 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to fuse: dynamic integration of multi-source data for accurate battery lifespan prediction
Apr 25, 2025Accurate prediction of lithium-ion battery lifespan is vital for ensuring operational reliability and reducing maintenance costs in applications like electric vehicles and smart grids. This study presents a hybrid learning framework for precise battery lifespan prediction, integrating dynamic multi-source data fusion with a stacked ensemble (SE) modeling approach. By leveraging heterogeneous datasets from the National Aeronautics and Space Administration (NASA), Center for Advanced Life Cycle Engineering (CALCE), MIT-Stanford-Toyota Research Institute (TRC), and nickel cobalt aluminum (NCA) chemistries, an entropy-based dynamic weighting mechanism mitigates variability across heterogeneous datasets. The SE model combines Ridge regression, long short-term memory (LSTM) networks, and eXtreme Gradient Boosting (XGBoost), effectively capturing temporal dependencies and nonlinear degradation patterns. It achieves a mean absolute error (MAE) of 0.0058, root mean square error (RMSE) of 0.0092, and coefficient of determination (R2) of 0.9839, outperforming established baseline models with a 46.2% improvement in R2 and an 83.2% reduction in RMSE. Shapley additive explanations (SHAP) analysis identifies differential discharge capacity (Qdlin) and temperature of measurement (Temp_m) as critical aging indicators. This scalable, interpretable framework enhances battery health management, supporting optimized maintenance and safety across diverse energy storage systems, thereby contributing to improved battery health management in energy storage systems.
An optimized Capsule-LSTM model for facial expression recognition with video sequences
May 27, 2021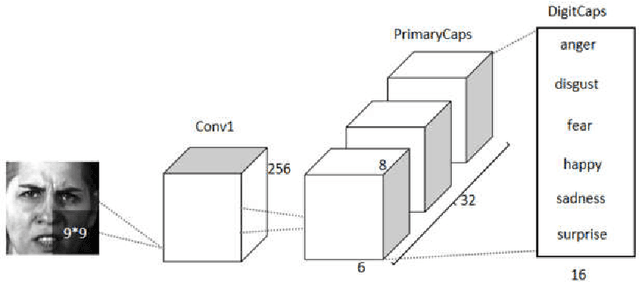
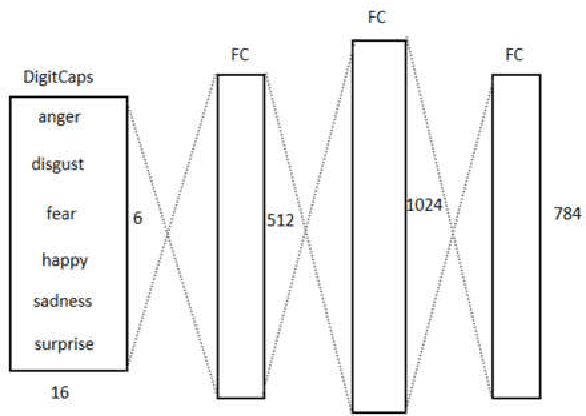
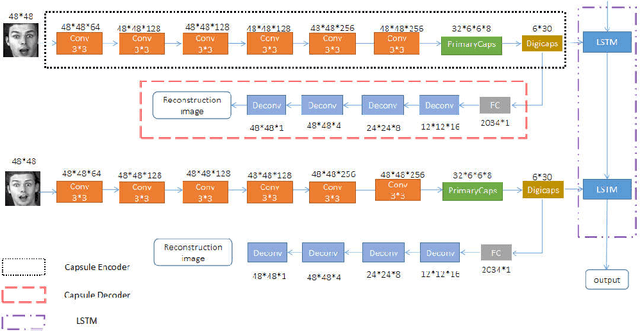

To overcome the limitations of convolutional neural network in the process of facial expression recognition, a facial expression recognition model Capsule-LSTM based on video frame sequence is proposed. This model is composed of three networks includingcapsule encoders, capsule decoders and LSTM network. The capsule encoder extracts the spatial information of facial expressions in video frames. Capsule decoder reconstructs the images to optimize the network. LSTM extracts the temporal information between video frames and analyzes the differences in expression changes between frames. The experimental results from the MMI dataset show that the Capsule-LSTM model proposed in this paper can effectively improve the accuracy of video expression recognition.
BPLF: A Bi-Parallel Linear Flow Model for Facial Expression Generation from Emotion Set Images
May 27, 2021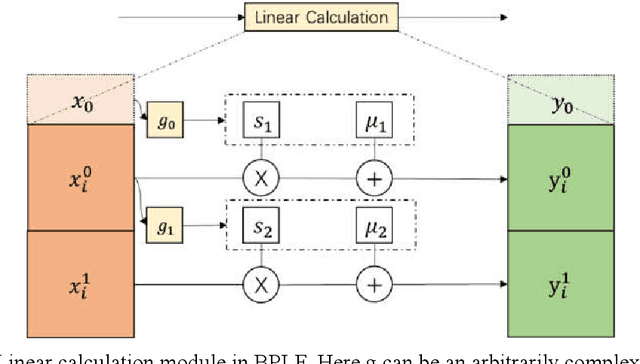

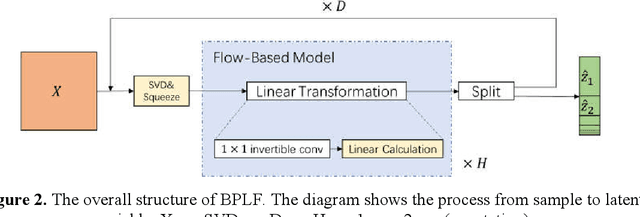
The flow-based generative model is a deep learning generative model, which obtains the ability to generate data by explicitly learning the data distribution. Theoretically its ability to restore data is stronger than other generative models. However, its implementation has many limitations, including limited model design, too many model parameters and tedious calculation. In this paper, a bi-parallel linear flow model for facial emotion generation from emotion set images is constructed, and a series of improvements have been made in terms of the expression ability of the model and the convergence speed in training. The model is mainly composed of several coupling layers superimposed to form a multi-scale structure, in which each coupling layer contains 1*1 reversible convolution and linear operation modules. Furthermore, this paper sorted out the current public data set of facial emotion images, made a new emotion data, and verified the model through this data set. The experimental results show that, under the traditional convolutional neural network, the 3-layer 3*3 convolution kernel is more conducive to extracte the features of the face images. The introduction of principal component decomposition can improve the convergence speed of the model.
Video Smoke Detection Based on Deep Saliency Network
Sep 08, 2018



Video smoke detection is a promising fire detection method especially in open or large spaces and outdoor environments. Traditional smoke detection consists of candidate region extraction and classification, but it lacks powerful characterization for smoke. In this paper, we propose a novel method for video smoke detection based on deep saliency network. Visual saliency detection aims to highlight the most important object regions in an image. The pixel-level and object-level salient CNNs are combined to extract the informative smoke saliency map. For the need of application for smoke event detection, an end-to-end framework for salient smoke detection and existence prediction of smoke is proposed. The deep feature map is combined with the saliency map to predict the existence of smoke in image. Initial dataset and augmented dataset are built to measure the performance of frameworks with different design strategies. Qualitative and quantitative analysis at frame-level and pixel-level demonstrates the excellent performance of the ultimate framework.
Domain Adaptation from Synthesis to Reality in Single-model Detector for Video Smoke Detection
May 18, 2018
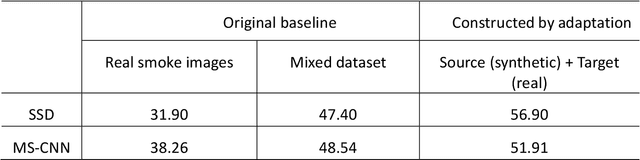
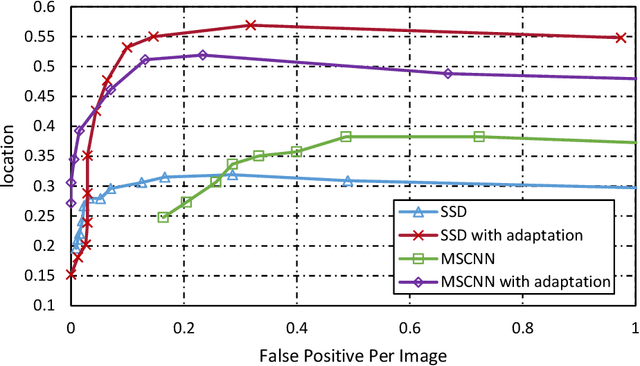
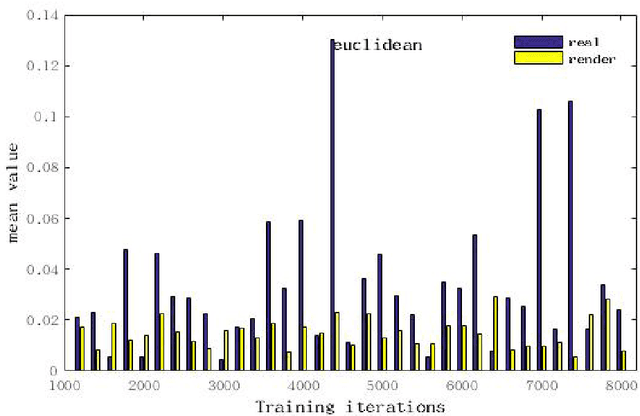
This paper proposes a method for video smoke detection using synthetic smoke samples. The virtual data can automatically offer precise and rich annotated samples. However, the learning of smoke representations will be hurt by the appearance gap between real and synthetic smoke samples. The existed researches mainly work on the adaptation to samples extracted from original annotated samples. These methods take the object detection and domain adaptation as two independent parts. To train a strong detector with rich synthetic samples, we construct the adaptation to the detection layer of state-of-the-art single-model detectors (SSD and MS-CNN). The training procedure is an end-to-end stage. The classification, location and adaptation are combined in the learning. The performance of the proposed model surpasses the original baseline in our experiments. Meanwhile, our results show that the detectors based on the adversarial adaptation are superior to the detectors based on the discrepancy adaptation. Code will be made publicly available on http://smoke.ustc.edu.cn. Moreover, the domain adaptation for two-stage detector is described in Appendix A.
Deep Domain Adaptation Based Video Smoke Detection using Synthetic Smoke Images
Mar 31, 2017
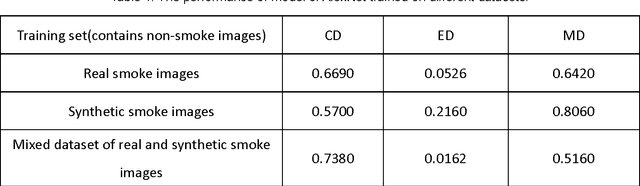

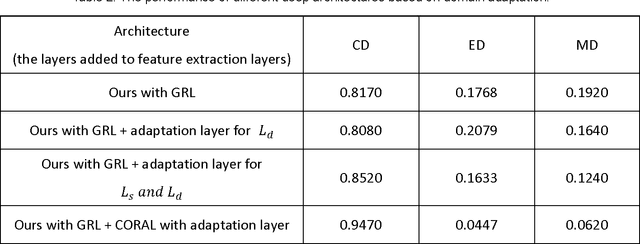
In this paper, a deep domain adaptation based method for video smoke detection is proposed to extract a powerful feature representation of smoke. Due to the smoke image samples limited in scale and diversity for deep CNN training, we systematically produced adequate synthetic smoke images with a wide variation in the smoke shape, background and lighting conditions. Considering that the appearance gap (dataset bias) between synthetic and real smoke images degrades significantly the performance of the trained model on the test set composed fully of real images, we build deep architectures based on domain adaptation to confuse the distributions of features extracted from synthetic and real smoke images. This approach expands the domain-invariant feature space for smoke image samples. With their approximate feature distribution off non-smoke images, the recognition rate of the trained model is improved significantly compared to the model trained directly on mixed dataset of synthetic and real images. Experimentally, several deep architectures with different design choices are applied to the smoke detector. The ultimate framework can get a satisfactory result on the test set. We believe that our approach is a start in the direction of utilizing deep neural networks enhanced with synthetic smoke images for video smoke detection.
* The manuscript approved by all authors is our original work, and has submitted to Fire Safety Journal for peer review previously. There are 4516 words, 8 figures and 2 tables in this manuscript