 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating 3D faces using Convolutional Mesh Autoencoders
Paper and Code
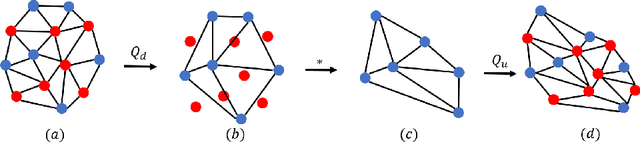

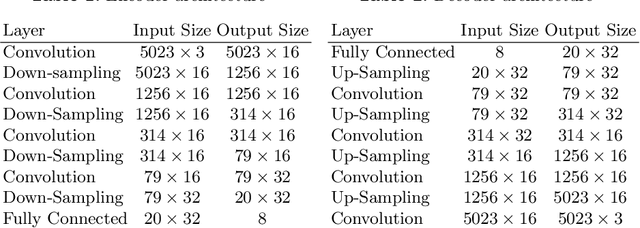

Learned 3D representations of human faces are useful for computer vision problems such as 3D face tracking and reconstruction from images, as well as graphics applications such as character generation and animation. Traditional models learn a latent representation of a face using linear subspaces or higher-order tensor generalizations. Due to this linearity, they can not capture extreme deformations and non-linear expressions. To address this, we introduce a versatile model that learns a non-linear representation of a face using spectral convolutions on a mesh surface. We introduce mesh sampling operations that enable a hierarchical mesh representation that captures non-linear variations in shape and expression at multiple scales within the model. In a variational setting, our model samples diverse realistic 3D faces from a multivariate Gaussian distribution. Our training data consists of 20,466 meshes of extreme expressions captured over 12 different subjects. Despite limited training data, our trained model outperforms state-of-the-art face models with 50% lower reconstruction error, while using 75% fewer parameters. We also show that, replacing the expression space of an existing state-of-the-art face model with our autoencoder, achieves a lower reconstruction error. Our data, model and code are available at http://github.com/anuragranj/coma