 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransText: Alpha-as-RGB Representation for Transparent Text Animation
Mar 19, 2026We introduce the first method, to the best of our knowledge, for adapting image-to-video models to layer-aware text (glyph) animation, a capability critical for practical dynamic visual design. Existing approaches predominantly handle the transparency-encoding (alpha channel) as an extra latent dimension appended to the RGB space, necessitating the reconstruction of the underlying RGB-centric variational autoencoder (VAE). However, given the scarcity of high-quality transparent glyph data, retraining the VAE is computationally expensive and may erode the robust semantic priors learned from massive RGB corpora, potentially leading to latent pattern mixing. To mitigate these limitations, we propose TransText, a framework based on a novel Alpha-as-RGB paradigm to jointly model appearance and transparency without modifying the pre-trained generative manifold. TransText embeds the alpha channel as an RGB-compatible visual signal through latent spatial concatenation, explicitly ensuring strict cross-modal (RGB-and-Alpha) consistency while preventing feature entanglement. Our experiments demonstrate that TransText significantly outperforms baselines, generating coherent, high-fidelity transparent animations with diverse, fine-grained effects.
Generative Zoo
Dec 11, 2024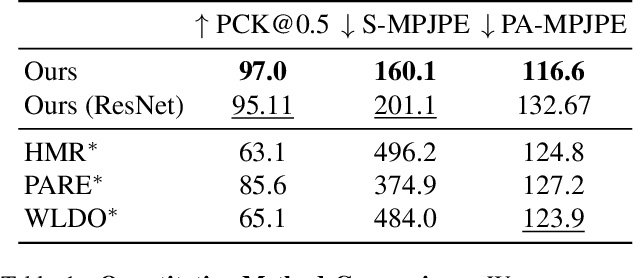
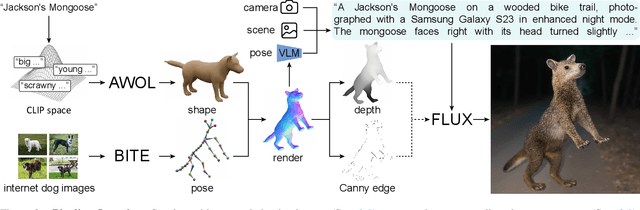
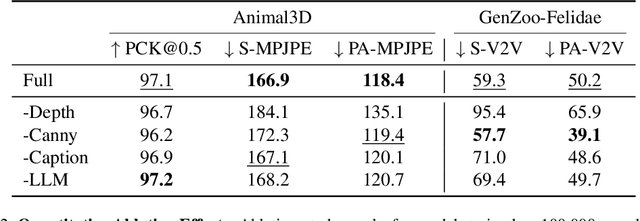

The model-based estimation of 3D animal pose and shape from images enables computational modeling of animal behavior. Training models for this purpose requires large amounts of labeled image data with precise pose and shape annotations. However, capturing such data requires the use of multi-view or marker-based motion-capture systems, which are impractical to adapt to wild animals in situ and impossible to scale across a comprehensive set of animal species. Some have attempted to address the challenge of procuring training data by pseudo-labeling individual real-world images through manual 2D annotation, followed by 3D-parameter optimization to those labels. While this approach may produce silhouette-aligned samples, the obtained pose and shape parameters are often implausible due to the ill-posed nature of the monocular fitting problem. Sidestepping real-world ambiguity, others have designed complex synthetic-data-generation pipelines leveraging video-game engines and collections of artist-designed 3D assets. Such engines yield perfect ground-truth annotations but are often lacking in visual realism and require considerable manual effort to adapt to new species or environments. Motivated by these shortcomings, we propose an alternative approach to synthetic-data generation: rendering with a conditional image-generation model. We introduce a pipeline that samples a diverse set of poses and shapes for a variety of mammalian quadrupeds and generates realistic images with corresponding ground-truth pose and shape parameters. To demonstrate the scalability of our approach, we introduce GenZoo, a synthetic dataset containing one million images of distinct subjects. We train a 3D pose and shape regressor on GenZoo, which achieves state-of-the-art performance on a real-world animal pose and shape estimation benchmark, despite being trained solely on synthetic data. https://genzoo.is.tue.mpg.de
RAVEN: Rethinking Adversarial Video Generation with Efficient Tri-plane Networks
Jan 11, 2024We present a novel unconditional video generative model designed to address long-term spatial and temporal dependencies. To capture these dependencies, our approach incorporates a hybrid explicit-implicit tri-plane representation inspired by 3D-aware generative frameworks developed for three-dimensional object representation and employs a singular latent code to model an entire video sequence. Individual video frames are then synthesized from an intermediate tri-plane representation, which itself is derived from the primary latent code. This novel strategy reduces computational complexity by a factor of $2$ as measured in FLOPs. Consequently, our approach facilitates the efficient and temporally coherent generation of videos. Moreover, our joint frame modeling approach, in contrast to autoregressive methods, mitigates the generation of visual artifacts. We further enhance the model's capabilities by integrating an optical flow-based module within our Generative Adversarial Network (GAN) based generator architecture, thereby compensating for the constraints imposed by a smaller generator size. As a result, our model is capable of synthesizing high-fidelity video clips at a resolution of $256\times256$ pixels, with durations extending to more than $5$ seconds at a frame rate of 30 fps. The efficacy and versatility of our approach are empirically validated through qualitative and quantitative assessments across three different datasets comprising both synthetic and real video clips.
Environment-Specific People
Dec 22, 2023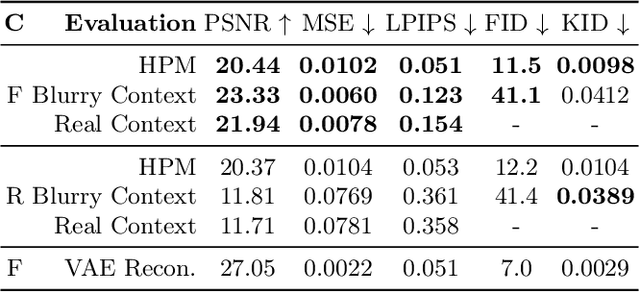
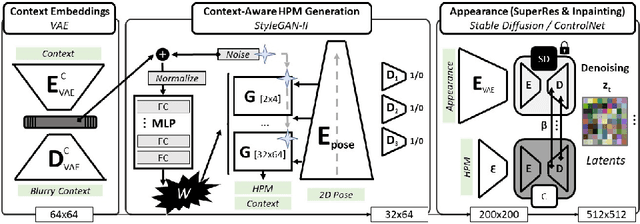

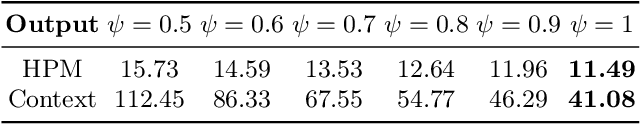
Despite significant progress in generative image synthesis and full-body generation in particular, state-of-the-art methods are either context-independent, overly reliant to text prompts, or bound to the curated training datasets, such as fashion images with monotonous backgrounds. Here, our goal is to generate people in clothing that is semantically appropriate for a given scene. To this end, we present ESP, a novel method for context-aware full-body generation, that enables photo-realistic inpainting of people into existing "in-the-wild" photographs. ESP is conditioned on a 2D pose and contextual cues that are extracted from the environment photograph and integrated into the generation process. Our models are trained on a dataset containing a set of in-the-wild photographs of people covering a wide range of different environments. The method is analyzed quantitatively and qualitatively, and we show that ESP outperforms state-of-the-art on the task of contextual full-body generation.
SCULPT: Shape-Conditioned Unpaired Learning of Pose-dependent Clothed and Textured Human Meshes
Aug 21, 2023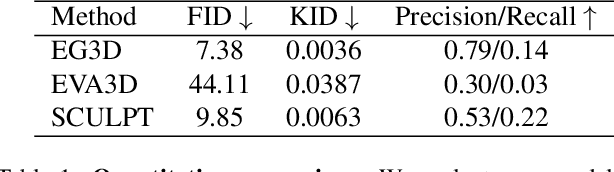
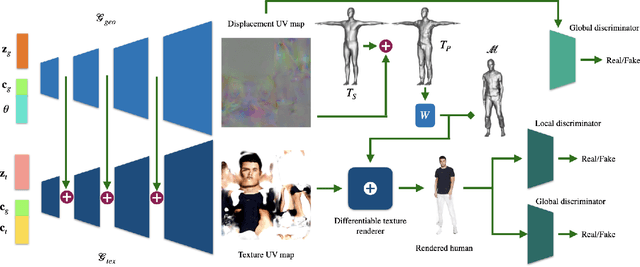


We present SCULPT, a novel 3D generative model for clothed and textured 3D meshes of humans. Specifically, we devise a deep neural network that learns to represent the geometry and appearance distribution of clothed human bodies. Training such a model is challenging, as datasets of textured 3D meshes for humans are limited in size and accessibility. Our key observation is that there exist medium-sized 3D scan datasets like CAPE, as well as large-scale 2D image datasets of clothed humans and multiple appearances can be mapped to a single geometry. To effectively learn from the two data modalities, we propose an unpaired learning procedure for pose-dependent clothed and textured human meshes. Specifically, we learn a pose-dependent geometry space from 3D scan data. We represent this as per vertex displacements w.r.t. the SMPL model. Next, we train a geometry conditioned texture generator in an unsupervised way using the 2D image data. We use intermediate activations of the learned geometry model to condition our texture generator. To alleviate entanglement between pose and clothing type, and pose and clothing appearance, we condition both the texture and geometry generators with attribute labels such as clothing types for the geometry, and clothing colors for the texture generator. We automatically generated these conditioning labels for the 2D images based on the visual question answering model BLIP and CLIP. We validate our method on the SCULPT dataset, and compare to state-of-the-art 3D generative models for clothed human bodies. We will release the codebase for research purposes.
Learning Realistic Human Reposing using Cyclic Self-Supervision with 3D Shape, Pose, and Appearance Consistency
Oct 11, 2021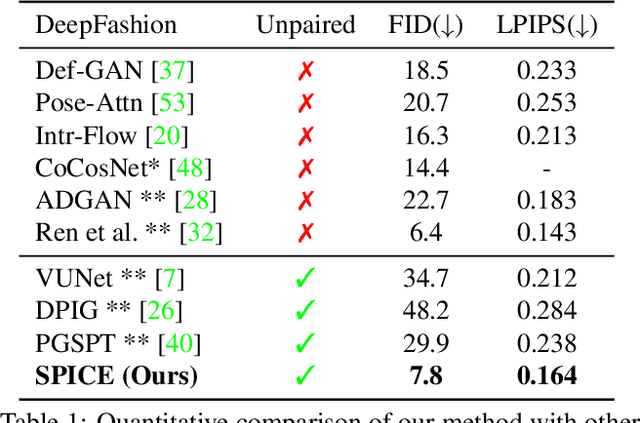
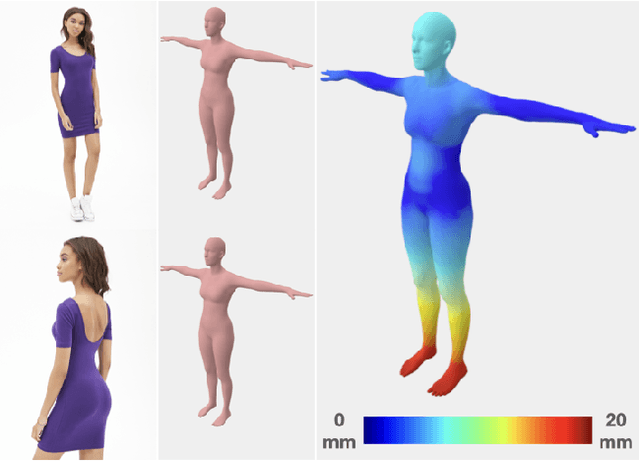

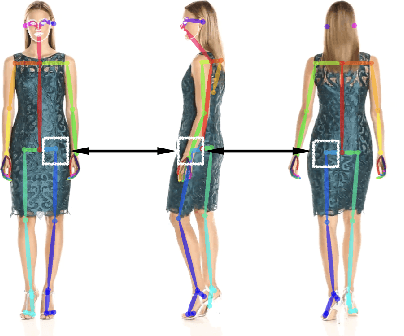
Synthesizing images of a person in novel poses from a single image is a highly ambiguous task. Most existing approaches require paired training images; i.e. images of the same person with the same clothing in different poses. However, obtaining sufficiently large datasets with paired data is challenging and costly. Previous methods that forego paired supervision lack realism. We propose a self-supervised framework named SPICE (Self-supervised Person Image CrEation) that closes the image quality gap with supervised methods. The key insight enabling self-supervision is to exploit 3D information about the human body in several ways. First, the 3D body shape must remain unchanged when reposing. Second, representing body pose in 3D enables reasoning about self occlusions. Third, 3D body parts that are visible before and after reposing, should have similar appearance features. Once trained, SPICE takes an image of a person and generates a new image of that person in a new target pose. SPICE achieves state-of-the-art performance on the DeepFashion dataset, improving the FID score from 29.9 to 7.8 compared with previous unsupervised methods, and with performance similar to the state-of-the-art supervised method (6.4). SPICE also generates temporally coherent videos given an input image and a sequence of poses, despite being trained on static images only.
Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
May 16, 2019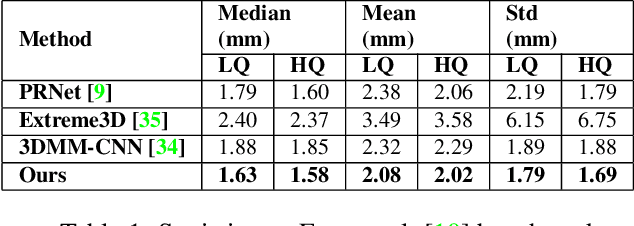
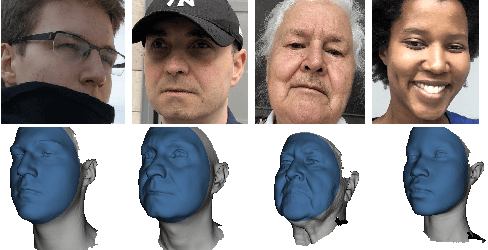
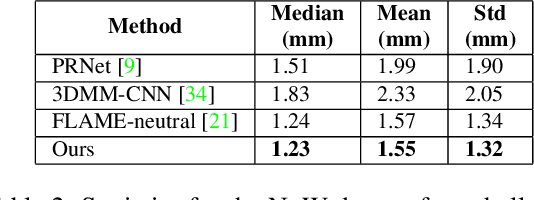
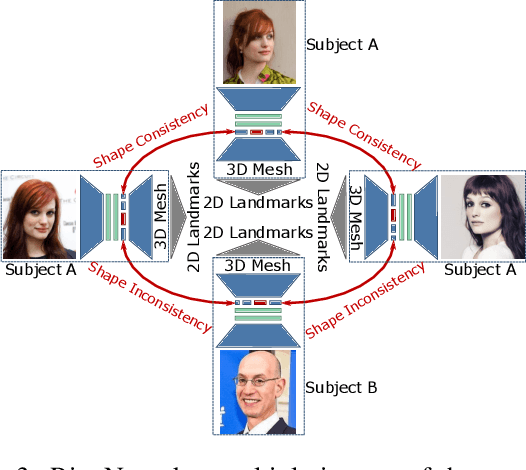
The estimation of 3D face shape from a single image must be robust to variations in lighting, head pose, expression, facial hair, makeup, and occlusions. Robustness requires a large training set of in-the-wild images, which by construction, lack ground truth 3D shape. To train a network without any 2D-to-3D supervision, we present RingNet, which learns to compute 3D face shape from a single image. Our key observation is that an individual's face shape is constant across images, regardless of expression, pose, lighting, etc. RingNet leverages multiple images of a person and automatically detected 2D face features. It uses a novel loss that encourages the face shape to be similar when the identity is the same and different for different people. We achieve invariance to expression by representing the face using the FLAME model. Once trained, our method takes a single image and outputs the parameters of FLAME, which can be readily animated. Additionally we create a new database of faces `not quite in-the-wild' (NoW) with 3D head scans and high-resolution images of the subjects in a wide variety of conditions. We evaluate publicly available methods and find that RingNet is more accurate than methods that use 3D supervision. The dataset, model, and results are available for research purposes at http://ringnet.is.tuebingen.mpg.de.
Generating 3D faces using Convolutional Mesh Autoencoders
Jul 31, 2018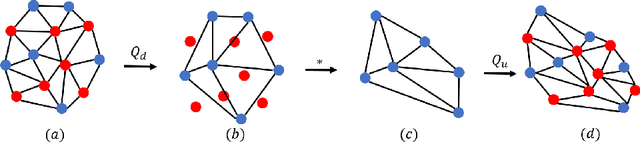

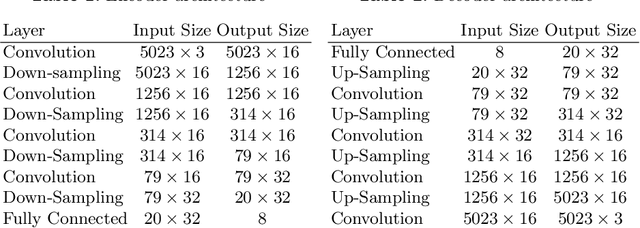

Learned 3D representations of human faces are useful for computer vision problems such as 3D face tracking and reconstruction from images, as well as graphics applications such as character generation and animation. Traditional models learn a latent representation of a face using linear subspaces or higher-order tensor generalizations. Due to this linearity, they can not capture extreme deformations and non-linear expressions. To address this, we introduce a versatile model that learns a non-linear representation of a face using spectral convolutions on a mesh surface. We introduce mesh sampling operations that enable a hierarchical mesh representation that captures non-linear variations in shape and expression at multiple scales within the model. In a variational setting, our model samples diverse realistic 3D faces from a multivariate Gaussian distribution. Our training data consists of 20,466 meshes of extreme expressions captured over 12 different subjects. Despite limited training data, our trained model outperforms state-of-the-art face models with 50% lower reconstruction error, while using 75% fewer parameters. We also show that, replacing the expression space of an existing state-of-the-art face model with our autoencoder, achieves a lower reconstruction error. Our data, model and code are available at http://github.com/anuragranj/coma