 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralFur: Animal Fur Reconstruction From Multi-View Images
Jan 18, 2026Reconstructing realistic animal fur geometry from images is a challenging task due to the fine-scale details, self-occlusion, and view-dependent appearance of fur. In contrast to human hairstyle reconstruction, there are also no datasets that can be leveraged to learn a fur prior for different animals. In this work, we present a first multi-view-based method for high-fidelity 3D fur modeling of animals using a strand-based representation, leveraging the general knowledge of a vision language model. Given multi-view RGB images, we first reconstruct a coarse surface geometry using traditional multi-view stereo techniques. We then use a vision language model (VLM) system to retrieve information about the realistic length structure of the fur for each part of the body. We use this knowledge to construct the animal's furless geometry and grow strands atop it. The fur reconstruction is supervised with both geometric and photometric losses computed from multi-view images. To mitigate orientation ambiguities stemming from the Gabor filters that are applied to the input images, we additionally utilize the VLM to guide the strands' growth direction and their relation to the gravity vector that we incorporate as a loss. With this new schema of using a VLM to guide 3D reconstruction from multi-view inputs, we show generalization across a variety of animals with different fur types. For additional results and code, please refer to https://neuralfur.is.tue.mpg.de.
BEDLAM2.0: Synthetic Humans and Cameras in Motion
Nov 18, 2025Inferring 3D human motion from video remains a challenging problem with many applications. While traditional methods estimate the human in image coordinates, many applications require human motion to be estimated in world coordinates. This is particularly challenging when there is both human and camera motion. Progress on this topic has been limited by the lack of rich video data with ground truth human and camera movement. We address this with BEDLAM2.0, a new dataset that goes beyond the popular BEDLAM dataset in important ways. In addition to introducing more diverse and realistic cameras and camera motions, BEDLAM2.0 increases diversity and realism of body shape, motions, clothing, hair, and 3D environments. Additionally, it adds shoes, which were missing in BEDLAM. BEDLAM has become a key resource for training 3D human pose and motion regressors today and we show that BEDLAM2.0 is significantly better, particularly for training methods that estimate humans in world coordinates. We compare state-of-the art methods trained on BEDLAM and BEDLAM2.0, and find that BEDLAM2.0 significantly improves accuracy over BEDLAM. For research purposes, we provide the rendered videos, ground truth body parameters, and camera motions. We also provide the 3D assets to which we have rights and links to those from third parties.
MAMMA: Markerless & Automatic Multi-Person Motion Action Capture
Jun 16, 2025We present MAMMA, a markerless motion-capture pipeline that accurately recovers SMPL-X parameters from multi-view video of two-person interaction sequences. Traditional motion-capture systems rely on physical markers. Although they offer high accuracy, their requirements of specialized hardware, manual marker placement, and extensive post-processing make them costly and time-consuming. Recent learning-based methods attempt to overcome these limitations, but most are designed for single-person capture, rely on sparse keypoints, or struggle with occlusions and physical interactions. In this work, we introduce a method that predicts dense 2D surface landmarks conditioned on segmentation masks, enabling person-specific correspondence estimation even under heavy occlusion. We employ a novel architecture that exploits learnable queries for each landmark. We demonstrate that our approach can handle complex person--person interaction and offers greater accuracy than existing methods. To train our network, we construct a large, synthetic multi-view dataset combining human motions from diverse sources, including extreme poses, hand motions, and close interactions. Our dataset yields high-variability synthetic sequences with rich body contact and occlusion, and includes SMPL-X ground-truth annotations with dense 2D landmarks. The result is a system capable of capturing human motion without the need for markers. Our approach offers competitive reconstruction quality compared to commercial marker-based motion-capture solutions, without the extensive manual cleanup. Finally, we address the absence of common benchmarks for dense-landmark prediction and markerless motion capture by introducing two evaluation settings built from real multi-view sequences. We will release our dataset, benchmark, method, training code, and pre-trained model weights for research purposes.
Generative Zoo
Dec 11, 2024
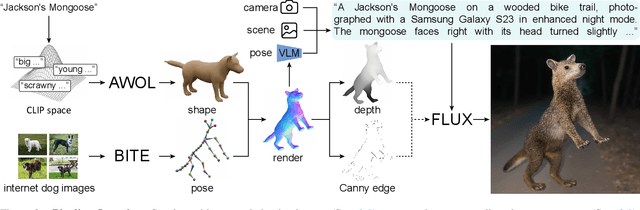

The model-based estimation of 3D animal pose and shape from images enables computational modeling of animal behavior. Training models for this purpose requires large amounts of labeled image data with precise pose and shape annotations. However, capturing such data requires the use of multi-view or marker-based motion-capture systems, which are impractical to adapt to wild animals in situ and impossible to scale across a comprehensive set of animal species. Some have attempted to address the challenge of procuring training data by pseudo-labeling individual real-world images through manual 2D annotation, followed by 3D-parameter optimization to those labels. While this approach may produce silhouette-aligned samples, the obtained pose and shape parameters are often implausible due to the ill-posed nature of the monocular fitting problem. Sidestepping real-world ambiguity, others have designed complex synthetic-data-generation pipelines leveraging video-game engines and collections of artist-designed 3D assets. Such engines yield perfect ground-truth annotations but are often lacking in visual realism and require considerable manual effort to adapt to new species or environments. Motivated by these shortcomings, we propose an alternative approach to synthetic-data generation: rendering with a conditional image-generation model. We introduce a pipeline that samples a diverse set of poses and shapes for a variety of mammalian quadrupeds and generates realistic images with corresponding ground-truth pose and shape parameters. To demonstrate the scalability of our approach, we introduce GenZoo, a synthetic dataset containing one million images of distinct subjects. We train a 3D pose and shape regressor on GenZoo, which achieves state-of-the-art performance on a real-world animal pose and shape estimation benchmark, despite being trained solely on synthetic data. https://genzoo.is.tue.mpg.de
Rhythm is a Dancer: Music-Driven Motion Synthesis with Global Structure
Nov 23, 2021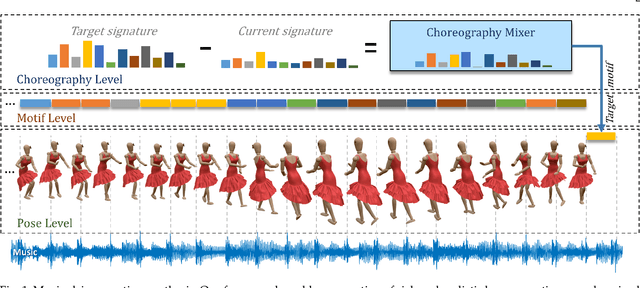
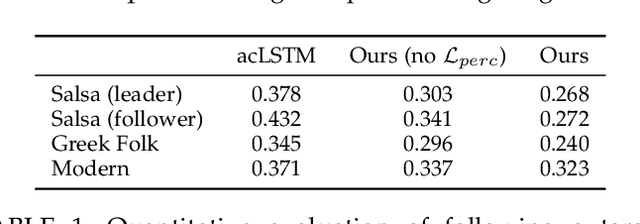
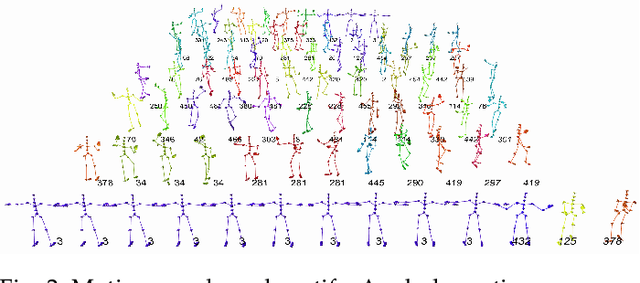
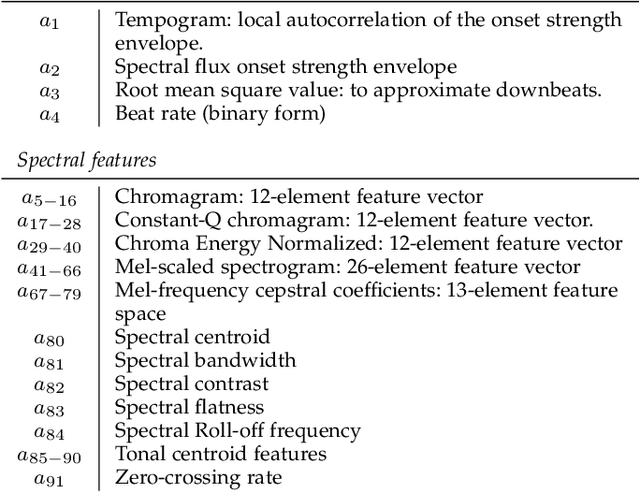
Synthesizing human motion with a global structure, such as a choreography, is a challenging task. Existing methods tend to concentrate on local smooth pose transitions and neglect the global context or the theme of the motion. In this work, we present a music-driven motion synthesis framework that generates long-term sequences of human motions which are synchronized with the input beats, and jointly form a global structure that respects a specific dance genre. In addition, our framework enables generation of diverse motions that are controlled by the content of the music, and not only by the beat. Our music-driven dance synthesis framework is a hierarchical system that consists of three levels: pose, motif, and choreography. The pose level consists of an LSTM component that generates temporally coherent sequences of poses. The motif level guides sets of consecutive poses to form a movement that belongs to a specific distribution using a novel motion perceptual-loss. And the choreography level selects the order of the performed movements and drives the system to follow the global structure of a dance genre. Our results demonstrate the effectiveness of our music-driven framework to generate natural and consistent movements on various dance types, having control over the content of the synthesized motions, and respecting the overall structure of the dance.