 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
Apr 13, 2026Clinical deployment of automated brain MRI analysis faces a fundamental challenge: clinical data is heterogeneous and noisy, and high-quality labels are prohibitively costly to obtain. Self-supervised learning (SSL) can address this by leveraging the vast amounts of unlabeled data produced in clinical workflows to train robust \textit{foundation models} that adapt out-of-domain with minimal supervision. However, the development of foundation models for brain MRI has been limited by small pretraining datasets and in-domain benchmarking focused on high-quality, research-grade data. To address this gap, we organized the FOMO25 challenge as a satellite event at MICCAI 2025. FOMO25 provided participants with a large pretraining dataset, FOMO60K, and evaluated models on data sourced directly from clinical workflows in few-shot and out-of-domain settings. Tasks covered infarct classification, meningioma segmentation, and brain age regression, and considered both models trained on FOMO60K (method track) and any data (open track). Nineteen foundation models from sixteen teams were evaluated using a standardized containerized pipeline. Results show that (a) self-supervised pretraining improves generalization on clinical data under domain shift, with the strongest models trained \textit{out-of-domain} surpassing supervised baselines trained \textit{in-domain}. (b) No single pretraining objective benefits all tasks: MAE favors segmentation, hybrid reconstruction-contrastive objectives favor classification, and (c) strong performance was achieved by small pretrained models, and improvements from scaling model size and training duration did not yield reliable benefits.
Feature Selection using the concept of Peafowl Mating in IDS
Feb 03, 2024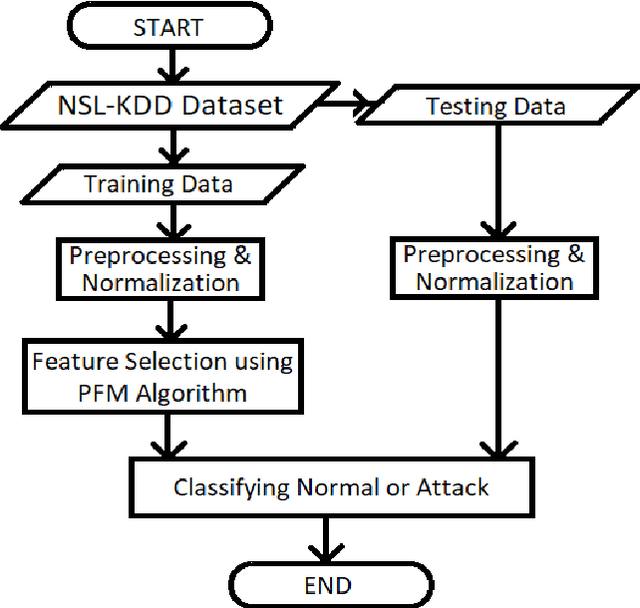
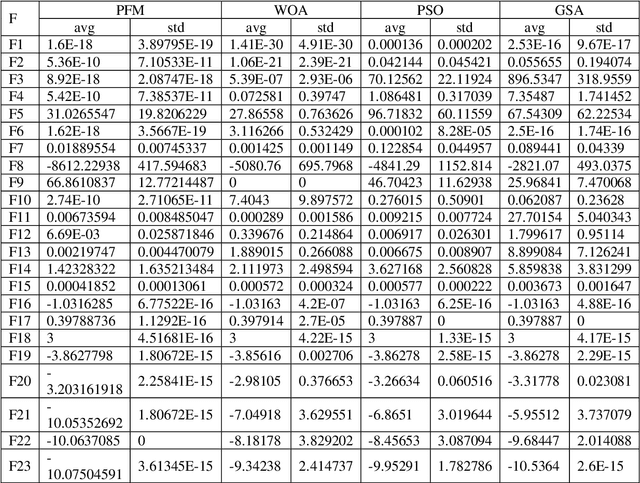

Cloud computing has high applicability as an Internet based service that relies on sharing computing resources. Cloud computing provides services that are Infrastructure based, Platform based and Software based. The popularity of this technology is due to its superb performance, high level of computing ability, low cost of services, scalability, availability and flexibility. The obtainability and openness of data in cloud environment make it vulnerable to the world of cyber-attacks. To detect the attacks Intrusion Detection System is used, that can identify the attacks and ensure information security. Such a coherent and proficient Intrusion Detection System is proposed in this paper to achieve higher certainty levels regarding safety in cloud environment. In this paper, the mating behavior of peafowl is incorporated into an optimization algorithm which in turn is used as a feature selection algorithm. The algorithm is used to reduce the huge size of cloud data so that the IDS can work efficiently on the cloud to detect intrusions. The proposed model has been experimented with NSL-KDD dataset as well as Kyoto dataset and have proved to be a better as well as an efficient IDS.
RAVEN: Rethinking Adversarial Video Generation with Efficient Tri-plane Networks
Jan 11, 2024We present a novel unconditional video generative model designed to address long-term spatial and temporal dependencies. To capture these dependencies, our approach incorporates a hybrid explicit-implicit tri-plane representation inspired by 3D-aware generative frameworks developed for three-dimensional object representation and employs a singular latent code to model an entire video sequence. Individual video frames are then synthesized from an intermediate tri-plane representation, which itself is derived from the primary latent code. This novel strategy reduces computational complexity by a factor of $2$ as measured in FLOPs. Consequently, our approach facilitates the efficient and temporally coherent generation of videos. Moreover, our joint frame modeling approach, in contrast to autoregressive methods, mitigates the generation of visual artifacts. We further enhance the model's capabilities by integrating an optical flow-based module within our Generative Adversarial Network (GAN) based generator architecture, thereby compensating for the constraints imposed by a smaller generator size. As a result, our model is capable of synthesizing high-fidelity video clips at a resolution of $256\times256$ pixels, with durations extending to more than $5$ seconds at a frame rate of 30 fps. The efficacy and versatility of our approach are empirically validated through qualitative and quantitative assessments across three different datasets comprising both synthetic and real video clips.
SCULPT: Shape-Conditioned Unpaired Learning of Pose-dependent Clothed and Textured Human Meshes
Aug 21, 2023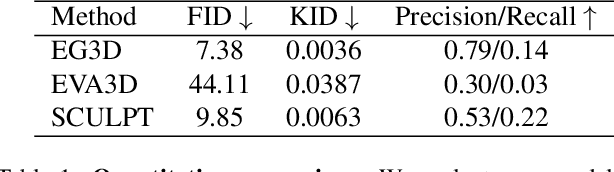
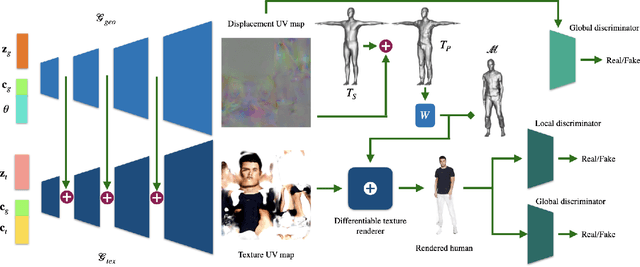


We present SCULPT, a novel 3D generative model for clothed and textured 3D meshes of humans. Specifically, we devise a deep neural network that learns to represent the geometry and appearance distribution of clothed human bodies. Training such a model is challenging, as datasets of textured 3D meshes for humans are limited in size and accessibility. Our key observation is that there exist medium-sized 3D scan datasets like CAPE, as well as large-scale 2D image datasets of clothed humans and multiple appearances can be mapped to a single geometry. To effectively learn from the two data modalities, we propose an unpaired learning procedure for pose-dependent clothed and textured human meshes. Specifically, we learn a pose-dependent geometry space from 3D scan data. We represent this as per vertex displacements w.r.t. the SMPL model. Next, we train a geometry conditioned texture generator in an unsupervised way using the 2D image data. We use intermediate activations of the learned geometry model to condition our texture generator. To alleviate entanglement between pose and clothing type, and pose and clothing appearance, we condition both the texture and geometry generators with attribute labels such as clothing types for the geometry, and clothing colors for the texture generator. We automatically generated these conditioning labels for the 2D images based on the visual question answering model BLIP and CLIP. We validate our method on the SCULPT dataset, and compare to state-of-the-art 3D generative models for clothed human bodies. We will release the codebase for research purposes.
Adversarial Likelihood Estimation with One-way Flows
Jul 19, 2023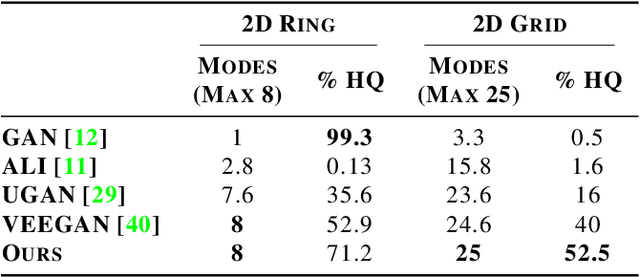
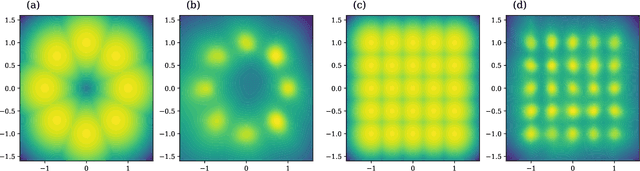
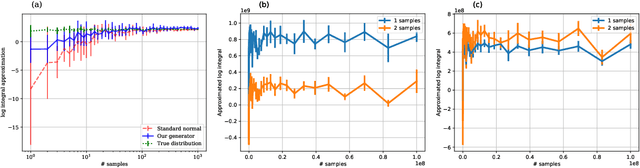

Generative Adversarial Networks (GANs) can produce high-quality samples, but do not provide an estimate of the probability density around the samples. However, it has been noted that maximizing the log-likelihood within an energy-based setting can lead to an adversarial framework where the discriminator provides unnormalized density (often called energy). We further develop this perspective, incorporate importance sampling, and show that 1) Wasserstein GAN performs a biased estimate of the partition function, and we propose instead to use an unbiased estimator; 2) when optimizing for likelihood, one must maximize generator entropy. This is hypothesized to provide a better mode coverage. Different from previous works, we explicitly compute the density of the generated samples. This is the key enabler to designing an unbiased estimator of the partition function and computation of the generator entropy term. The generator density is obtained via a new type of flow network, called one-way flow network, that is less constrained in terms of architecture, as it does not require to have a tractable inverse function. Our experimental results show that we converge faster, produce comparable sample quality to GANs with similar architecture, successfully avoid over-fitting to commonly used datasets and produce smooth low-dimensional latent representations of the training data.
Nonwatertight Mesh Reconstruction
Jun 26, 2022

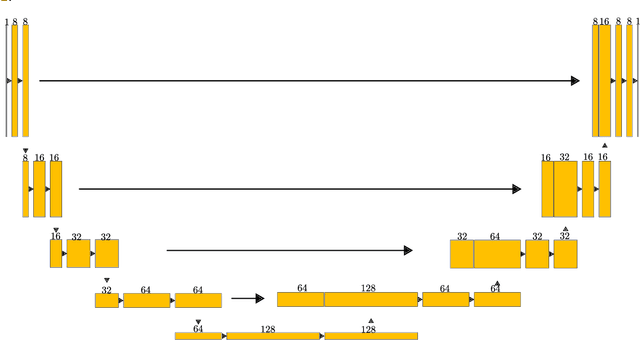
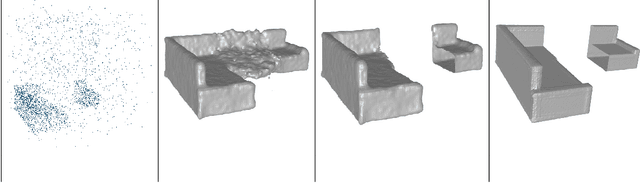
Reconstructing 3D non-watertight mesh from an unoriented point cloud is an unexplored area in computer vision and computer graphics. In this project, we tried to tackle this problem by extending the learning-based watertight mesh reconstruction pipeline presented in the paper 'Shape as Points'. The core of our approach is to cast the problem as a semantic segmentation problem that identifies the region in the 3D volume where the mesh surface lies and extracts the surfaces from the detected regions. Our approach achieves compelling results compared to the baseline techniques.
LED: Latent Variable-based Estimation of Density
Jun 23, 2022
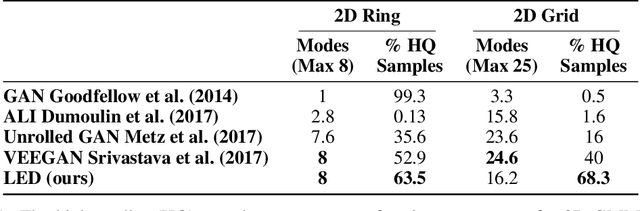

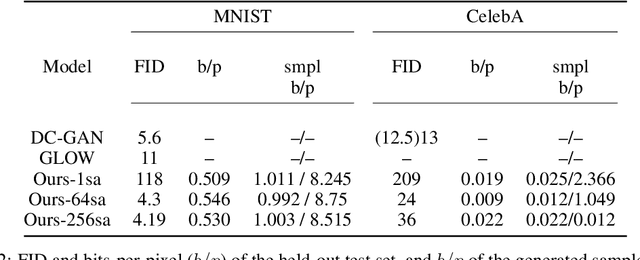
Modern generative models are roughly divided into two main categories: (1) models that can produce high-quality random samples, but cannot estimate the exact density of new data points and (2) those that provide exact density estimation, at the expense of sample quality and compactness of the latent space. In this work we propose LED, a new generative model closely related to GANs, that allows not only efficient sampling but also efficient density estimation. By maximizing log-likelihood on the output of the discriminator, we arrive at an alternative adversarial optimization objective that encourages generated data diversity. This formulation provides insights into the relationships between several popular generative models. Additionally, we construct a flow-based generator that can compute exact probabilities for generated samples, while allowing low-dimensional latent variables as input. Our experimental results, on various datasets, show that our density estimator produces accurate estimates, while retaining good quality in the generated samples.
InvGAN: Invertible GANs
Dec 10, 2021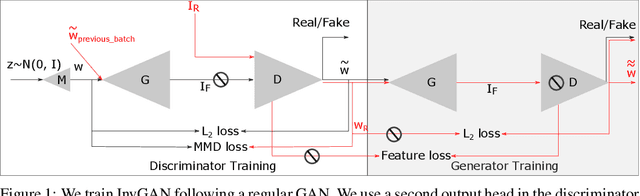
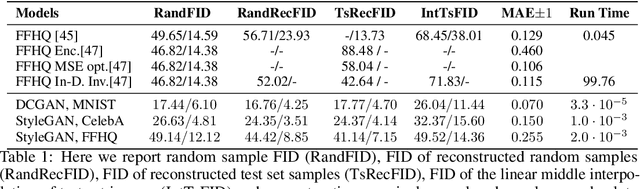


Generation of photo-realistic images, semantic editing and representation learning are a few of many potential applications of high resolution generative models. Recent progress in GANs have established them as an excellent choice for such tasks. However, since they do not provide an inference model, image editing or downstream tasks such as classification can not be done on real images using the GAN latent space. Despite numerous efforts to train an inference model or design an iterative method to invert a pre-trained generator, previous methods are dataset (e.g. human face images) and architecture (e.g. StyleGAN) specific. These methods are nontrivial to extend to novel datasets or architectures. We propose a general framework that is agnostic to architecture and datasets. Our key insight is that, by training the inference and the generative model together, we allow them to adapt to each other and to converge to a better quality model. Our \textbf{InvGAN}, short for Invertible GAN, successfully embeds real images to the latent space of a high quality generative model. This allows us to perform image inpainting, merging, interpolation and online data augmentation. We demonstrate this with extensive qualitative and quantitative experiments.
Populating 3D Scenes by Learning Human-Scene Interaction
Dec 21, 2020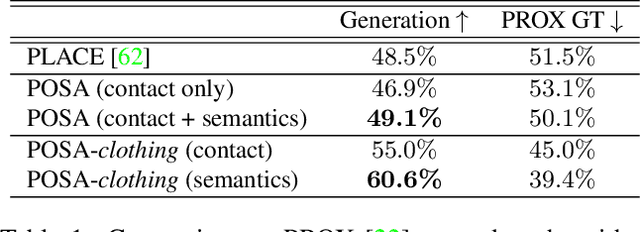
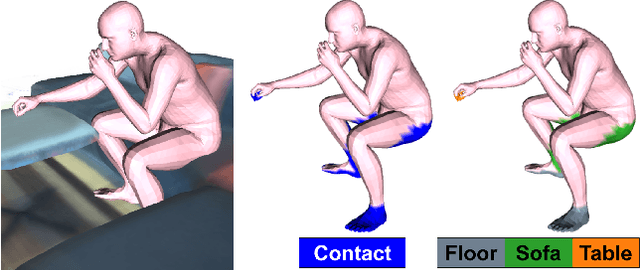


Humans live within a 3D space and constantly interact with it to perform tasks. Such interactions involve physical contact between surfaces that is semantically meaningful. Our goal is to learn how humans interact with scenes and leverage this to enable virtual characters to do the same. To that end, we introduce a novel Human-Scene Interaction (HSI) model that encodes proximal relationships, called POSA for "Pose with prOximitieS and contActs". The representation of interaction is body-centric, which enables it to generalize to new scenes. Specifically, POSA augments the SMPL-X parametric human body model such that, for every mesh vertex, it encodes (a) the contact probability with the scene surface and (b) the corresponding semantic scene label. We learn POSA with a VAE conditioned on the SMPL-X vertices, and train on the PROX dataset, which contains SMPL-X meshes of people interacting with 3D scenes, and the corresponding scene semantics from the PROX-E dataset. We demonstrate the value of POSA with two applications. First, we automatically place 3D scans of people in scenes. We use a SMPL-X model fit to the scan as a proxy and then find its most likely placement in 3D. POSA provides an effective representation to search for "affordances" in the scene that match the likely contact relationships for that pose. We perform a perceptual study that shows significant improvement over the state of the art on this task. Second, we show that POSA's learned representation of body-scene interaction supports monocular human pose estimation that is consistent with a 3D scene, improving on the state of the art. Our model and code will be available for research purposes at https://posa.is.tue.mpg.de.
GIF: Generative Interpretable Faces
Aug 31, 2020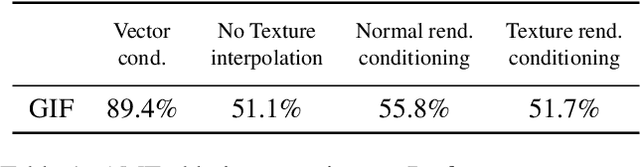
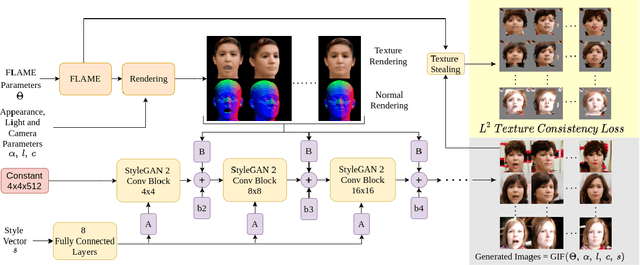
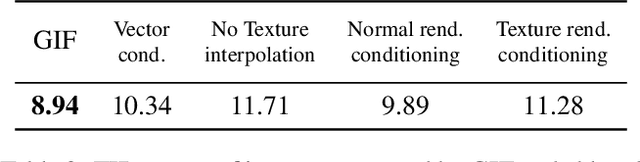

Photo-realistic visualization and animation of expressive human faces have been a long standing challenge. On one end of the spectrum, 3D face modeling methods provide parametric control but tend to generate unrealistic images, while on the other end, generative 2D models like GANs (Generative Adversarial Networks) output photo-realistic face images, but lack explicit control. Recent methods gain partial control, either by attempting to disentangle different factors in an unsupervised manner, or by adding control post hoc to a pre-trained model. Trained GANs without pre-defined control, however, may entangle factors that are hard to undo later. To guarantee some disentanglement that provides us with desired kinds of control, we train our generative model conditioned on pre-defined control parameters. Specifically, we condition StyleGAN2 on FLAME, a generative 3D face model. However, we found out that a naive conditioning on FLAME parameters yields rather unsatisfactory results. Instead we render out geometry and photo-metric details of the FLAME mesh and use these for conditioning instead. This gives us a generative 2D face model named GIF (Generative Interpretable Faces) that shares FLAME's parametric control. Given FLAME parameters for shape, pose, and expressions, parameters for appearance and lighting, and an additional style vector, GIF outputs photo-realistic face images. To evaluate how well GIF follows its conditioning and the impact of different design choices, we perform a perceptual study. The code and trained model are publicly available for research purposes at https://github.com/ParthaEth/GIF.