 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewrite the News: Tracing Editorial Reuse Across News Agencies
Mar 31, 2026This paper investigates sentence-level text reuse in multilingual journalism, analyzing where reused content occurs within articles. We present a weakly supervised method for detecting sentence-level cross-lingual reuse without requiring full translations, designed to support automated pre-selection to reduce information overload for journalists (Holyst et al., 2024). The study compares English-language articles from the Slovenian Press Agency (STA) with reports from 15 foreign agencies (FA) in seven languages, using publication timestamps to retain the earliest likely foreign source for each reused sentence. We analyze 1,037 STA and 237,551 FA articles from two time windows (October 7-November 2, 2023; February 1-28, 2025) and identify 1,087 aligned sentence pairs after filtering to the earliest sources. Reuse occurs in 52% of STA articles and 1.6% of FA articles and is predominantly non-literal, involving paraphrase and compositional reuse from multiple sources. Reused content tends to appear in the middle and end of English articles, while leads are more often original, indicating that simple lexical matching overlooks substantial editorial reuse. Compared with prior work focused on monolingual overlap, we (i) detect reuse across languages without requiring full translation, (ii) use publication timing to identify likely sources, and (iii) analyze where reused material is situated within articles. Dataset and code: https://github.com/kunturs/lrec2026-rewrite-news.
Analysing Calls to Order in German Parliamentary Debates
Mar 27, 2026Parliamentary debate constitutes a central arena of political power, shaping legislative outcomes and public discourse. Incivility within this arena signals political polarization and institutional conflict. This study presents a systematic investigation of incivility in the German Bundestag by examining calls to order (CtO; plural: CtOs) as formal indicators of norm violations. Despite their relevance, CtOs have received little systematic attention in parliamentary research. We introduce a rule-based method for detecting and annotating CtOs in parliamentary speeches and present a novel dataset of German parliamentary debates spanning 72 years that includes annotated CtO instances. Additionally, we develop the first classification system for CtO triggers and analyze the factors associated with their occurrence. Our findings show that, despite formal regulations, the issuance of CtOs is partly subjective and influenced by session presidents and parliamentary dynamics, with certain individuals disproportionately affected. An insult towards individuals is the most frequent cause of CtO. In general, male members and those belonging to opposition parties receive more calls to order than their female and coalition-party counterparts. Most CtO triggers were detected in speeches dedicated to governmental affairs and actions of the presidency. The CtO triggers dataset is available at: https://github.com/kalawinka/cto_analysis.
Annotating Scientific Uncertainty: A comprehensive model using linguistic patterns and comparison with existing approaches
Mar 14, 2025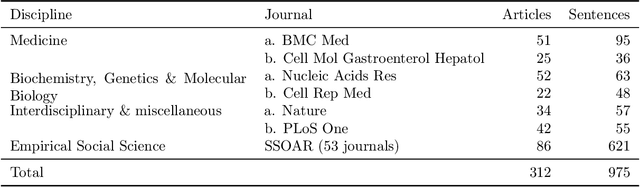

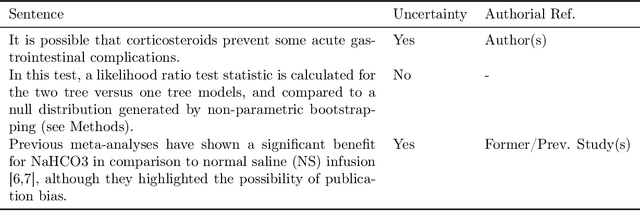
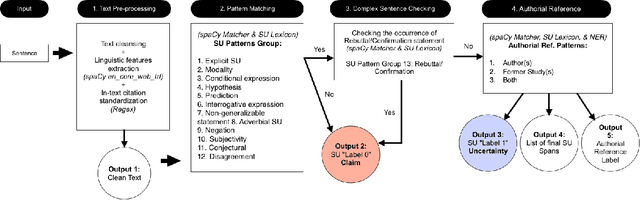
UnScientify, a system designed to detect scientific uncertainty in scholarly full text. The system utilizes a weakly supervised technique to identify verbally expressed uncertainty in scientific texts and their authorial references. The core methodology of UnScientify is based on a multi-faceted pipeline that integrates span pattern matching, complex sentence analysis and author reference checking. This approach streamlines the labeling and annotation processes essential for identifying scientific uncertainty, covering a variety of uncertainty expression types to support diverse applications including information retrieval, text mining and scientific document processing. The evaluation results highlight the trade-offs between modern large language models (LLMs) and the UnScientify system. UnScientify, which employs more traditional techniques, achieved superior performance in the scientific uncertainty detection task, attaining an accuracy score of 0.808. This finding underscores the continued relevance and efficiency of UnScientify's simple rule-based and pattern matching strategy for this specific application. The results demonstrate that in scenarios where resource efficiency, interpretability, and domain-specific adaptability are critical, traditional methods can still offer significant advantages.
Utilizing Large Language Models for Named Entity Recognition in Traditional Chinese Medicine against COVID-19 Literature: Comparative Study
Aug 24, 2024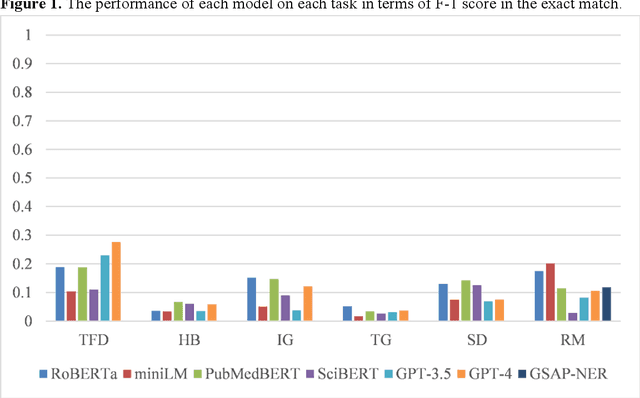
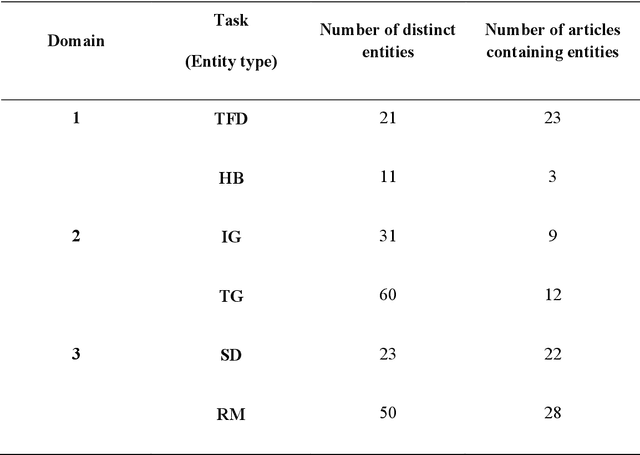
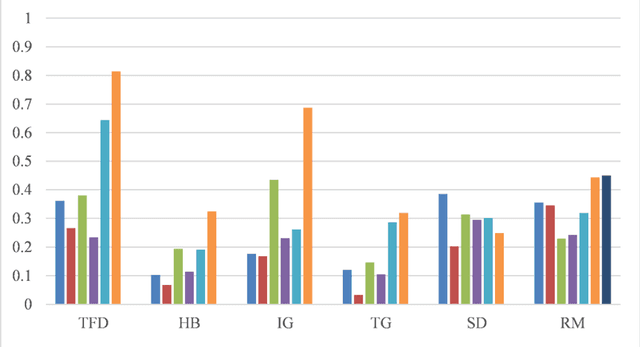
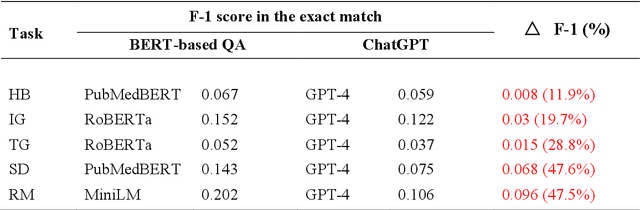
Objective: To explore and compare the performance of ChatGPT and other state-of-the-art LLMs on domain-specific NER tasks covering different entity types and domains in TCM against COVID-19 literature. Methods: We established a dataset of 389 articles on TCM against COVID-19, and manually annotated 48 of them with 6 types of entities belonging to 3 domains as the ground truth, against which the NER performance of LLMs can be assessed. We then performed NER tasks for the 6 entity types using ChatGPT (GPT-3.5 and GPT-4) and 4 state-of-the-art BERT-based question-answering (QA) models (RoBERTa, MiniLM, PubMedBERT and SciBERT) without prior training on the specific task. A domain fine-tuned model (GSAP-NER) was also applied for a comprehensive comparison. Results: The overall performance of LLMs varied significantly in exact match and fuzzy match. In the fuzzy match, ChatGPT surpassed BERT-based QA models in 5 out of 6 tasks, while in exact match, BERT-based QA models outperformed ChatGPT in 5 out of 6 tasks but with a smaller F-1 difference. GPT-4 showed a significant advantage over other models in fuzzy match, especially on the entity type of TCM formula and the Chinese patent drug (TFD) and ingredient (IG). Although GPT-4 outperformed BERT-based models on entity type of herb, target, and research method, none of the F-1 scores exceeded 0.5. GSAP-NER, outperformed GPT-4 in terms of F-1 by a slight margin on RM. ChatGPT achieved considerably higher recalls than precisions, particularly in the fuzzy match. Conclusions: The NER performance of LLMs is highly dependent on the entity type, and their performance varies across application scenarios. ChatGPT could be a good choice for scenarios where high recall is favored. However, for knowledge acquisition in rigorous scenarios, neither ChatGPT nor BERT-based QA models are off-the-shelf tools for professional practitioners.
Embedding Models for Supervised Automatic Extraction and Classification of Named Entities in Scientific Acknowledgements
Jul 25, 2023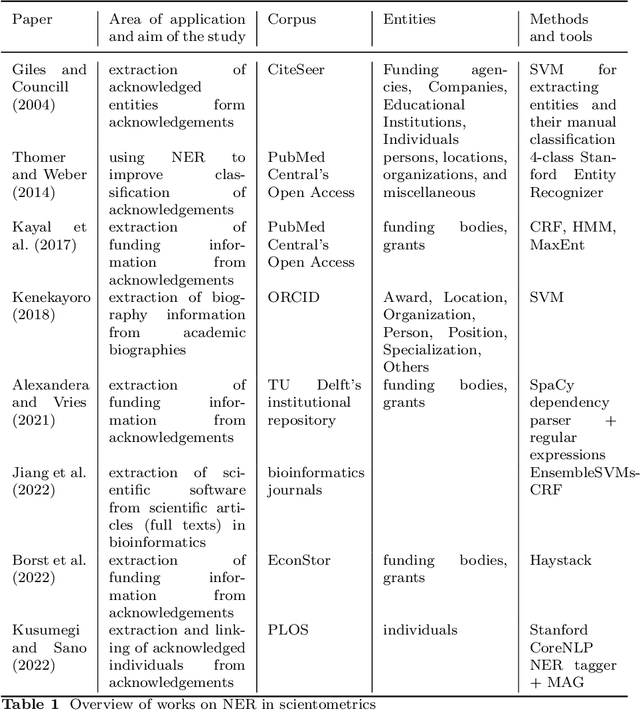


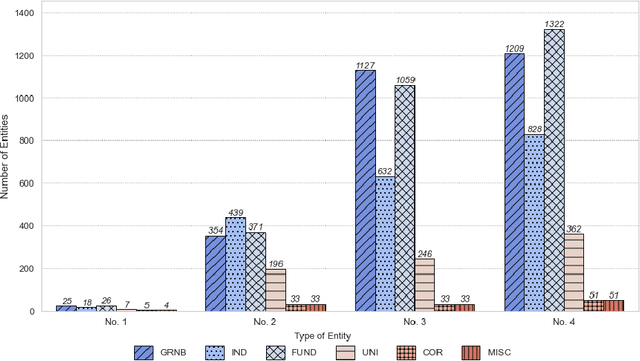
Acknowledgments in scientific papers may give an insight into aspects of the scientific community, such as reward systems, collaboration patterns, and hidden research trends. The aim of the paper is to evaluate the performance of different embedding models for the task of automatic extraction and classification of acknowledged entities from the acknowledgment text in scientific papers. We trained and implemented a named entity recognition (NER) task using the Flair NLP framework. The training was conducted using three default Flair NER models with four differently-sized corpora and different versions of the Flair NLP framework. The Flair Embeddings model trained on the medium corpus with the latest FLAIR version showed the best accuracy of 0.79. Expanding the size of a training corpus from very small to medium size massively increased the accuracy of all training algorithms, but further expansion of the training corpus did not bring further improvement. Moreover, the performance of the model slightly deteriorated. Our model is able to recognize six entity types: funding agency, grant number, individuals, university, corporation, and miscellaneous. The model works more precisely for some entity types than for others; thus, individuals and grant numbers showed a very good F1-Score over 0.9. Most of the previous works on acknowledgment analysis were limited by the manual evaluation of data and therefore by the amount of processed data. This model can be applied for the comprehensive analysis of acknowledgment texts and may potentially make a great contribution to the field of automated acknowledgment analysis.
A Comprehensive Analysis of Acknowledgement Texts in Web of Science: a case study on four scientific domains
Oct 18, 2022
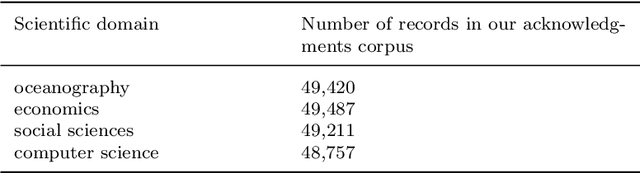

Analysis of acknowledgments is particularly interesting as acknowledgments may give information not only about funding, but they are also able to reveal hidden contributions to authorship and the researcher's collaboration patterns, context in which research was conducted, and specific aspects of the academic work. The focus of the present research is the analysis of a large sample of acknowledgement texts indexed in the Web of Science (WoS) Core Collection. Record types 'article' and 'review' from four different scientific domains, namely social sciences, economics, oceanography and computer science, published from 2014 to 2019 in a scientific journal in English were considered. Six types of acknowledged entities, i.e., funding agency, grant number, individuals, university, corporation and miscellaneous, were extracted from the acknowledgement texts using a Named Entity Recognition (NER) tagger and subsequently examined. A general analysis of the acknowledgement texts showed that indexing of funding information in WoS is incomplete. The analysis of the automatically extracted entities revealed differences and distinct patterns in the distribution of acknowledged entities of different types between different scientific domains. A strong association was found between acknowledged entity and scientific domain and acknowledged entity and entity type. Only negligible correlation was found between the number of citations and the number of acknowledged entities. Generally, the number of words in the acknowledgement texts positively correlates with the number of acknowledged funding organizations, universities, individuals and miscellaneous entities. At the same time, acknowledgement texts with the larger number of sentences have more acknowledged individuals and miscellaneous categories.
Evaluation of Embedding Models for Automatic Extraction and Classification of Acknowledged Entities in Scientific Documents
Jun 22, 2022
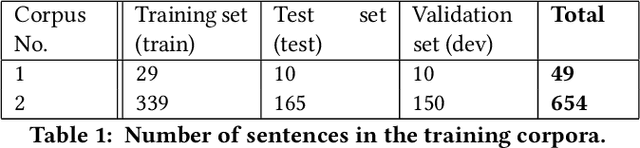
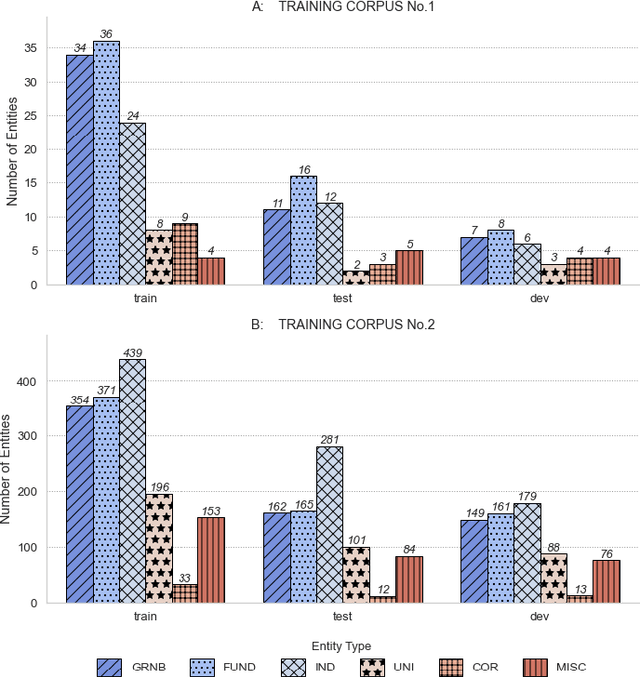
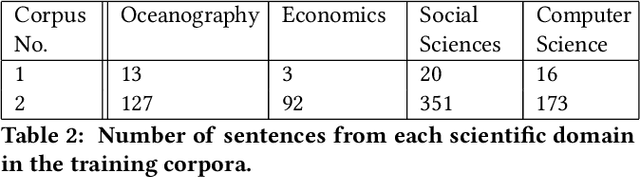
Acknowledgments in scientific papers may give an insight into aspects of the scientific community, such as reward systems, collaboration patterns, and hidden research trends. The aim of the paper is to evaluate the performance of different embedding models for the task of automatic extraction and classification of acknowledged entities from the acknowledgment text in scientific papers. We trained and implemented a named entity recognition (NER) task using the Flair NLP-framework. The training was conducted using three default Flair NER models with two differently-sized corpora. The Flair Embeddings model trained on the larger training corpus showed the best accuracy of 0.77. Our model is able to recognize six entity types: funding agency, grant number, individuals, university, corporation and miscellaneous. The model works more precise for some entity types than the others, thus, individuals and grant numbers showed very good F1-Score over 0.9. Most of the previous works on acknowledgement analysis were limited by the manual evaluation of data and therefore by the amount of processed data. This model can be applied for the comprehensive analysis of the acknowledgement texts and may potentially make a great contribution to the field of automated acknowledgement analysis.