 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming the Randomness: Towards Label-Preserving Cropping in Contrastive Learning
Apr 28, 2025



Contrastive learning (CL) approaches have gained great recognition as a very successful subset of self-supervised learning (SSL) methods. SSL enables learning from unlabeled data, a crucial step in the advancement of deep learning, particularly in computer vision (CV), given the plethora of unlabeled image data. CL works by comparing different random augmentations (e.g., different crops) of the same image, thus achieving self-labeling. Nevertheless, randomly augmenting images and especially random cropping can result in an image that is semantically very distant from the original and therefore leads to false labeling, hence undermining the efficacy of the methods. In this research, two novel parameterized cropping methods are introduced that increase the robustness of self-labeling and consequently increase the efficacy. The results show that the use of these methods significantly improves the accuracy of the model by between 2.7\% and 12.4\% on the downstream task of classifying CIFAR-10, depending on the crop size compared to that of the non-parameterized random cropping method.
GCSAM: Gradient Centralized Sharpness Aware Minimization
Jan 20, 2025The generalization performance of deep neural networks (DNNs) is a critical factor in achieving robust model behavior on unseen data. Recent studies have highlighted the importance of sharpness-based measures in promoting generalization by encouraging convergence to flatter minima. Among these approaches, Sharpness-Aware Minimization (SAM) has emerged as an effective optimization technique for reducing the sharpness of the loss landscape, thereby improving generalization. However, SAM's computational overhead and sensitivity to noisy gradients limit its scalability and efficiency. To address these challenges, we propose Gradient-Centralized Sharpness-Aware Minimization (GCSAM), which incorporates Gradient Centralization (GC) to stabilize gradients and accelerate convergence. GCSAM normalizes gradients before the ascent step, reducing noise and variance, and improving stability during training. Our evaluations indicate that GCSAM consistently outperforms SAM and the Adam optimizer in terms of generalization and computational efficiency. These findings demonstrate GCSAM's effectiveness across diverse domains, including general and medical imaging tasks.
Process-Supervised Reward Models for Clinical Note Generation: A Scalable Approach Guided by Domain Expertise
Dec 17, 2024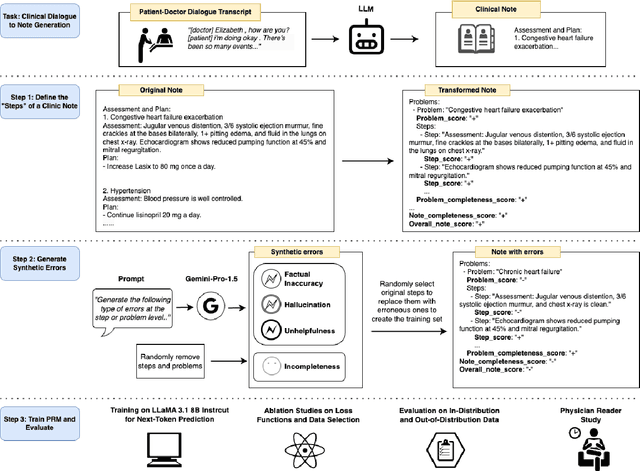
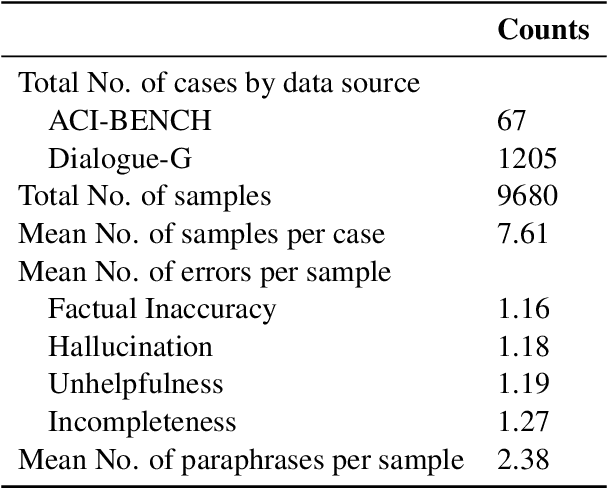

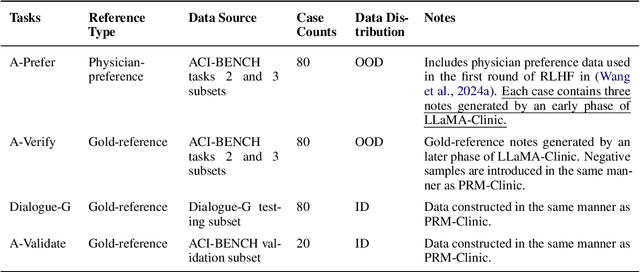
Process-supervised reward models (PRMs), which verify large language model (LLM) outputs step-by-step, have achieved significant success in mathematical and coding problems. However, their application to other domains remains largely unexplored. In this work, we train a PRM to provide step-level reward signals for clinical notes generated by LLMs from patient-doctor dialogues. Guided by real-world clinician expertise, we carefully designed step definitions for clinical notes and utilized Gemini-Pro 1.5 to automatically generate process supervision data at scale. Our proposed PRM, trained on the LLaMA-3.1 8B instruct model, demonstrated superior performance compared to Gemini-Pro 1.5 and an outcome-supervised reward model (ORM) across two key evaluations: (1) the accuracy of selecting gold-reference samples from error-containing samples, achieving 98.8% (versus 61.3% for ORM and 93.8% for Gemini-Pro 1.5), and (2) the accuracy of selecting physician-preferred notes, achieving 56.2% (compared to 51.2% for ORM and 50.0% for Gemini-Pro 1.5). Additionally, we conducted ablation studies to determine optimal loss functions and data selection strategies, along with physician reader studies to explore predictors of downstream Best-of-N performance. Our promising results suggest the potential of PRMs to extend beyond the clinical domain, offering a scalable and effective solution for diverse generative tasks.
Do Sharpness-based Optimizers Improve Generalization in Medical Image Analysis?
Aug 07, 2024Effective clinical deployment of deep learning models in healthcare demands high generalization performance to ensure accurate diagnosis and treatment planning. In recent years, significant research has focused on improving the generalization of deep learning models by regularizing the sharpness of the loss landscape. Among the optimization approaches that explicitly minimize sharpness, Sharpness-Aware Minimization (SAM) has shown potential in enhancing generalization performance on general domain image datasets. This success has led to the development of several advanced sharpness-based algorithms aimed at addressing the limitations of SAM, such as Adaptive SAM, surrogate-Gap SAM, Weighted SAM, and Curvature Regularized SAM. These sharpness-based optimizers have shown improvements in model generalization compared to conventional stochastic gradient descent optimizers and their variants on general domain image datasets, but they have not been thoroughly evaluated on medical images. This work provides a review of recent sharpness-based methods for improving the generalization of deep learning networks and evaluates the methods performance on medical breast ultrasound images. Our findings indicate that the initial SAM method successfully enhances the generalization of various deep learning models. While Adaptive SAM improves generalization of convolutional neural networks, it fails to do so for vision transformers. Other sharpness-based optimizers, however, do not demonstrate consistent results. The results reveal that, contrary to findings in the non-medical domain, SAM is the only recommended sharpness-based optimizer that consistently improves generalization in medical image analysis, and further research is necessary to refine the variants of SAM to enhance generalization performance in this field
Brain tumor multi classification and segmentation in MRO images using deep learning
Apr 20, 2023

This study proposes a deep learning model for the classification and segmentation of brain tumors from magnetic resonance imaging (MRI) scans. The classification model is based on the EfficientNetB1 architecture and is trained to classify images into four classes: meningioma, glioma, pituitary adenoma, and no tumor. The segmentation model is based on the U-Net architecture and is trained to accurately segment the tumor from the MRI images. The models are evaluated on a publicly available dataset and achieve high accuracy and segmentation metrics, indicating their potential for clinical use in the diagnosis and treatment of brain tumors.
Brain Tumor classification and Segmentation using Deep Learning
Apr 16, 2023
Brain tumors are a complex and potentially life-threatening medical condition that requires accurate diagnosis and timely treatment. In this paper, we present a machine learning-based system designed to assist healthcare professionals in the classification and diagnosis of brain tumors using MRI images. Our system provides a secure login, where doctors can upload or take a photo of MRI and our app can classify the model and segment the tumor, providing the doctor with a folder of each patient's history, name, and results. Our system can also add results or MRI to this folder, draw on the MRI to send it to another doctor, and save important results in a saved page in the app. Furthermore, our system can classify in less than 1 second and allow doctors to chat with a community of brain tumor doctors. To achieve these objectives, our system uses a state-of-the-art machine learning algorithm that has been trained on a large dataset of MRI images. The algorithm can accurately classify different types of brain tumors and provide doctors with detailed information on the size, location, and severity of the tumor. Additionally, our system has several features to ensure its security and privacy, including secure login and data encryption. We evaluated our system using a dataset of real-world MRI images and compared its performance to other existing systems. Our results demonstrate that our system is highly accurate, efficient, and easy to use. We believe that our system has the potential to revolutionize the field of brain tumor diagnosis and treatment and provide healthcare professionals with a powerful tool for improving patient outcomes.
Synthesizing Physical Character-Scene Interactions
Feb 02, 2023Movement is how people interact with and affect their environment. For realistic character animation, it is necessary to synthesize such interactions between virtual characters and their surroundings. Despite recent progress in character animation using machine learning, most systems focus on controlling an agent's movements in fairly simple and homogeneous environments, with limited interactions with other objects. Furthermore, many previous approaches that synthesize human-scene interactions require significant manual labeling of the training data. In contrast, we present a system that uses adversarial imitation learning and reinforcement learning to train physically-simulated characters that perform scene interaction tasks in a natural and life-like manner. Our method learns scene interaction behaviors from large unstructured motion datasets, without manual annotation of the motion data. These scene interactions are learned using an adversarial discriminator that evaluates the realism of a motion within the context of a scene. The key novelty involves conditioning both the discriminator and the policy networks on scene context. We demonstrate the effectiveness of our approach through three challenging scene interaction tasks: carrying, sitting, and lying down, which require coordination of a character's movements in relation to objects in the environment. Our policies learn to seamlessly transition between different behaviors like idling, walking, and sitting. By randomizing the properties of the objects and their placements during training, our method is able to generalize beyond the objects and scenarios depicted in the training dataset, producing natural character-scene interactions for a wide variety of object shapes and placements. The approach takes physics-based character motion generation a step closer to broad applicability.
Human-Aware Object Placement for Visual Environment Reconstruction
Mar 28, 2022

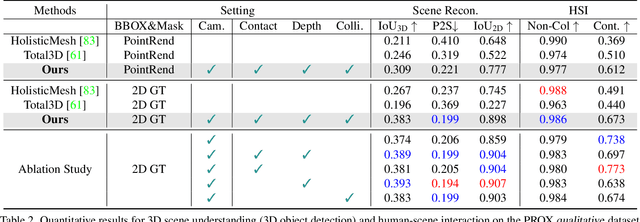
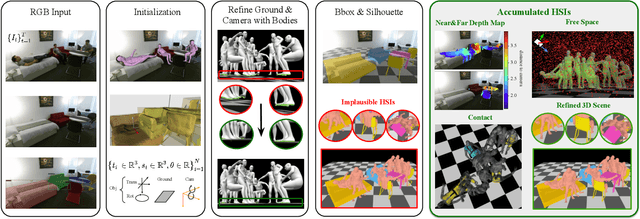
Humans are in constant contact with the world as they move through it and interact with it. This contact is a vital source of information for understanding 3D humans, 3D scenes, and the interactions between them. In fact, we demonstrate that these human-scene interactions (HSIs) can be leveraged to improve the 3D reconstruction of a scene from a monocular RGB video. Our key idea is that, as a person moves through a scene and interacts with it, we accumulate HSIs across multiple input images, and optimize the 3D scene to reconstruct a consistent, physically plausible and functional 3D scene layout. Our optimization-based approach exploits three types of HSI constraints: (1) humans that move in a scene are occluded or occlude objects, thus, defining the depth ordering of the objects, (2) humans move through free space and do not interpenetrate objects, (3) when humans and objects are in contact, the contact surfaces occupy the same place in space. Using these constraints in an optimization formulation across all observations, we significantly improve the 3D scene layout reconstruction. Furthermore, we show that our scene reconstruction can be used to refine the initial 3D human pose and shape (HPS) estimation. We evaluate the 3D scene layout reconstruction and HPS estimation qualitatively and quantitatively using the PROX and PiGraphs datasets. The code and data are available for research purposes at https://mover.is.tue.mpg.de/.
Stochastic Scene-Aware Motion Prediction
Aug 18, 2021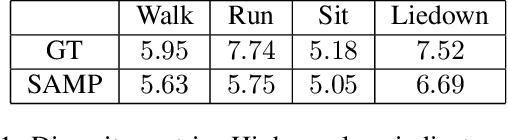

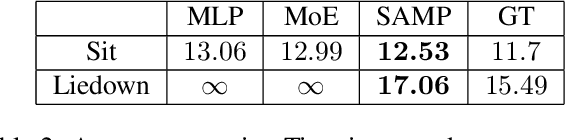

A long-standing goal in computer vision is to capture, model, and realistically synthesize human behavior. Specifically, by learning from data, our goal is to enable virtual humans to navigate within cluttered indoor scenes and naturally interact with objects. Such embodied behavior has applications in virtual reality, computer games, and robotics, while synthesized behavior can be used as a source of training data. This is challenging because real human motion is diverse and adapts to the scene. For example, a person can sit or lie on a sofa in many places and with varying styles. It is necessary to model this diversity when synthesizing virtual humans that realistically perform human-scene interactions. We present a novel data-driven, stochastic motion synthesis method that models different styles of performing a given action with a target object. Our method, called SAMP, for Scene-Aware Motion Prediction, generalizes to target objects of various geometries while enabling the character to navigate in cluttered scenes. To train our method, we collected MoCap data covering various sitting, lying down, walking, and running styles. We demonstrate our method on complex indoor scenes and achieve superior performance compared to existing solutions. Our code and data are available for research at https://samp.is.tue.mpg.de.
Populating 3D Scenes by Learning Human-Scene Interaction
Dec 21, 2020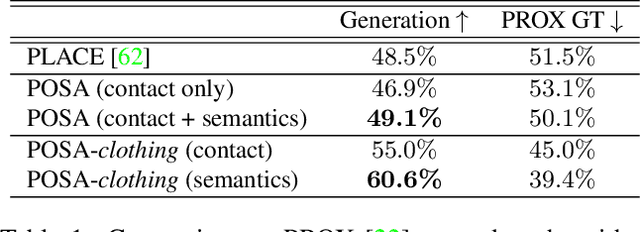
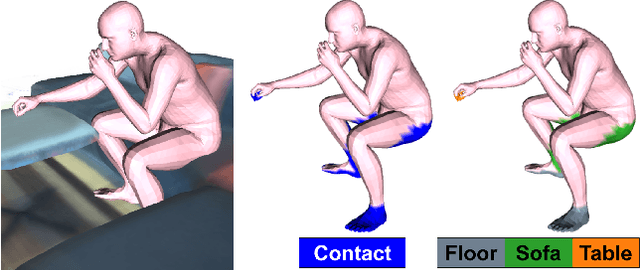


Humans live within a 3D space and constantly interact with it to perform tasks. Such interactions involve physical contact between surfaces that is semantically meaningful. Our goal is to learn how humans interact with scenes and leverage this to enable virtual characters to do the same. To that end, we introduce a novel Human-Scene Interaction (HSI) model that encodes proximal relationships, called POSA for "Pose with prOximitieS and contActs". The representation of interaction is body-centric, which enables it to generalize to new scenes. Specifically, POSA augments the SMPL-X parametric human body model such that, for every mesh vertex, it encodes (a) the contact probability with the scene surface and (b) the corresponding semantic scene label. We learn POSA with a VAE conditioned on the SMPL-X vertices, and train on the PROX dataset, which contains SMPL-X meshes of people interacting with 3D scenes, and the corresponding scene semantics from the PROX-E dataset. We demonstrate the value of POSA with two applications. First, we automatically place 3D scans of people in scenes. We use a SMPL-X model fit to the scan as a proxy and then find its most likely placement in 3D. POSA provides an effective representation to search for "affordances" in the scene that match the likely contact relationships for that pose. We perform a perceptual study that shows significant improvement over the state of the art on this task. Second, we show that POSA's learned representation of body-scene interaction supports monocular human pose estimation that is consistent with a 3D scene, improving on the state of the art. Our model and code will be available for research purposes at https://posa.is.tue.mpg.de.