 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-to-Sim Robot Policy Evaluation with Gaussian Splatting Simulation of Soft-Body Interactions
Nov 06, 2025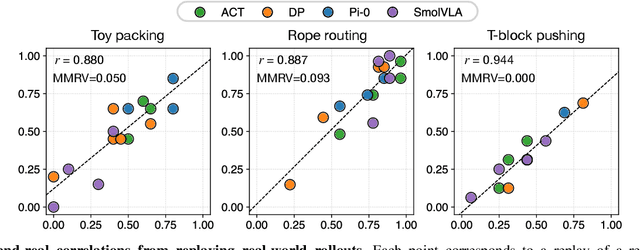

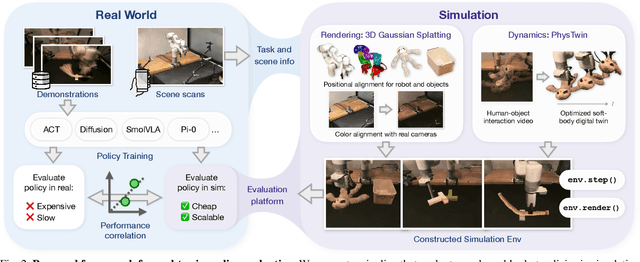
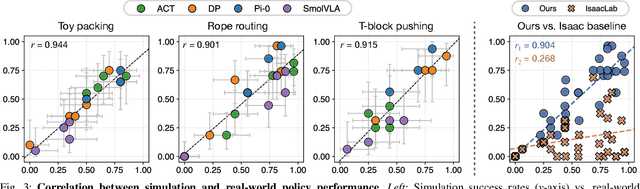
Robotic manipulation policies are advancing rapidly, but their direct evaluation in the real world remains costly, time-consuming, and difficult to reproduce, particularly for tasks involving deformable objects. Simulation provides a scalable and systematic alternative, yet existing simulators often fail to capture the coupled visual and physical complexity of soft-body interactions. We present a real-to-sim policy evaluation framework that constructs soft-body digital twins from real-world videos and renders robots, objects, and environments with photorealistic fidelity using 3D Gaussian Splatting. We validate our approach on representative deformable manipulation tasks, including plush toy packing, rope routing, and T-block pushing, demonstrating that simulated rollouts correlate strongly with real-world execution performance and reveal key behavioral patterns of learned policies. Our results suggest that combining physics-informed reconstruction with high-quality rendering enables reproducible, scalable, and accurate evaluation of robotic manipulation policies. Website: https://real2sim-eval.github.io/
Textureless Deformable Surface Reconstruction with Invisible Markers
Aug 25, 2023Reconstructing and tracking deformable surface with little or no texture has posed long-standing challenges. Fundamentally, the challenges stem from textureless surfaces lacking features for establishing cross-image correspondences. In this work, we present a novel type of markers to proactively enrich the object's surface features, and thereby ease the 3D surface reconstruction and correspondence tracking. Our markers are made of fluorescent dyes, visible only under the ultraviolet (UV) light and invisible under regular lighting condition. Leveraging the markers, we design a multi-camera system that captures surface deformation under the UV light and the visible light in a time multiplexing fashion. Under the UV light, markers on the object emerge to enrich its surface texture, allowing high-quality 3D shape reconstruction and tracking. Under the visible light, markers become invisible, allowing us to capture the object's original untouched appearance. We perform experiments on various challenging scenes, including hand gestures, facial expressions, waving cloth, and hand-object interaction. In all these cases, we demonstrate that our system is able to produce robust, high-quality 3D reconstruction and tracking.
InvGAN: Invertible GANs
Dec 10, 2021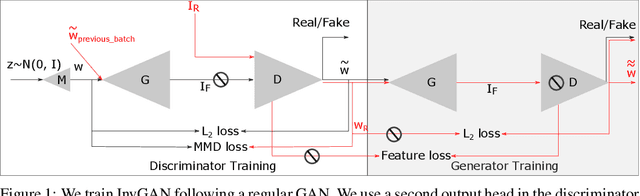
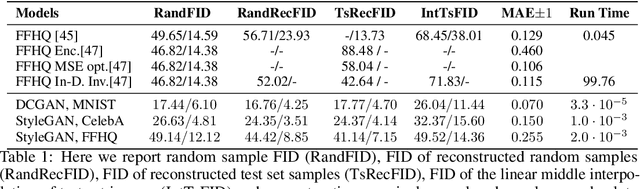


Generation of photo-realistic images, semantic editing and representation learning are a few of many potential applications of high resolution generative models. Recent progress in GANs have established them as an excellent choice for such tasks. However, since they do not provide an inference model, image editing or downstream tasks such as classification can not be done on real images using the GAN latent space. Despite numerous efforts to train an inference model or design an iterative method to invert a pre-trained generator, previous methods are dataset (e.g. human face images) and architecture (e.g. StyleGAN) specific. These methods are nontrivial to extend to novel datasets or architectures. We propose a general framework that is agnostic to architecture and datasets. Our key insight is that, by training the inference and the generative model together, we allow them to adapt to each other and to converge to a better quality model. Our \textbf{InvGAN}, short for Invertible GAN, successfully embeds real images to the latent space of a high quality generative model. This allows us to perform image inpainting, merging, interpolation and online data augmentation. We demonstrate this with extensive qualitative and quantitative experiments.
FACSIMILE: Fast and Accurate Scans From an Image in Less Than a Second
Sep 02, 2019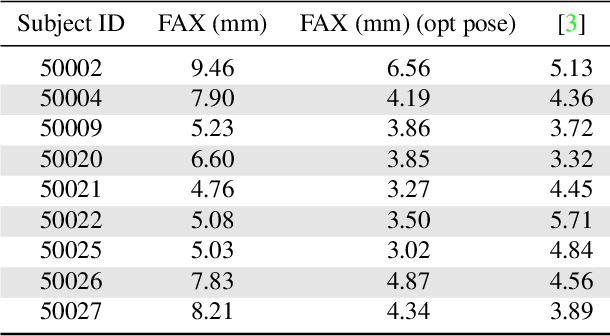
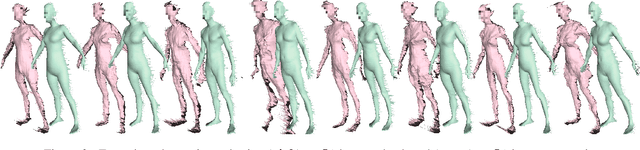
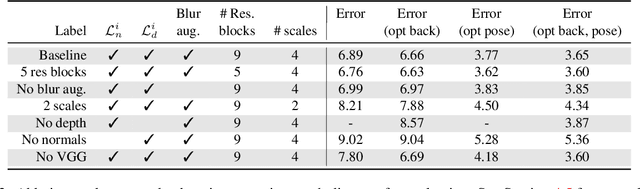
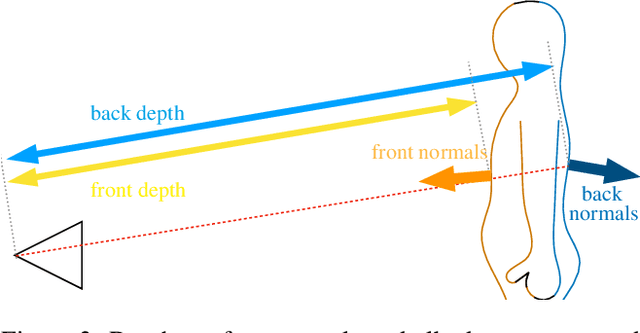
Current methods for body shape estimation either lack detail or require many images. They are usually architecturally complex and computationally expensive. We propose FACSIMILE (FAX), a method that estimates a detailed body from a single photo, lowering the bar for creating virtual representations of humans. Our approach is easy to implement and fast to execute, making it easily deployable. FAX uses an image-translation network which recovers geometry at the original resolution of the image. Counterintuitively, the main loss which drives FAX is on per-pixel surface normals instead of per-pixel depth, making it possible to estimate detailed body geometry without any depth supervision. We evaluate our approach both qualitatively and quantitatively, and compare with a state-of-the-art method.