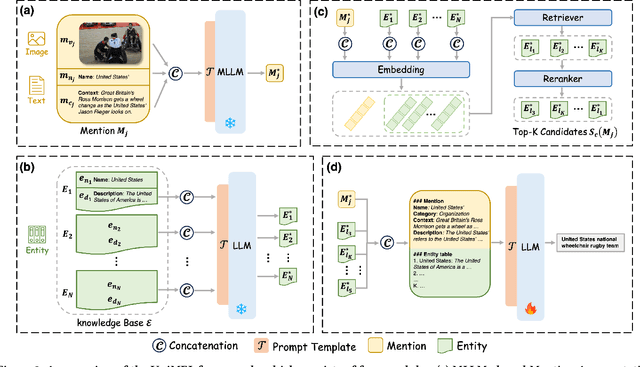
Multimodal Entity Linking (MEL) is a crucial task that aims at linking ambiguous mentions within multimodal contexts to the referent entities in a multimodal knowledge base, such as Wikipedia. Existing methods focus heavily on using complex mechanisms and extensive model tuning methods to model the multimodal interaction on specific datasets. However, these methods overcomplicate the MEL task and overlook the visual semantic information, which makes them costly and hard to scale. Moreover, these methods can not solve the issues like textual ambiguity, redundancy, and noisy images, which severely degrade their performance. Fortunately, the advent of Large Language Models (LLMs) with robust capabilities in text understanding and reasoning, particularly Multimodal Large Language Models (MLLMs) that can process multimodal inputs, provides new insights into addressing this challenge. However, how to design a universally applicable LLMs-based MEL approach remains a pressing challenge. To this end, we propose UniMEL, a unified framework which establishes a new paradigm to process multimodal entity linking tasks using LLMs. In this framework, we employ LLMs to augment the representation of mentions and entities individually by integrating textual and visual information and refining textual information. Subsequently, we employ the embedding-based method for retrieving and re-ranking candidate entities. Then, with only ~0.26% of the model parameters fine-tuned, LLMs can make the final selection from the candidate entities. Extensive experiments on three public benchmark datasets demonstrate that our solution achieves state-of-the-art performance, and ablation studies verify the effectiveness of all modules. Our code is available at https://anonymous.4open.science/r/UniMEL/.
Automatic detection of aerial survey ground control points based on Yolov5-OBB
Mar 06, 2023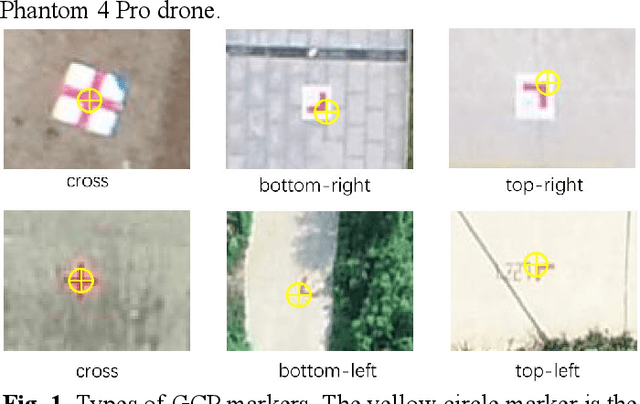

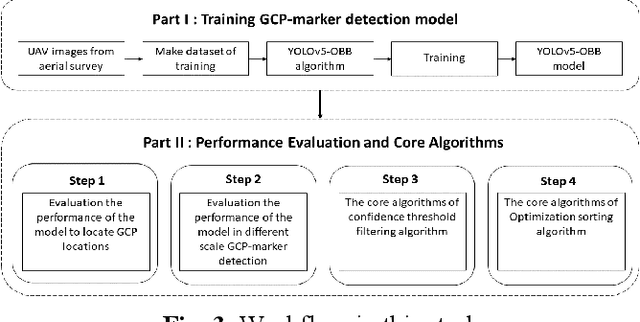
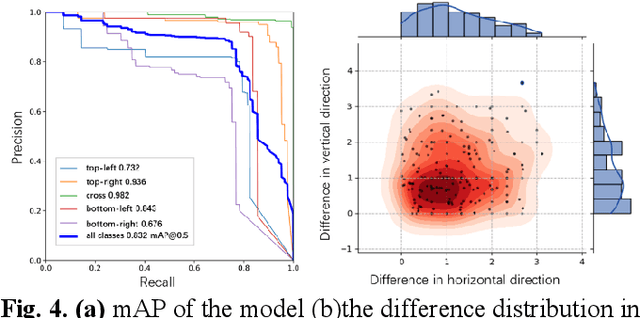
The use of ground control points (GCPs) for georeferencing is the most common strategy in unmanned aerial vehicle (UAV) photogrammetry, but at the same time their collection represents the most time-consuming and expensive part of UAV campaigns. Recently, deep learning has been rapidly developed in the field of small object detection. In this letter, to automatically extract coordinates information of ground control points (GCPs) by detecting GCP-markers in UAV images, we propose a solution that uses a deep learning-based architecture, YOLOv5-OBB, combined with a confidence threshold filtering algorithm and an optimal ranking algorithm. We applied our proposed method to a dataset collected by DJI Phantom 4 Pro drone and obtained good detection performance with the mean Average Precision (AP) of 0.832 and the highest AP of 0.982 for the cross-type GCP-markers. The proposed method can be a promising tool for future implementation of the end-to-end aerial triangulation process.