 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment-Specific People
Paper and Code
Dec 22, 2023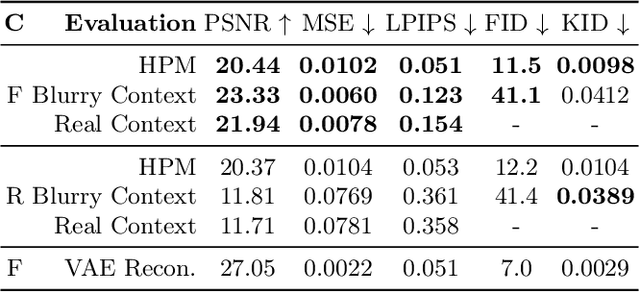
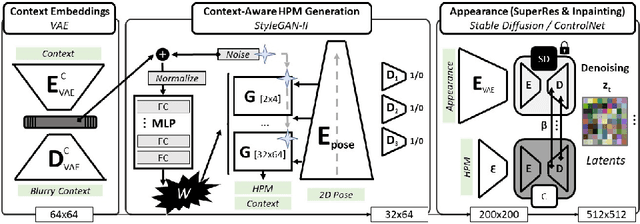

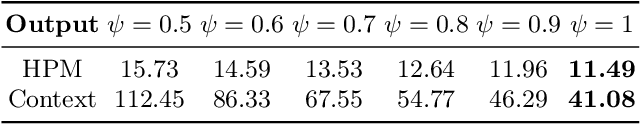
Despite significant progress in generative image synthesis and full-body generation in particular, state-of-the-art methods are either context-independent, overly reliant to text prompts, or bound to the curated training datasets, such as fashion images with monotonous backgrounds. Here, our goal is to generate people in clothing that is semantically appropriate for a given scene. To this end, we present ESP, a novel method for context-aware full-body generation, that enables photo-realistic inpainting of people into existing "in-the-wild" photographs. ESP is conditioned on a 2D pose and contextual cues that are extracted from the environment photograph and integrated into the generation process. Our models are trained on a dataset containing a set of in-the-wild photographs of people covering a wide range of different environments. The method is analyzed quantitatively and qualitatively, and we show that ESP outperforms state-of-the-art on the task of contextual full-body generation.