 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAY Diffusion: Styled Layout Diffusion Model for Diverse Layout-to-Image Generation
Paper and Code
Mar 15, 2025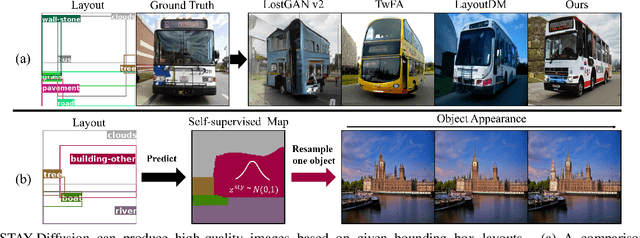
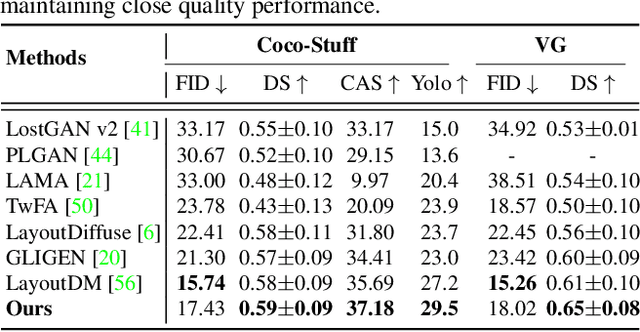
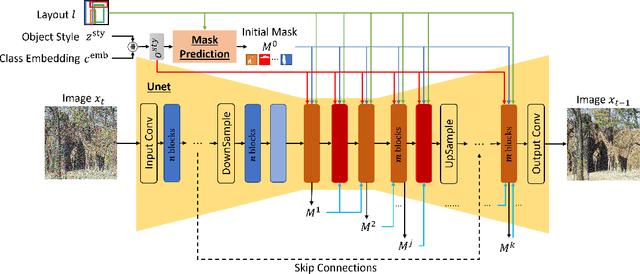
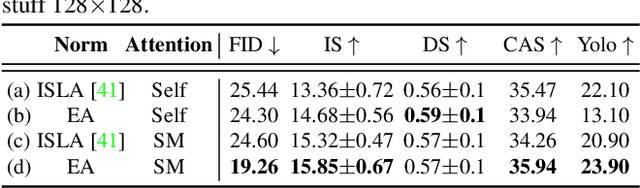
In layout-to-image (L2I) synthesis, controlled complex scenes are generated from coarse information like bounding boxes. Such a task is exciting to many downstream applications because the input layouts offer strong guidance to the generation process while remaining easily reconfigurable by humans. In this paper, we proposed STyled LAYout Diffusion (STAY Diffusion), a diffusion-based model that produces photo-realistic images and provides fine-grained control of stylized objects in scenes. Our approach learns a global condition for each layout, and a self-supervised semantic map for weight modulation using a novel Edge-Aware Normalization (EA Norm). A new Styled-Mask Attention (SM Attention) is also introduced to cross-condition the global condition and image feature for capturing the objects' relationships. These measures provide consistent guidance through the model, enabling more accurate and controllable image generation. Extensive benchmarking demonstrates that our STAY Diffusion presents high-quality images while surpassing previous state-of-the-art methods in generation diversity, accuracy, and controllability.