 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVII-3D: Advancing Roadside Infrastructure Inventory with Decimeter-level 3D Localization and Comprehension from Sparse Street Imagery
Jan 15, 2026The automated creation of digital twins and precise asset inventories is a critical task in smart city construction and facility lifecycle management. However, utilizing cost-effective sparse imagery remains challenging due to limited robustness, inaccurate localization, and a lack of fine-grained state understanding. To address these limitations, SVII-3D, a unified framework for holistic asset digitization, is proposed. First, LoRA fine-tuned open-set detection is fused with a spatial-attention matching network to robustly associate observations across sparse views. Second, a geometry-guided refinement mechanism is introduced to resolve structural errors, achieving precise decimeter-level 3D localization. Third, transcending static geometric mapping, a Vision-Language Model agent leveraging multi-modal prompting is incorporated to automatically diagnose fine-grained operational states. Experiments demonstrate that SVII-3D significantly improves identification accuracy and minimizes localization errors. Consequently, this framework offers a scalable, cost-effective solution for high-fidelity infrastructure digitization, effectively bridging the gap between sparse perception and automated intelligent maintenance.
Automatic detection of aerial survey ground control points based on Yolov5-OBB
Mar 06, 2023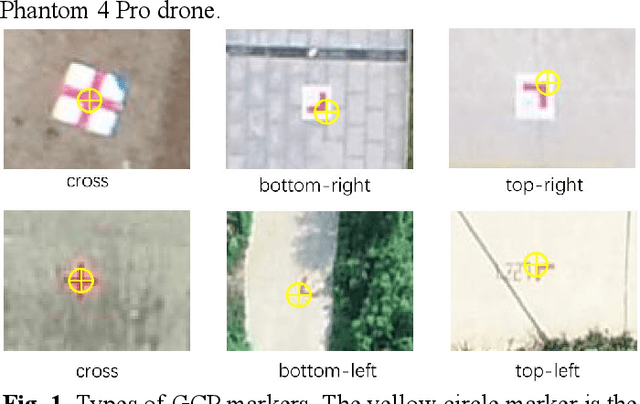

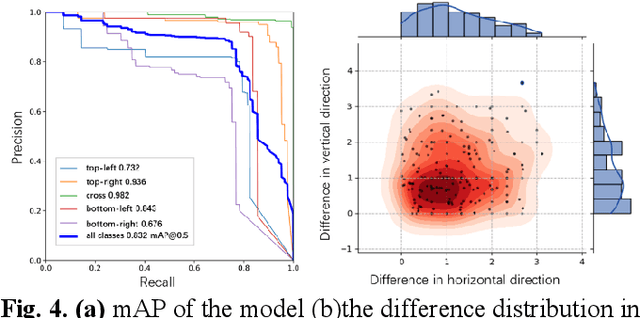
The use of ground control points (GCPs) for georeferencing is the most common strategy in unmanned aerial vehicle (UAV) photogrammetry, but at the same time their collection represents the most time-consuming and expensive part of UAV campaigns. Recently, deep learning has been rapidly developed in the field of small object detection. In this letter, to automatically extract coordinates information of ground control points (GCPs) by detecting GCP-markers in UAV images, we propose a solution that uses a deep learning-based architecture, YOLOv5-OBB, combined with a confidence threshold filtering algorithm and an optimal ranking algorithm. We applied our proposed method to a dataset collected by DJI Phantom 4 Pro drone and obtained good detection performance with the mean Average Precision (AP) of 0.832 and the highest AP of 0.982 for the cross-type GCP-markers. The proposed method can be a promising tool for future implementation of the end-to-end aerial triangulation process.
Video Smoke Detection Based on Deep Saliency Network
Sep 08, 2018



Video smoke detection is a promising fire detection method especially in open or large spaces and outdoor environments. Traditional smoke detection consists of candidate region extraction and classification, but it lacks powerful characterization for smoke. In this paper, we propose a novel method for video smoke detection based on deep saliency network. Visual saliency detection aims to highlight the most important object regions in an image. The pixel-level and object-level salient CNNs are combined to extract the informative smoke saliency map. For the need of application for smoke event detection, an end-to-end framework for salient smoke detection and existence prediction of smoke is proposed. The deep feature map is combined with the saliency map to predict the existence of smoke in image. Initial dataset and augmented dataset are built to measure the performance of frameworks with different design strategies. Qualitative and quantitative analysis at frame-level and pixel-level demonstrates the excellent performance of the ultimate framework.