 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-to-Sim Robot Policy Evaluation with Gaussian Splatting Simulation of Soft-Body Interactions
Nov 06, 2025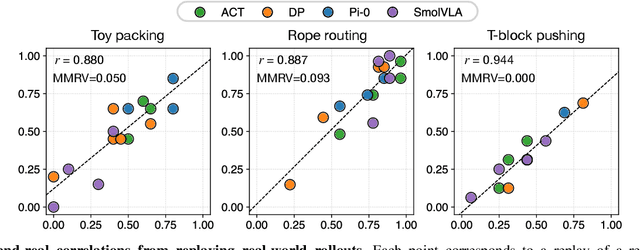

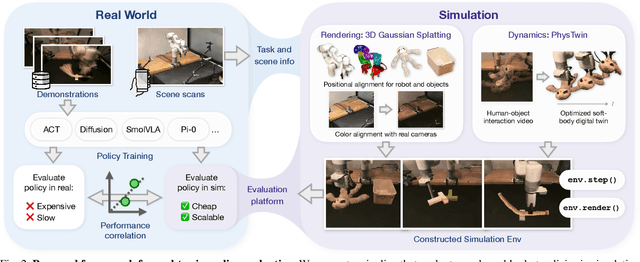
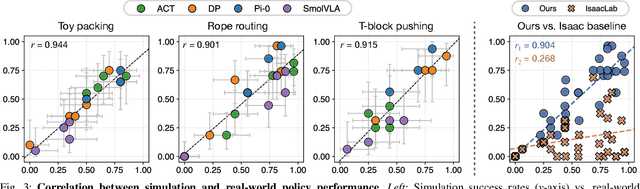
Robotic manipulation policies are advancing rapidly, but their direct evaluation in the real world remains costly, time-consuming, and difficult to reproduce, particularly for tasks involving deformable objects. Simulation provides a scalable and systematic alternative, yet existing simulators often fail to capture the coupled visual and physical complexity of soft-body interactions. We present a real-to-sim policy evaluation framework that constructs soft-body digital twins from real-world videos and renders robots, objects, and environments with photorealistic fidelity using 3D Gaussian Splatting. We validate our approach on representative deformable manipulation tasks, including plush toy packing, rope routing, and T-block pushing, demonstrating that simulated rollouts correlate strongly with real-world execution performance and reveal key behavioral patterns of learned policies. Our results suggest that combining physics-informed reconstruction with high-quality rendering enables reproducible, scalable, and accurate evaluation of robotic manipulation policies. Website: https://real2sim-eval.github.io/
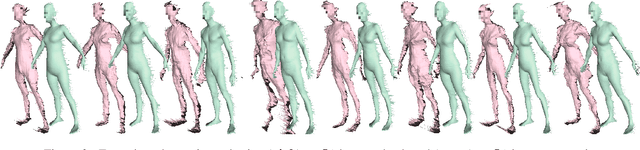
Learning Realistic Human Reposing using Cyclic Self-Supervision with 3D Shape, Pose, and Appearance Consistency
Oct 11, 2021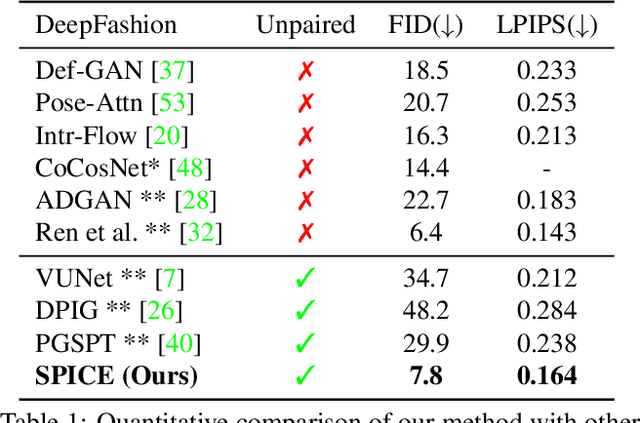

Synthesizing images of a person in novel poses from a single image is a highly ambiguous task. Most existing approaches require paired training images; i.e. images of the same person with the same clothing in different poses. However, obtaining sufficiently large datasets with paired data is challenging and costly. Previous methods that forego paired supervision lack realism. We propose a self-supervised framework named SPICE (Self-supervised Person Image CrEation) that closes the image quality gap with supervised methods. The key insight enabling self-supervision is to exploit 3D information about the human body in several ways. First, the 3D body shape must remain unchanged when reposing. Second, representing body pose in 3D enables reasoning about self occlusions. Third, 3D body parts that are visible before and after reposing, should have similar appearance features. Once trained, SPICE takes an image of a person and generates a new image of that person in a new target pose. SPICE achieves state-of-the-art performance on the DeepFashion dataset, improving the FID score from 29.9 to 7.8 compared with previous unsupervised methods, and with performance similar to the state-of-the-art supervised method (6.4). SPICE also generates temporally coherent videos given an input image and a sequence of poses, despite being trained on static images only.
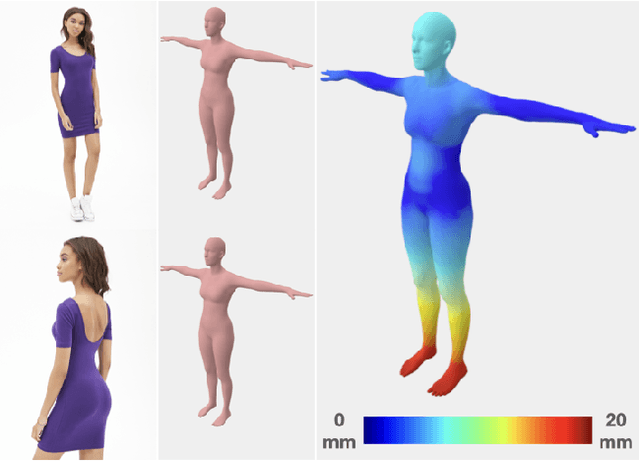
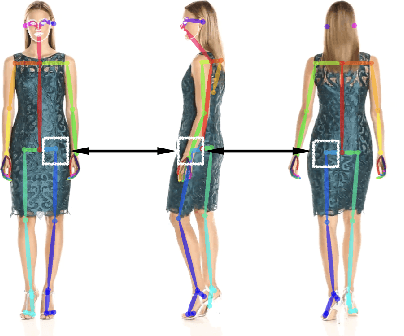
FACSIMILE: Fast and Accurate Scans From an Image in Less Than a Second
Sep 02, 2019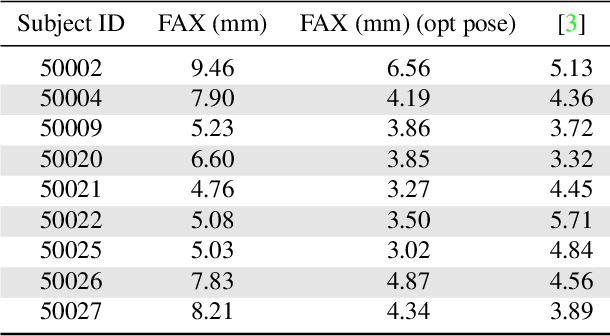
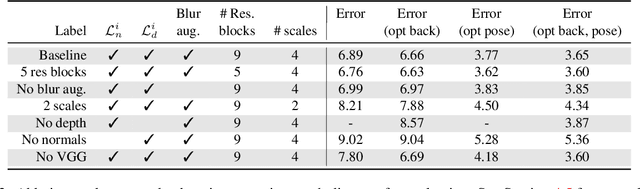
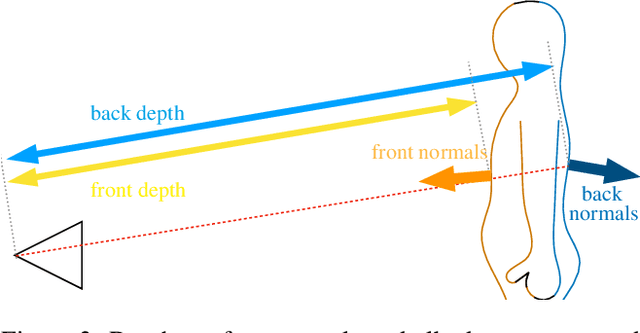
Current methods for body shape estimation either lack detail or require many images. They are usually architecturally complex and computationally expensive. We propose FACSIMILE (FAX), a method that estimates a detailed body from a single photo, lowering the bar for creating virtual representations of humans. Our approach is easy to implement and fast to execute, making it easily deployable. FAX uses an image-translation network which recovers geometry at the original resolution of the image. Counterintuitively, the main loss which drives FAX is on per-pixel surface normals instead of per-pixel depth, making it possible to estimate detailed body geometry without any depth supervision. We evaluate our approach both qualitatively and quantitatively, and compare with a state-of-the-art method.
The Informed Sampler: A Discriminative Approach to Bayesian Inference in Generative Computer Vision Models
Mar 07, 2015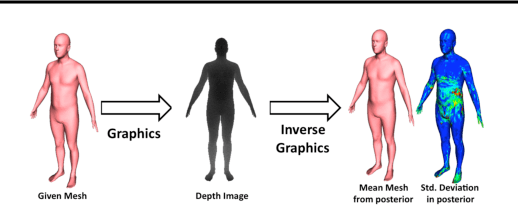
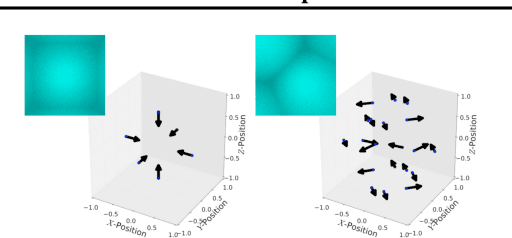
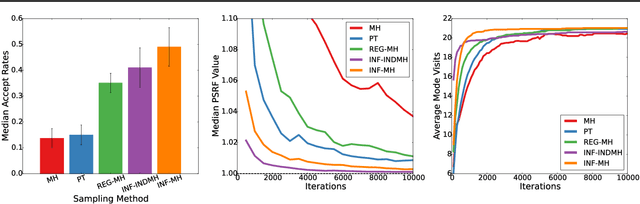
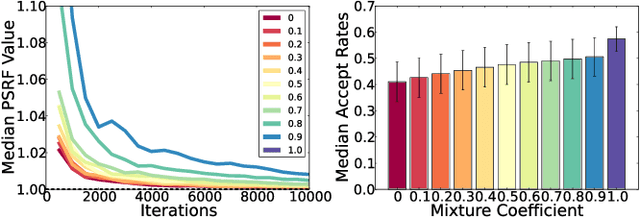
Computer vision is hard because of a large variability in lighting, shape, and texture; in addition the image signal is non-additive due to occlusion. Generative models promised to account for this variability by accurately modelling the image formation process as a function of latent variables with prior beliefs. Bayesian posterior inference could then, in principle, explain the observation. While intuitively appealing, generative models for computer vision have largely failed to deliver on that promise due to the difficulty of posterior inference. As a result the community has favoured efficient discriminative approaches. We still believe in the usefulness of generative models in computer vision, but argue that we need to leverage existing discriminative or even heuristic computer vision methods. We implement this idea in a principled way with an "informed sampler" and in careful experiments demonstrate it on challenging generative models which contain renderer programs as their components. We concentrate on the problem of inverting an existing graphics rendering engine, an approach that can be understood as "Inverse Graphics". The informed sampler, using simple discriminative proposals based on existing computer vision technology, achieves significant improvements of inference.