 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-SCITLDR: Cross-Lingual Extreme Summarization of Scholarly Documents
Paper and Code
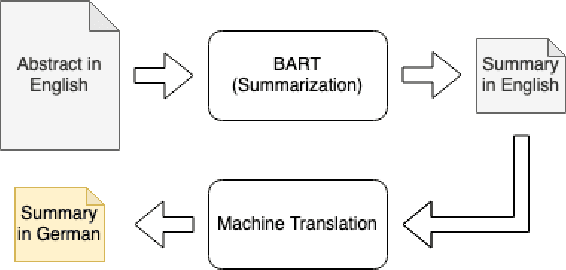

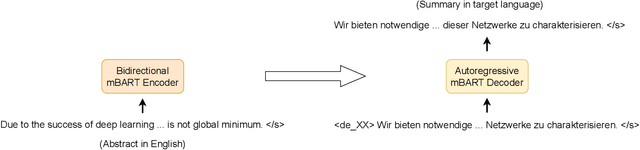

The number of scientific publications nowadays is rapidly increasing, causing information overload for researchers and making it hard for scholars to keep up to date with current trends and lines of work. Consequently, recent work on applying text mining technologies for scholarly publications has investigated the application of automatic text summarization technologies, including extreme summarization, for this domain. However, previous work has concentrated only on monolingual settings, primarily in English. In this paper, we fill this research gap and present an abstractive cross-lingual summarization dataset for four different languages in the scholarly domain, which enables us to train and evaluate models that process English papers and generate summaries in German, Italian, Chinese and Japanese. We present our new X-SCITLDR dataset for multilingual summarization and thoroughly benchmark different models based on a state-of-the-art multilingual pre-trained model, including a two-stage `summarize and translate' approach and a direct cross-lingual model. We additionally explore the benefits of intermediate-stage training using English monolingual summarization and machine translation as intermediate tasks and analyze performance in zero- and few-shot scenarios.