 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesynth-dacl: Does Synthetic Defect Data Enhance Segmentation Accuracy and Robustness for Real-World Bridge Inspections?
Jun 17, 2025Adequate bridge inspection is increasingly challenging in many countries due to growing ailing stocks, compounded with a lack of staff and financial resources. Automating the key task of visual bridge inspection, classification of defects and building components on pixel level, improves efficiency, increases accuracy and enhances safety in the inspection process and resulting building assessment. Models overtaking this task must cope with an assortment of real-world conditions. They must be robust to variations in image quality, as well as background texture, as defects often appear on surfaces of diverse texture and degree of weathering. dacl10k is the largest and most diverse dataset for real-world concrete bridge inspections. However, the dataset exhibits class imbalance, which leads to notably poor model performance particularly when segmenting fine-grained classes such as cracks and cavities. This work introduces "synth-dacl", a compilation of three novel dataset extensions based on synthetic concrete textures. These extensions are designed to balance class distribution in dacl10k and enhance model performance, especially for crack and cavity segmentation. When incorporating the synth-dacl extensions, we observe substantial improvements in model robustness across 15 perturbed test sets. Notably, on the perturbed test set, a model trained on dacl10k combined with all synthetic extensions achieves a 2% increase in mean IoU, F1 score, Recall, and Precision compared to the same model trained solely on dacl10k.
Cycle-Correspondence Loss: Learning Dense View-Invariant Visual Features from Unlabeled and Unordered RGB Images
Jun 18, 2024



Robot manipulation relying on learned object-centric descriptors became popular in recent years. Visual descriptors can easily describe manipulation task objectives, they can be learned efficiently using self-supervision, and they can encode actuated and even non-rigid objects. However, learning robust, view-invariant keypoints in a self-supervised approach requires a meticulous data collection approach involving precise calibration and expert supervision. In this paper we introduce Cycle-Correspondence Loss (CCL) for view-invariant dense descriptor learning, which adopts the concept of cycle-consistency, enabling a simple data collection pipeline and training on unpaired RGB camera views. The key idea is to autonomously detect valid pixel correspondences by attempting to use a prediction over a new image to predict the original pixel in the original image, while scaling error terms based on the estimated confidence. Our evaluation shows that we outperform other self-supervised RGB-only methods, and approach performance of supervised methods, both with respect to keypoint tracking as well as for a robot grasping downstream task.
Learning Dense Visual Descriptors using Image Augmentations for Robot Manipulation Tasks
Sep 12, 2022

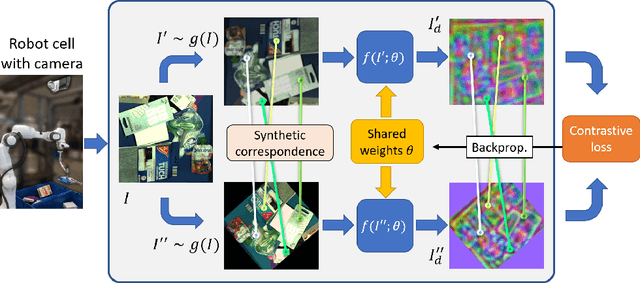

We propose a self-supervised training approach for learning view-invariant dense visual descriptors using image augmentations. Unlike existing works, which often require complex datasets, such as registered RGBD sequences, we train on an unordered set of RGB images. This allows for learning from a single camera view, e.g., in an existing robotic cell with a fix-mounted camera. We create synthetic views and dense pixel correspondences using data augmentations. We find our descriptors are competitive to the existing methods, despite the simpler data recording and setup requirements. We show that training on synthetic correspondences provides descriptor consistency across a broad range of camera views. We compare against training with geometric correspondence from multiple views and provide ablation studies. We also show a robotic bin-picking experiment using descriptors learned from a fix-mounted camera for defining grasp preferences.
Benchmarking Visual-Inertial Deep Multimodal Fusion for Relative Pose Regression and Odometry-aided Absolute Pose Regression
Aug 01, 2022
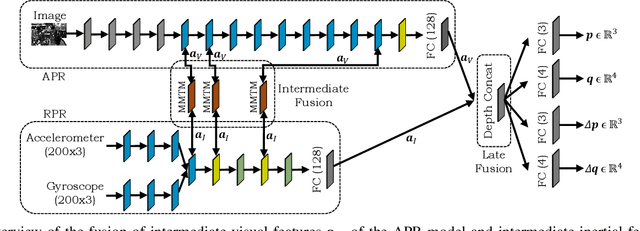
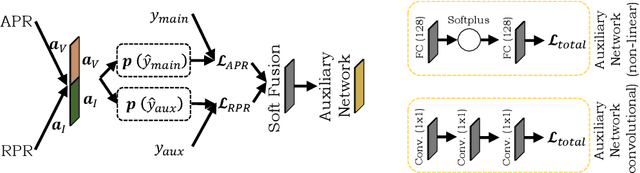

Visual-inertial localization is a key problem in computer vision and robotics applications such as virtual reality, self-driving cars, and aerial vehicles. The goal is to estimate an accurate pose of an object when either the environment or the dynamics are known. Recent methods directly regress the pose using convolutional and spatio-temporal networks. Absolute pose regression (APR) techniques predict the absolute camera pose from an image input in a known scene. Odometry methods perform relative pose regression (RPR) that predicts the relative pose from a known object dynamic (visual or inertial inputs). The localization task can be improved by retrieving information of both data sources for a cross-modal setup, which is a challenging problem due to contradictory tasks. In this work, we conduct a benchmark to evaluate deep multimodal fusion based on PGO and attention networks. Auxiliary and Bayesian learning are integrated for the APR task. We show accuracy improvements for the RPR-aided APR task and for the RPR-RPR task for aerial vehicles and hand-held devices. We conduct experiments on the EuRoC MAV and PennCOSYVIO datasets, and record a novel industry dataset.
Efficient and Robust Training of Dense Object Nets for Multi-Object Robot Manipulation
Jun 24, 2022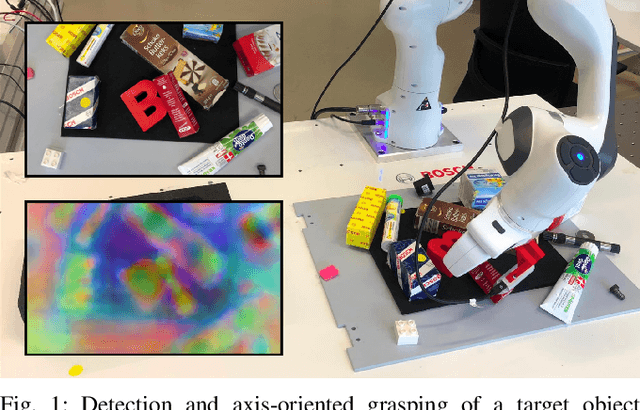

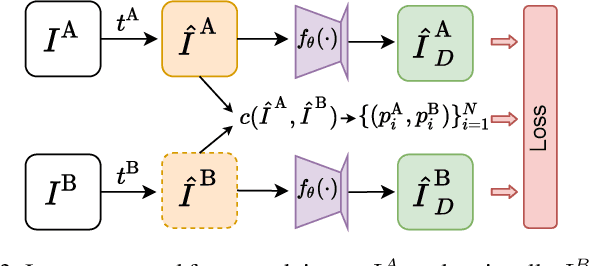
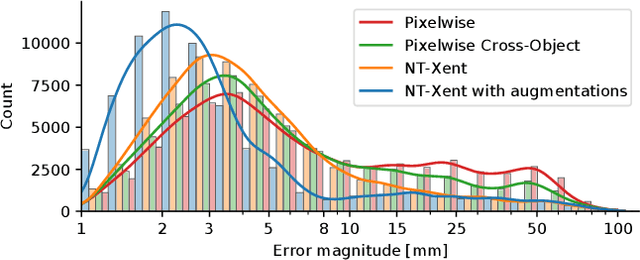
We propose a framework for robust and efficient training of Dense Object Nets (DON) with a focus on multi-object robot manipulation scenarios. DON is a popular approach to obtain dense, view-invariant object descriptors, which can be used for a multitude of downstream tasks in robot manipulation, such as, pose estimation, state representation for control, etc.. However, the original work focused training on singulated objects, with limited results on instance-specific, multi-object applications. Additionally, a complex data collection pipeline, including 3D reconstruction and mask annotation of each object, is required for training. In this paper, we further improve the efficacy of DON with a simplified data collection and training regime, that consistently yields higher precision and enables robust tracking of keypoints with less data requirements. In particular, we focus on training with multi-object data instead of singulated objects, combined with a well-chosen augmentation scheme. We additionally propose an alternative loss formulation to the original pixelwise formulation that offers better results and is less sensitive to hyperparameters. Finally, we demonstrate the robustness and accuracy of our proposed framework on a real-world robotic grasping task.
Generating 3D People in Scenes without People
Dec 12, 2019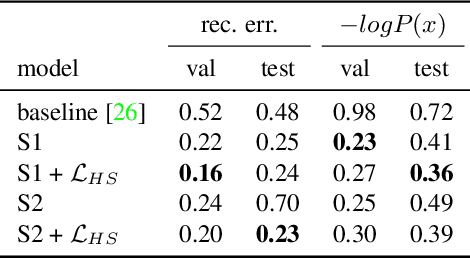
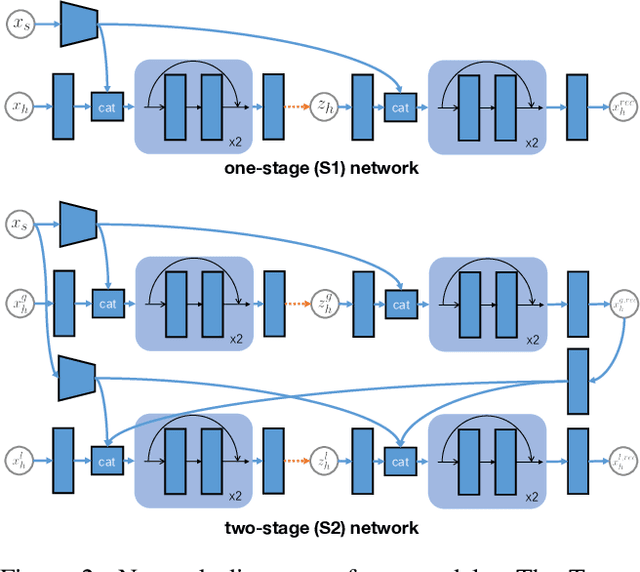

We present a fully-automatic system that takes a 3D scene and generates plausible 3D human bodies that are posed naturally in that 3D scene. Given a 3D scene without people, humans can easily imagine how people could interact with the scene and the objects in it. However, this is a challenging task for a computer as solving it requires (1) the generated human bodies should be semantically plausible with the 3D environment, e.g. people sitting on the sofa or cooking near the stove; (2) the generated human-scene interaction should be physically feasible in the way that the human body and scene do not interpenetrate while, at the same time, body-scene contact supports physical interactions. To that end, we make use of the surface-based 3D human model SMPL-X. We first train a conditional variational autoencoder to predict semantically plausible 3D human pose conditioned on latent scene representations, then we further refine the generated 3D bodies using scene constraints to enforce feasible physical interaction. We show that our approach is able to synthesize realistic and expressive 3D human bodies that naturally interact with 3D environment. We perform extensive experiments demonstrating that our generative framework compares favorably with existing methods, both qualitatively and quantitatively. We believe that our scene-conditioned 3D human generation pipeline will be useful for numerous applications; e.g. to generate training data for human pose estimation, in video games and in VR/AR.
Low-rank Random Tensor for Bilinear Pooling
Jun 03, 2019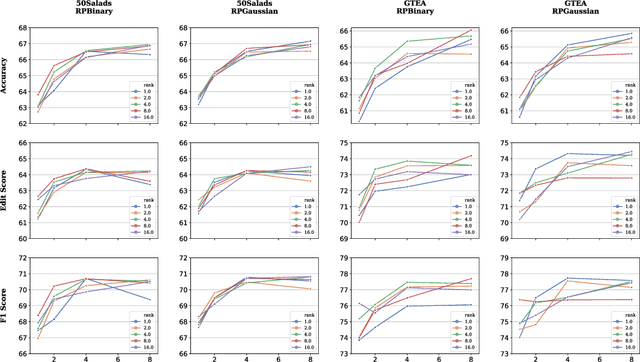

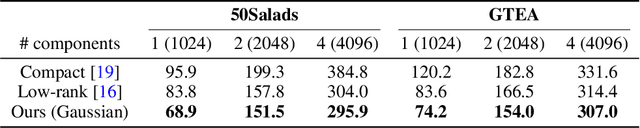
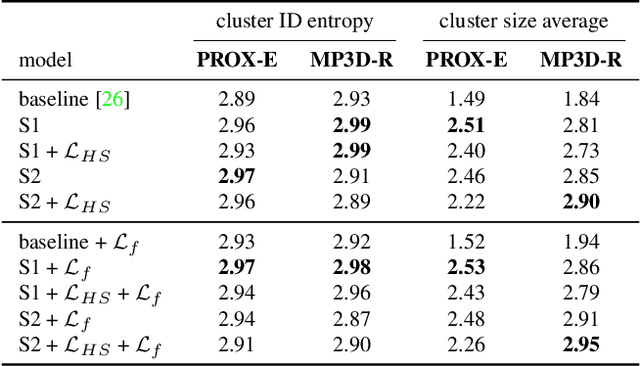
Bilinear pooling is capable of extracting high-order information from data, which makes it suitable for fine-grained visual understanding and information fusion. Despite their effectiveness in various applications, bilinear models with massive number of parameters can easily suffer from curse of dimensionality and intractable computation. In this paper, we propose a novel bilinear model based on low-rank random tensors. The key idea is to effectively combine low-rank tensor decomposition and random projection to reduce the number of parameters while preserving the model representativeness. From the theoretical perspective, we prove that our bilinear model with random tensors can estimate feature maps to reproducing kernel Hilbert spaces (RKHSs) with compositional kernels, grounding the high-dimensional feature fusion with theoretical foundations. From the application perspective, our low-rank tensor operation is lightweight, and can be integrated into standard neural network architectures to enable high-order information fusion. We perform extensive experiments to show that the use of our model leads to state-of-the-art performance on several challenging fine-grained action parsing benchmarks.
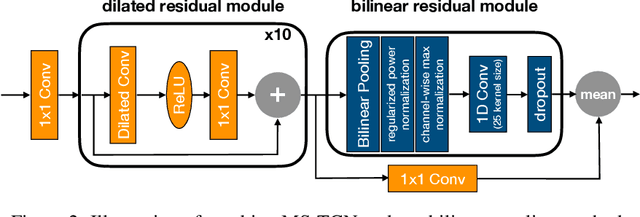
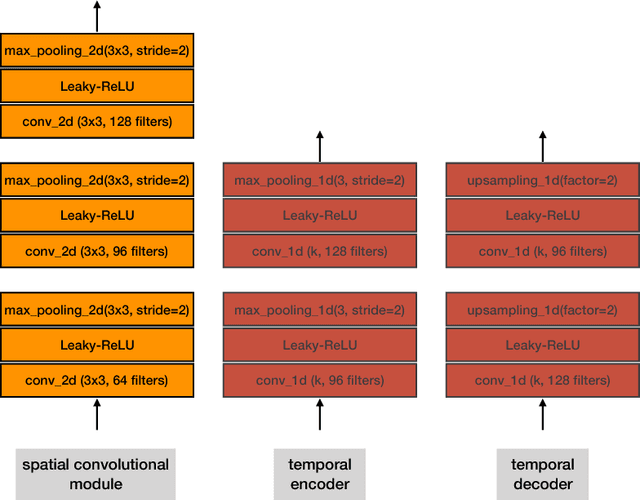
Local Temporal Bilinear Pooling for Fine-grained Action Parsing
Jan 10, 2019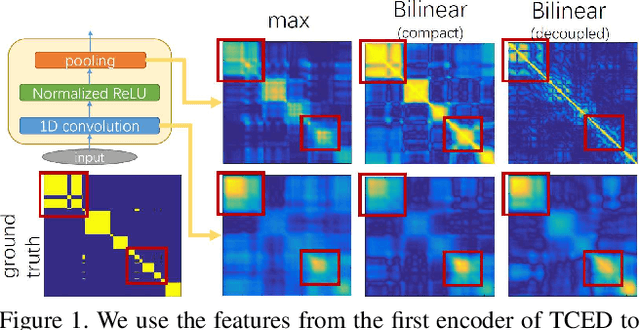
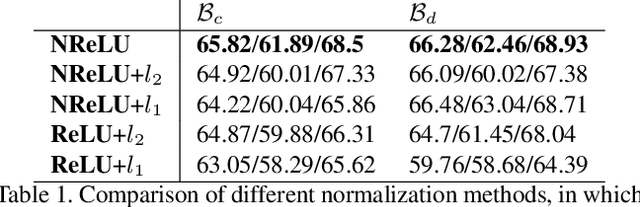
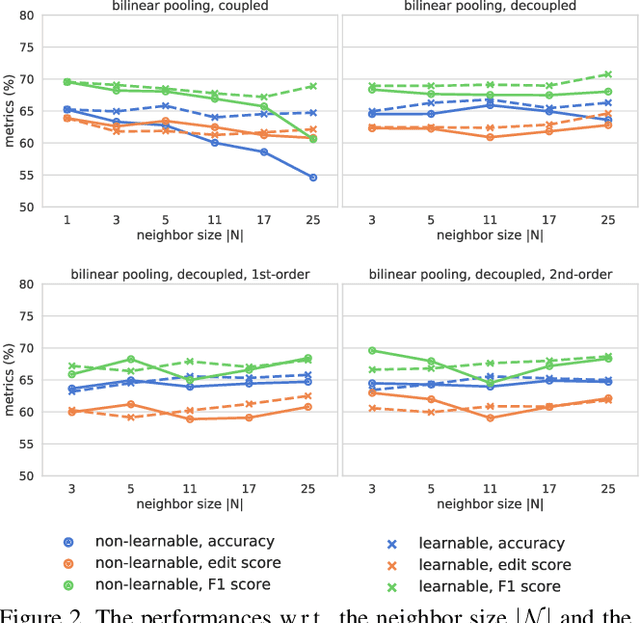

Fine-grained temporal action parsing is important in many applications, such as daily activity understanding, human motion analysis, surgical robotics and others requiring subtle and precise operations in a long-term period. In this paper we propose a novel bilinear pooling operation, which is used in intermediate layers of a temporal convolutional encoder-decoder net. In contrast to other work, our proposed bilinear pooling is learnable and hence can capture more complex local statistics than the conventional counterpart. In addition, we introduce exact lower-dimension representations of our bilinear forms, so that the dimensionality is reduced with neither information loss nor extra computation. We perform intensive experiments to quantitatively analyze our model and show the superior performances to other state-of-the-art work on various datasets.
An Empirical Study towards Understanding How Deep Convolutional Nets Recognize Falls
Dec 05, 2018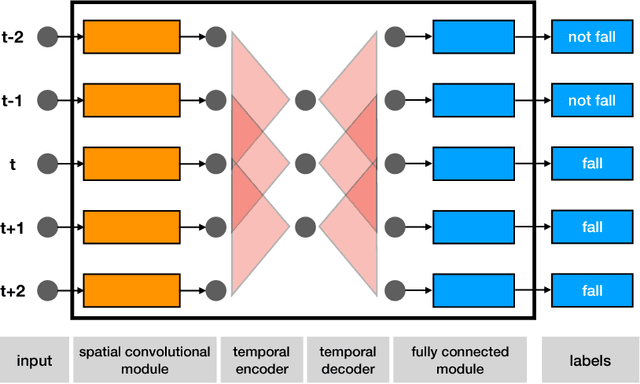


Detecting unintended falls is essential for ambient intelligence and healthcare of elderly people living alone. In recent years, deep convolutional nets are widely used in human action analysis, based on which a number of fall detection methods have been proposed. Despite their highly effective performances, the behaviors of how the convolutional nets recognize falls are still not clear. In this paper, instead of proposing a novel approach, we perform a systematical empirical study, attempting to investigate the underlying fall recognition process. We propose four tasks to investigate, which involve five types of input modalities, seven net instances and different training samples. The obtained quantitative and qualitative results reveal the patterns that the nets tend to learn, and several factors that can heavily influence the performances on fall recognition. We expect that our conclusions are favorable to proposing better deep learning solutions to fall detection systems.
Training De-Confusion: An Interactive, Network-Supported Visual Analysis System for Resolving Errors in Image Classification Training Data
Aug 09, 2018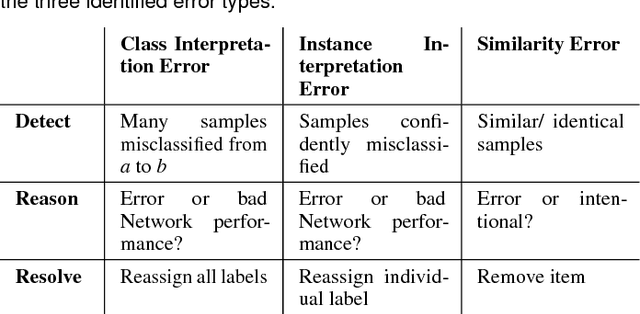



Convolutional neural networks gain more and more popularity in image classification tasks since they are often even able to outperform human classifiers. While much research has been targeted towards network architecture optimization, the optimization of the labeled training data has not been explicitly targeted yet. Since labeling of training data is time-consuming, it is often performed by less experienced domain experts or even outsourced to online services. Unfortunately, this results in labeling errors, which directly impact the classification performance of the trained network. To overcome this problem, we propose an interactive visual analysis system that helps to spot and correct errors in the training dataset. For this purpose, we have identified instance interpretation errors, class interpretation errors and similarity errors as frequently occurring errors, which shall be resolved to improve classification performance. After we detect these errors, users are guided towards them through a two-step visual analysis process, in which they can directly reassign labels to resolve the detected errors. Thus, with the proposed visual analysis system, the user has to inspect far fewer items to resolve labeling errors in the training dataset, and thus arrives at satisfying training results more quickly.